Chapter 8 Decision Trees
Tree-based methods employ a segmentation strategy that partitions the feature / predictor space into a series of decisions which has the added benefit of being easy to understand. Think of it as a flow chart for making decisions. The viewer of the chart is presented with a diagram that offers outcomes in response to (yes / no) questions (decisions) about important predictors found in the data set.
8.1 Advantages
The advantages of tree-based methods include that 1 - The model is generally easy to interpret - The path to a decision is plainly spelled out (assuming that the number of tree splits is easy enough to trace). - The method can handle numeric and categorical - One does not generally need to pre process or normalize data - Missing data is less of a big deal
Disadvantages include:
- Large trees are hard to follow - variance can be high
- Trees can be overly complex
- Overfitting can be a problem
8.2 A Classification Example
Let’s use the Pima Indians data set as it relates to predicting whether someone has diabetes. This data is provided by the mlbench package. The relevant variables are:
pregnant - Number of times pregnant
glucose - Plasma glucose concentration (glucose tolerance test)
pressure - Diastolic blood pressure (mm Hg)
triceps - Triceps skin fold thickness (mm)
insulin - 2-Hour serum insulin (mu U/ml)
mass - Body mass index (weight in kg/(height in m)\^2)
pedigree - Diabetes pedigree function
age - Age (years)
diabetes - Class variable (test for diabetes)library(mlbench)
data(PimaIndiansDiabetes)
pm <- PimaIndiansDiabetes
diabetes_mod_1 <- rpart(diabetes ~ .,pm,
method="class",cp=0.017)
rpart.plot(x = diabetes_mod_1)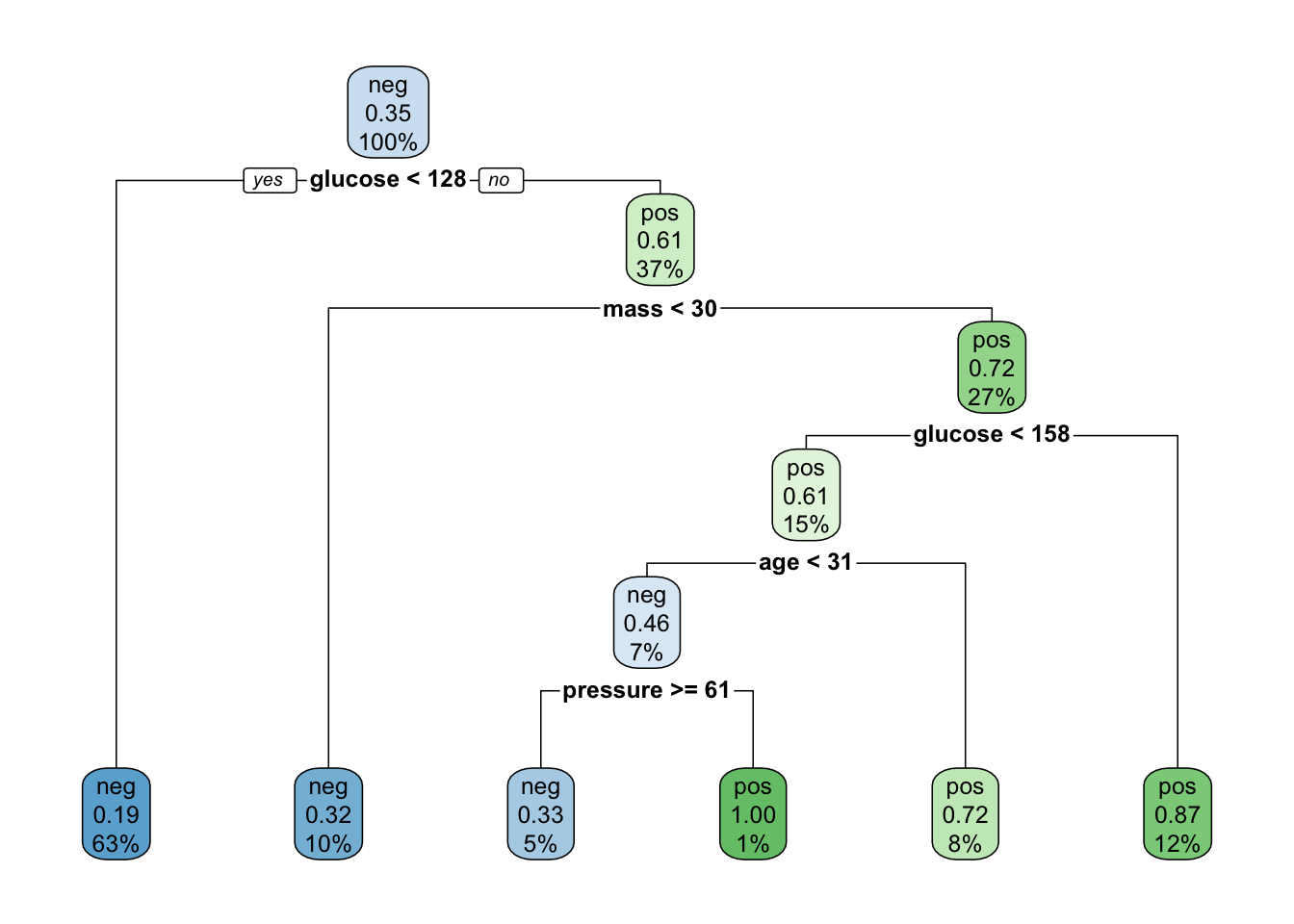
That’s pretty understandable and you could show this to someone and they would probably get it without too much explanation as long as they had an awareness of the features in the data set. The “node” at the top is called the “root node” and the lines are “branches” that go either to a “terminal node” or to “leaf nodes” which involve some comparison. It’s a flow chart for decisions about whether someone has diabetes or not. Note that there is also information about what percentages of “pos” or “neg” there are in each branch.
##
## diabetes_preds neg pos
## neg 470 131
## pos 30 137# Calculate the confusion matrix for the test set
caret::confusionMatrix(diabetes_preds,
pm$diabetes,
positive="pos") ## Confusion Matrix and Statistics
##
## Reference
## Prediction neg pos
## neg 470 131
## pos 30 137
##
## Accuracy : 0.7904
## 95% CI : (0.7598, 0.8186)
## No Information Rate : 0.651
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 0.4944
##
## Mcnemar's Test P-Value : 3.245e-15
##
## Sensitivity : 0.5112
## Specificity : 0.9400
## Pos Pred Value : 0.8204
## Neg Pred Value : 0.7820
## Prevalence : 0.3490
## Detection Rate : 0.1784
## Detection Prevalence : 0.2174
## Balanced Accuracy : 0.7256
##
## 'Positive' Class : pos
## Perhaps you noticed that in the example I included an argument called cp which corresponds to a “complexity parameter” which influences how the tree splits at various nodes. > The main role of this parameter is to save computing time by pruning off splits that are obviously not worthwhile. Essentially,the user informs the program that any split which does not improve the fit by cp will likely be pruned off by cross-validation, and that hence the program need not pursue it.
We’ll explore this in more detail momentarily. This is what is known as a “hyperparameter”.
8.3 Digging Deeper
Let’s create a training set that comprises 80% of the data with a holdout set of 20%.
set.seed(123)
percent <- .80
train_idx <- sample(1:nrow(pm),
round(percent*nrow(pm)))
train_idx[1:10]## [1] 415 463 179 526 195 118 299 229 244 14# Subset the pm data frame to training indices only
pm_train <- pm[train_idx, ]
# Exclude the training indices to create the test set
pm_test <- pm[-train_idx, ] # Train the model (to predict 'default')
pm_class_tree <- rpart(formula = diabetes ~ .,
data = pm_train,
method = "class")
# Look at the model output
pm_class_tree## n= 614
##
## node), split, n, loss, yval, (yprob)
## * denotes terminal node
##
## 1) root 614 216 neg (0.64820847 0.35179153)
## 2) glucose< 143.5 475 113 neg (0.76210526 0.23789474)
## 4) glucose< 103.5 187 17 neg (0.90909091 0.09090909) *
## 5) glucose>=103.5 288 96 neg (0.66666667 0.33333333)
## 10) mass< 26.9 72 7 neg (0.90277778 0.09722222) *
## 11) mass>=26.9 216 89 neg (0.58796296 0.41203704)
## 22) age< 30.5 119 34 neg (0.71428571 0.28571429)
## 44) pressure>=22 112 28 neg (0.75000000 0.25000000) *
## 45) pressure< 22 7 1 pos (0.14285714 0.85714286) *
## 23) age>=30.5 97 42 pos (0.43298969 0.56701031)
## 46) age>=56.5 9 2 neg (0.77777778 0.22222222) *
## 47) age< 56.5 88 35 pos (0.39772727 0.60227273)
## 94) pedigree< 0.201 11 3 neg (0.72727273 0.27272727) *
## 95) pedigree>=0.201 77 27 pos (0.35064935 0.64935065) *
## 3) glucose>=143.5 139 36 pos (0.25899281 0.74100719)
## 6) mass< 29.95 27 12 neg (0.55555556 0.44444444)
## 12) pressure>=74.5 9 1 neg (0.88888889 0.11111111) *
## 13) pressure< 74.5 18 7 pos (0.38888889 0.61111111) *
## 7) mass>=29.95 112 21 pos (0.18750000 0.81250000) *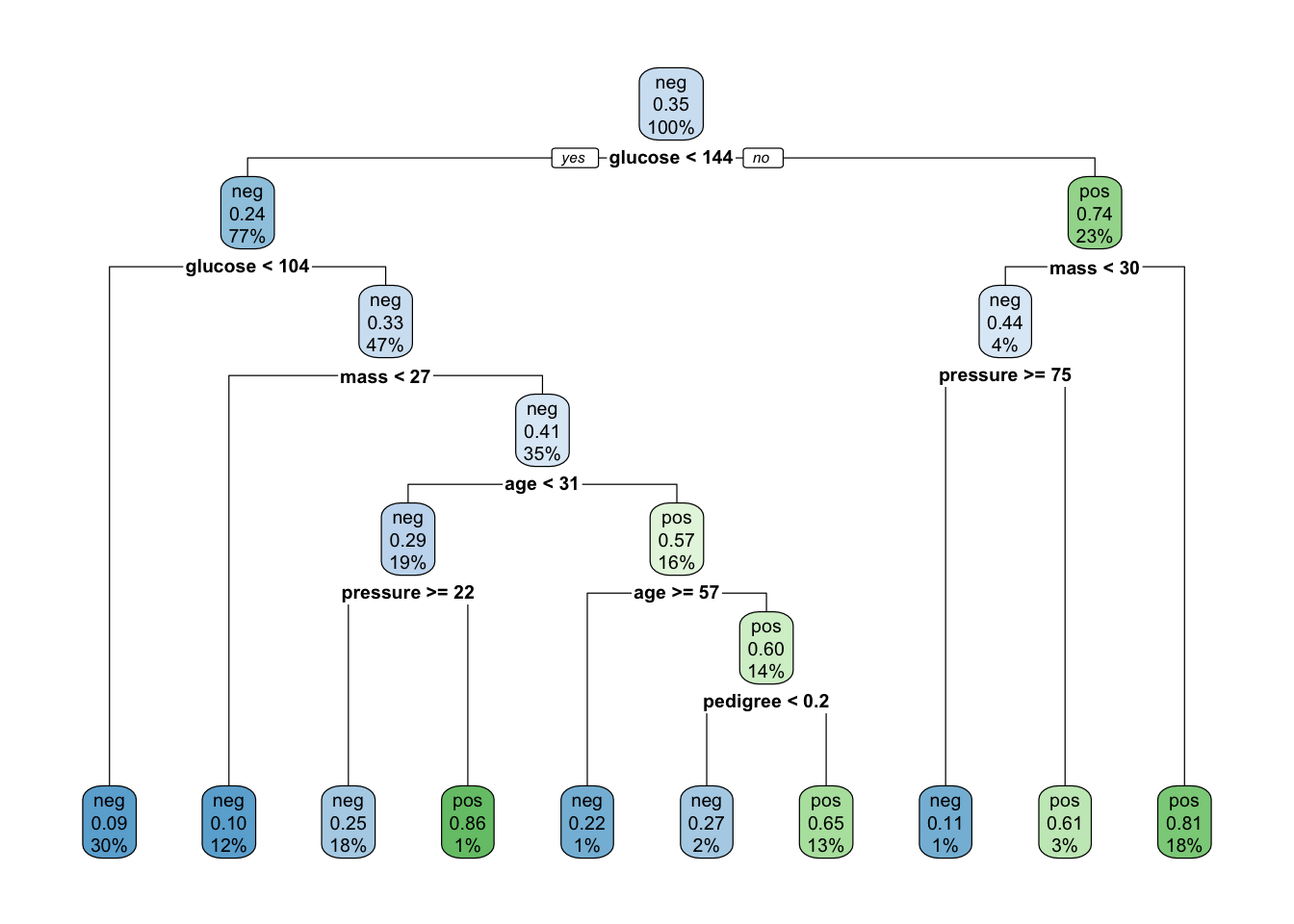
8.3.1 Evaluating performance
So this is where things get interesting. We’ll use a confusion matrix to help us figure some things out about this model.
# Generate predicted classes using the model object
pm_class_pred <- predict(object = pm_class_tree,
newdata = pm_test,
type = "class")
# Calculate the confusion matrix for the test set
caret::confusionMatrix(pm_class_pred,
pm_test$diabetes,
positive="pos") ## Confusion Matrix and Statistics
##
## Reference
## Prediction neg pos
## neg 79 20
## pos 23 32
##
## Accuracy : 0.7208
## 95% CI : (0.6429, 0.79)
## No Information Rate : 0.6623
## P-Value [Acc > NIR] : 0.07215
##
## Kappa : 0.3845
##
## Mcnemar's Test P-Value : 0.76037
##
## Sensitivity : 0.6154
## Specificity : 0.7745
## Pos Pred Value : 0.5818
## Neg Pred Value : 0.7980
## Prevalence : 0.3377
## Detection Rate : 0.2078
## Detection Prevalence : 0.3571
## Balanced Accuracy : 0.6949
##
## 'Positive' Class : pos
## We can also look at the Area Under the ROC Curve.
library(Metrics)
dt_pred <- predict(pm_class_tree,
newdata = pm_test, type="prob")
converted <- ifelse(pm_test$diabetes == "pos",1,0)
aucval <- Metrics::auc(actual = converted,
predicted = dt_pred[,2])
aucval## [1] 0.73915918.3.2 Tree Splitting
The resulting tree can be thought of as an upside down tree with the root at the top. The “trunk” proceeds downward and splits into subsets based on some decision (hence the word “decision” in the title). When classifying data the idea is to segment or partition data into groups/regions where each group contains or represents a single class (“yes/no”, “positive/negative”).
These groups or regions would represent a “pure” region. This is not always possible so a best effort is made. These regions are separated by decision boundaries which are used to make decisions. We’ll plot some example data to illustrate the case.
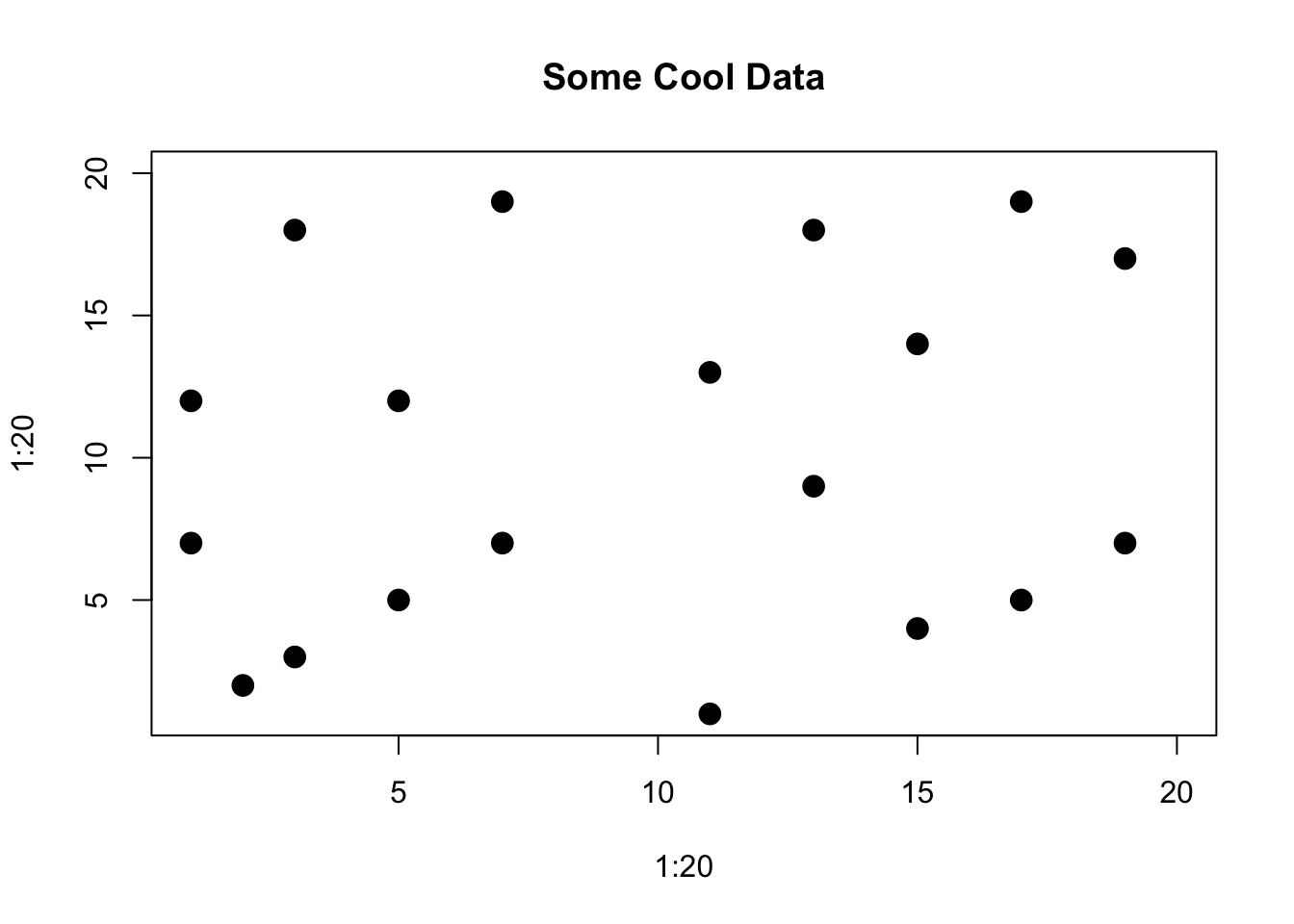
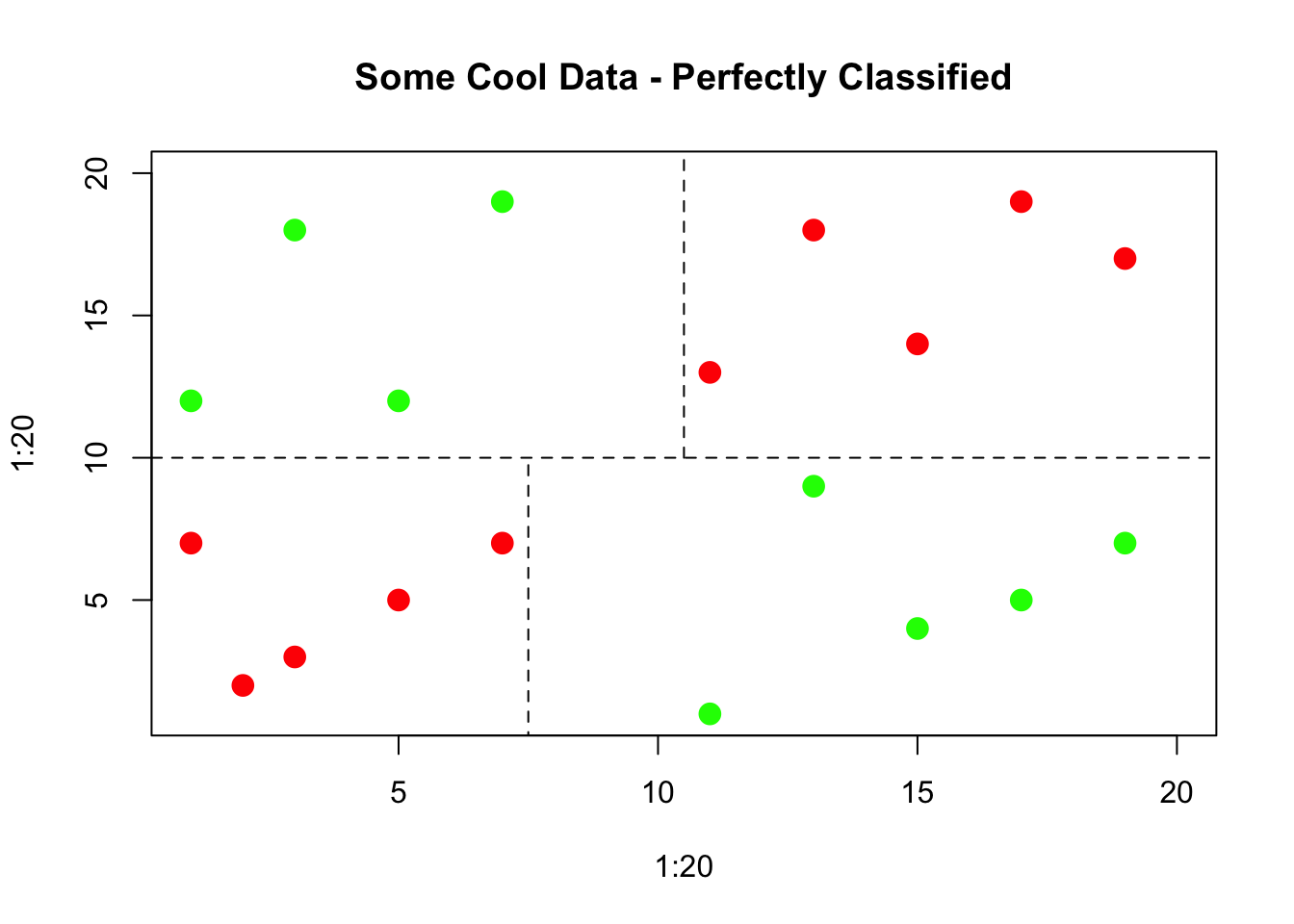
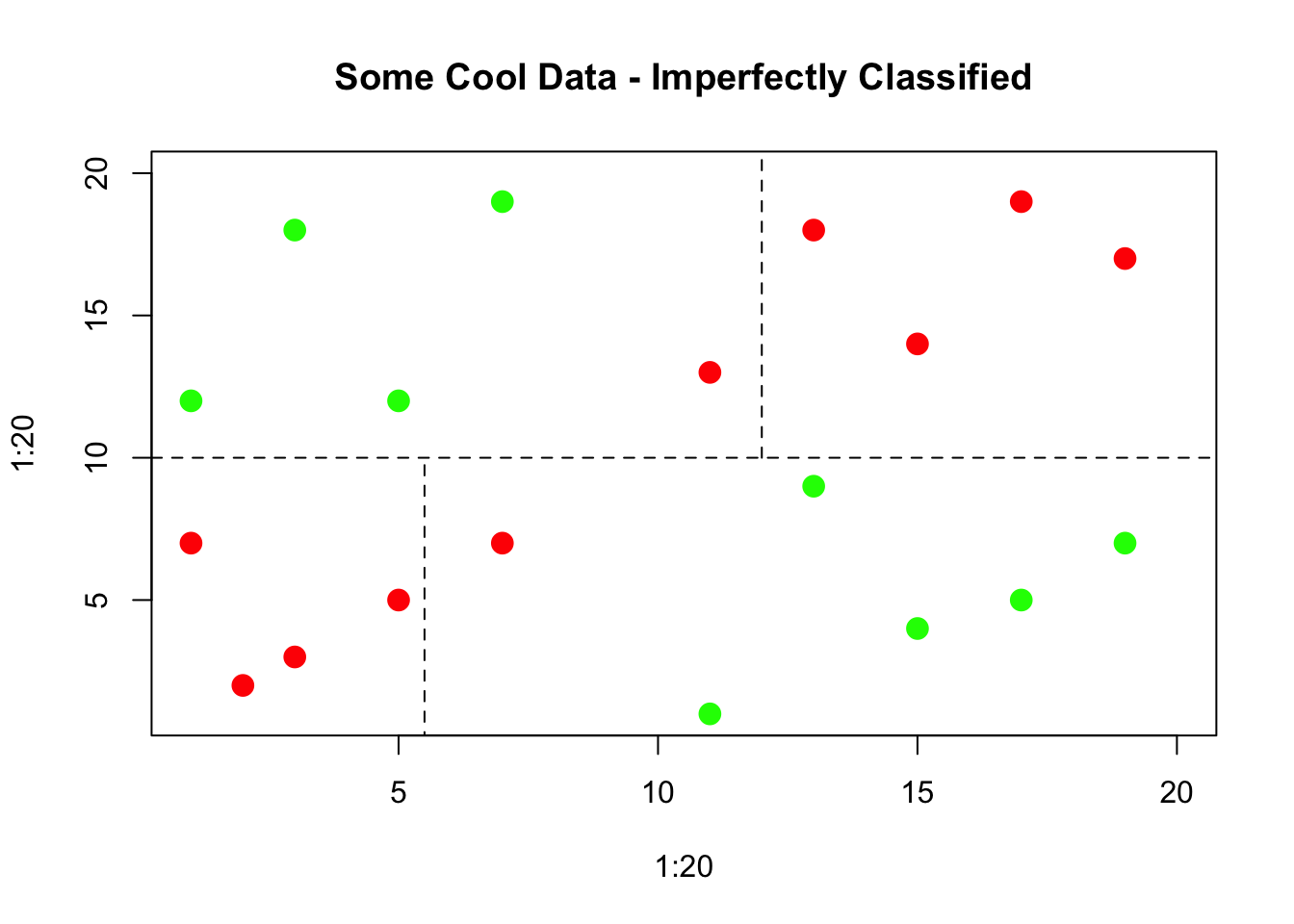
8.4 Gini Index
So we have to find a way to make the decisions such that the resulting regions are as pure as possible. This could be measuring the degree of impurity or purity - so we are either maximizing purity or minimizing impurity The so called “Gini index”" gives us the degree or measure of impurity.
The lower the Gini index, the lower the degree of impurity (this higher purity). The higher the Gini index the higher the degree of impurity (this lower purity). The decision tree will select the split that minimizes or lowers the Gini index. There are other measures or indices that can be used such as the “information” measure.
Let’s train two models that use a different splitting criterion (“gini” and “information”) and then use the test set to choose a “best” model. To do this you’ll use the parms argument of the rpart function. This argument takes a named list that contains values of different parameters to influence how the model is trained. Finally, to assess the models we’ll use the ce function from the Metrics package to show the proportion of elements in actual that are not equal to the corresponding element in predicted.
# Train a gini-based model
pm_gini_mod <- rpart(formula = diabetes ~ .,
data = pm_train,
method = "class",
parms = list(split = "gini"))
# Train an information-based model
pm_info_mod <- rpart(formula = diabetes ~ .,
data = pm_train,
method = "class",
parms = list(split = "information"))
# Create some predictions
gini_pred <- predict(object = pm_gini_mod,
newdata = pm_test,
type = "class")
# Generate predictions on the validation set using the information model
info_pred <- predict(object = pm_info_mod,
newdata = pm_test,
type = "class")
# Compare classification error
Metrics::ce(actual = pm_test$diabetes,
predicted = gini_pred)## [1] 0.2792208## [1] 0.25974038.5 Regression Trees
Predicting numeric outcomes can also be of interest. Given some patient characteristics relative to a disease, we might want to predict a viral load quantity. A gambler might want to predict a final score for a team. Unlike, classification problems, we are looking at estimating a numeric outcome. R has a built in function for this called “lm” which can be used but we can also use Trees to do this since, after, all, it does some nice things for us like not having to worry about normalizing data (not that that is hard) or the mixture of quantitative and categorical data.
8.5.1 Performance Measure
Since we are predicting a numeric outcome we would like to come up with a metric to help us figure out if the model we have is good or not. With classification situations we can employ confusion matrices and ROC curves. Here we will use something more simplistic but effective - Root Mean Square Error. The formula looks like the following where P represents a vector of predictions and O represents a vector of the observed (true) values.
\[ RMSE = \sqrt\frac{\sum_i^n(P_i-O_i)^2}{n} \]
We could even write our own function for this although the Metrics package has a function called rmse to do this. Let’s build a classification tree model on the Pima Indians data to predict the body mass of a participant.
# Train the model
mass_pima_mod <- rpart(formula = mass ~ .,
data = pm_train,
method = "anova")
# Look at the model output
print(mass_pima_mod)## n= 614
##
## node), split, n, deviance, yval
## * denotes terminal node
##
## 1) root 614 36909.6400 31.96971
## 2) triceps< 30.5 422 21954.9400 29.74147
## 4) diabetes=neg 293 13608.7800 28.26007
## 8) pressure< 45 20 2689.8690 21.19500
## 16) age< 27 12 1622.3870 16.16667 *
## 17) age>=27 8 308.9587 28.73750 *
## 9) pressure>=45 273 9847.4740 28.77766
## 18) triceps< 22.5 190 6889.5350 27.84947 *
## 19) triceps>=22.5 83 2419.5400 30.90241 *
## 5) diabetes=pos 129 6242.6950 33.10620
## 10) glucose< 125.5 47 3036.8640 30.57660
## 20) pregnant>=5.5 19 1699.6170 26.62632 *
## 21) pregnant< 5.5 28 839.5686 33.25714 *
## 11) glucose>=125.5 82 2732.7020 34.55610 *
## 3) triceps>=30.5 192 8254.2630 36.86719
## 6) pregnant>=1.5 128 4020.7590 35.12813
## 12) triceps< 35.5 64 2192.8970 33.11406 *
## 13) triceps>=35.5 64 1308.6360 37.14219 *
## 7) pregnant< 1.5 64 3072.1590 40.34531
## 14) glucose< 128.5 38 1014.3150 38.05000 *
## 15) glucose>=128.5 26 1565.0400 43.70000
## 30) pressure< 75 10 122.8810 38.67000 *
## 31) pressure>=75 16 1031.0190 46.84375 *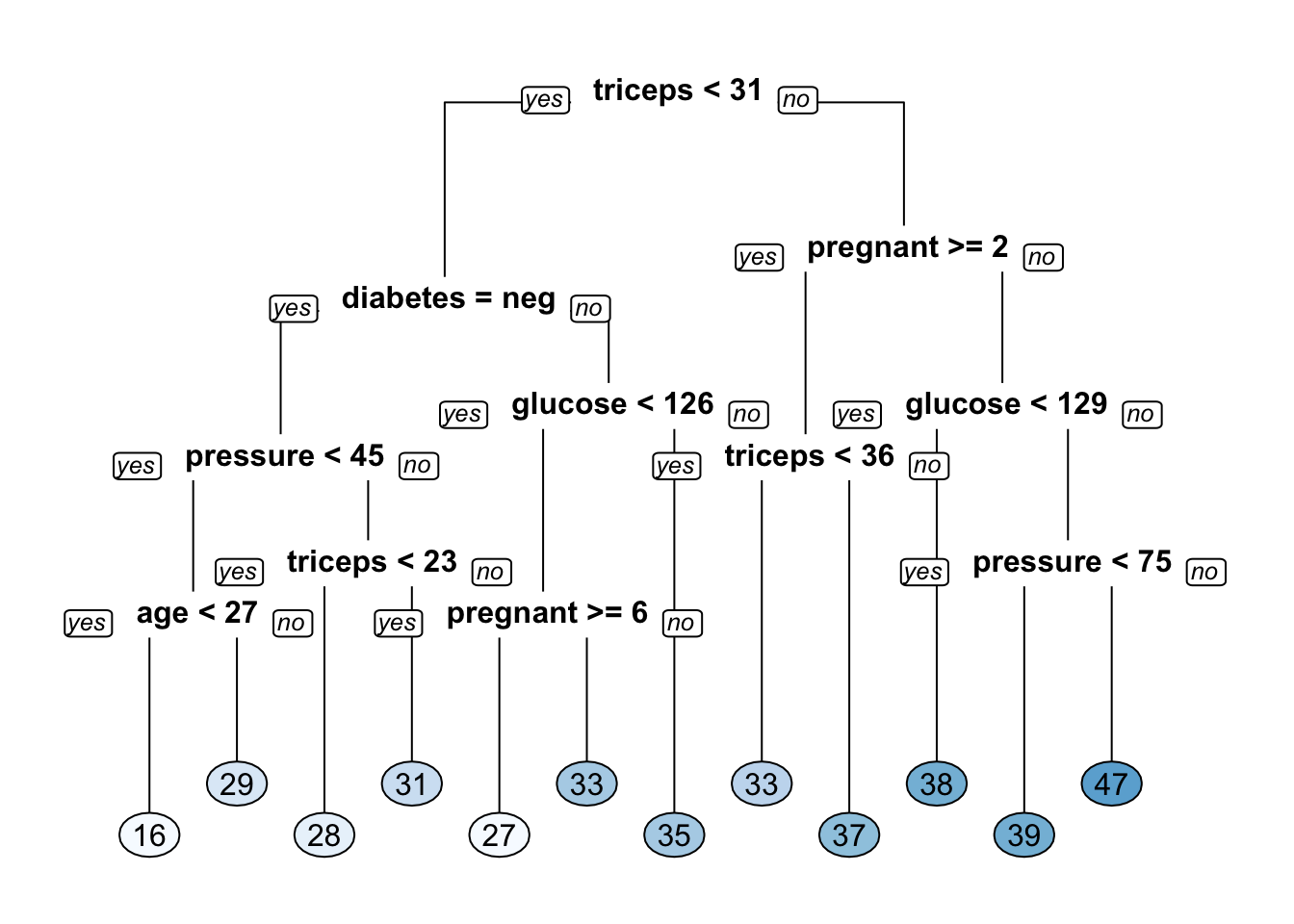
Let’s compute the RMSE for this model.
# Generate predictions on a test set
pred <- predict(object = mass_pima_mod, # model object
newdata = pm_test) # test dataset
# Compute the RMSE
Metrics::rmse(actual = pm_test$mass,
predicted = pred)## [1] 6.627414Is this Good ? Bad ? Okay ? We don’t know. We’ll need to do some things like Cross Validation. And then there are additional arguments to the rpart function that we could use to influence how the model does its job. These are referred to as “hyperparamters”.
8.6 Parameters vs Hyperparameters
Model parameters are things that are generated as part of the modeling process. These might be things like slope and intercept from a linear model or, in the case of an rpart model, the number of splits in the final tree or the total number of leaves.
Hyper parameters (sometimes called metaparameters) represent information that is supplied in the form of an argument prior the call to the method to generate results. These parameters might not be something one can intelligently set without some experimentation.
Of course, most modeling functions one would call in R have default values for various arguments but this does not mean that the defaults are appropriate for all cases. To see the hyper parameters of the rpart function, check the help page for rpart.control.

Tuning the hyperparameters for rpart would involve adjusting the following hyper parameters or using some post processing function to refine the model relative to these parameters:
- cp which is the complexity parameter (default is .01) - smaller values means more complexity
- minsplit the minimum number of observations that must exist in a node before a split is attempted (default is 20)
- maxdepth maximum number of nodes between a final node and root node
There are other hyper parameters but we can start with these. The rpart.control function will do something called cross validation which involves repeatedly running the rpart some number of times (10 by default) while internally specifying different values for the above mentioned hyper parameters.
In effect, it is doing some work for you so you don’t have to. At the end of the run it will produce a table for inspection. The results of this table can then be used to “prune” the tree model to get a “better” tree - one that performs better than an “un pruned” tree. Let’s look at the pima mass model:
## CP nsplit rel error xerror xstd
## 1 0.18153603 0 1.0000000 1.0015656 0.09381646
## 2 0.05698963 1 0.8184640 0.8447727 0.08092338
## 3 0.03146457 2 0.7614743 0.8067354 0.07952153
## 4 0.02902872 3 0.7300098 0.7901790 0.07936648
## 5 0.02055084 4 0.7009810 0.7721064 0.07632954
## 6 0.01458696 5 0.6804302 0.7798124 0.07806591
## 7 0.01406747 6 0.6658432 0.8012778 0.07730342
## 8 0.01335162 7 0.6517758 0.7928406 0.07622939
## 9 0.01315114 8 0.6384242 0.7932476 0.07707739
## 10 0.01113909 10 0.6121219 0.8022725 0.07716219
## 11 0.01000000 11 0.6009828 0.8042465 0.07301588We want to pick the value of CP from the table that corresponds to the minimum xerror value. This can also be deduced from the plot but let’s work with the table:
We’ll use the CP value associated with the minimum error which in this case turns out to be 0.01. This is now passed to the prune function.
mass_pima_mod_opt <- prune(mass_pima_mod,
cp = cpt_val)
# Plot the optimized model
rpart.plot(mass_pima_mod_opt, yesno = 2, type = 0, extra = 0)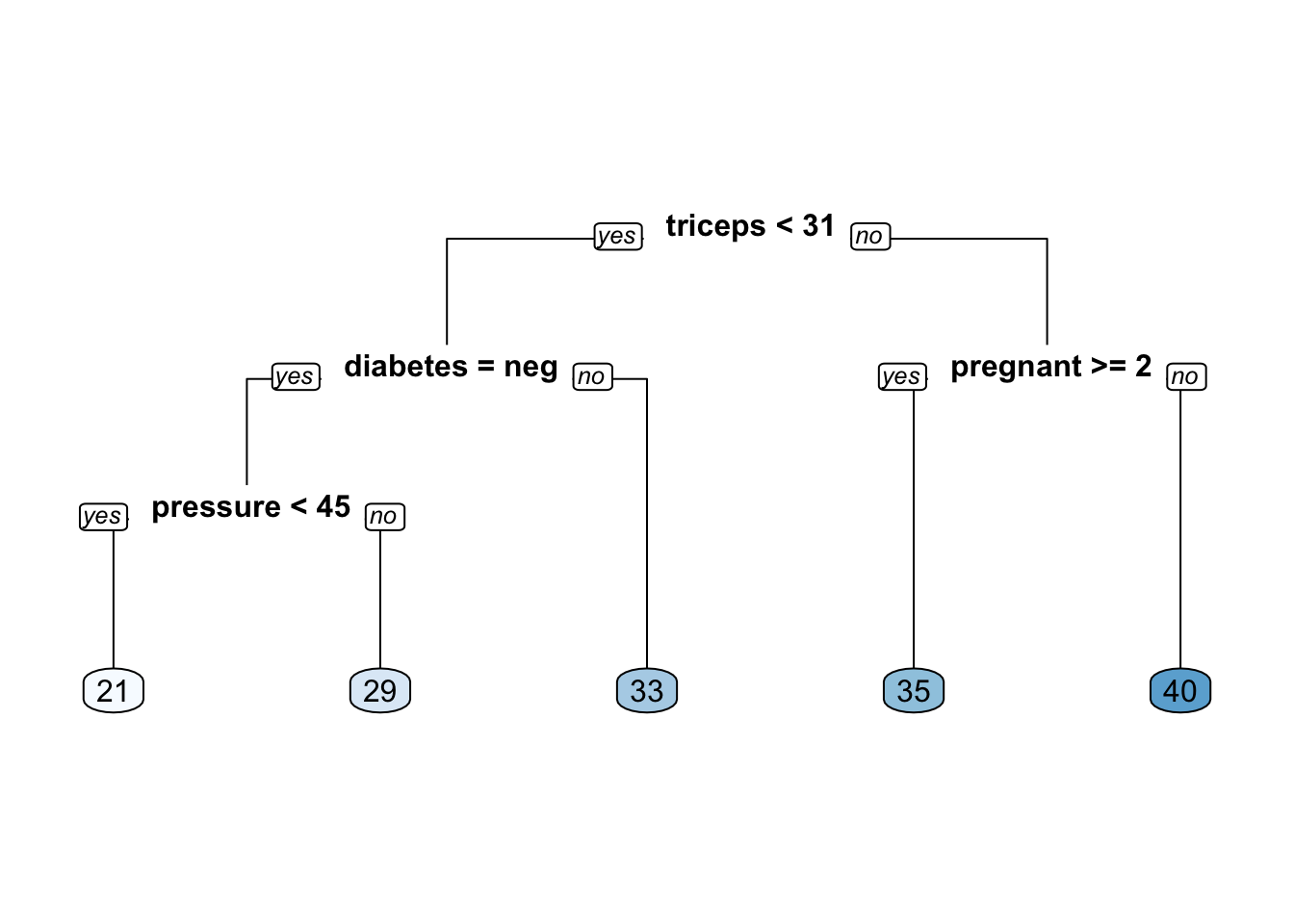
Does this optimized model perform any better ? Not really, because the optimal CP value turned out to be 0.01 which is actually the same as the default.
# Generate predictions on a test set
pred <- predict(object = mass_pima_mod_opt, # model object
newdata = pm_test) # test dataset
# Compute the RMSE
Metrics::rmse(actual = pm_test$mass,
predicted = pred)## [1] 6.7909438.7 Grid Searching
We might want to review several different models that correspond to various hyperparamter sets. Our goal is to find the best performing model based on a systematic approach that allows us to assess each model in a fair way. There are functions that can help us build a “grid” of hyperparameter values that can then “feed” the function arguments. So we train models on a combination of these values and compare them using the RMSE for regression or ROC / Confusion Matrix for classification setups.
Setting up the grid involves a manual process (although as we will eventually see) the caret package can help automate this for us. Knowing about the valid values for a hyperparameter is critical so some experimentation is important. The following process sets up a data frame of two columns each of which corresponds to a hyperparamter of the rpart function. The intent here is to call rpart a number of times using each row of the below data frame to supply the values for the respective arguments in rpart.
mysplits <- seq(1, 35, 5)
mydepths <- seq(5,40, 10)
my_cool_grid <- expand.grid(minsplit = mysplits,
maxdepth = mydepths)
head(my_cool_grid)## minsplit maxdepth
## 1 1 5
## 2 6 5
## 3 11 5
## 4 16 5
## 5 21 5
## 6 26 5We’ll generate models, predictions, and RMSE values and stash them for later review. Once again, we’ll be predicting the mass variable in the Pima Indians data frame.
do_grid_search <- function(minsplit,maxdepth) {
# Setup some book keeping structures
mods <- list()
preds <- list()
myrmse <- vector()
mygrid <- expand.grid(minsplit=minsplit,
maxdepth=maxdepth)
for (ii in 1:nrow(mygrid)) {
minsplit <- mygrid[ii,]$minsplit
maxdepth <- mygrid[ii,]$maxdepth
# Build the Model
mods[[ii]] <- rpart(mass ~ .,
data = pm_train,
method = "anova",
minsplit = minsplit,
maxdepth = maxdepth)
# Now predict against the test data
preds[[ii]] <- predict(mods[[ii]],
newdata = pm_test)
# Get RMSE
myrmse[ii] <- Metrics::rmse(actual = pm_test$mass,
predicted = preds[[ii]])
}
# Find the model that has the lowest rmse
idx <- which.min(myrmse)
# Get the control parameters for the best model
optimal_model <- mods[[idx]]
rmseval <- myrmse[idx]
return(list(optimal_model=optimal_model,optim_rmse=rmseval))
}Now run the function and get the parameters corresponding to the optimal model.
## [1] 6.851048## $minsplit
## [1] 2
##
## $minbucket
## [1] 1
##
## $cp
## [1] 0.01
##
## $maxcompete
## [1] 4
##
## $maxsurrogate
## [1] 5
##
## $usesurrogate
## [1] 2
##
## $surrogatestyle
## [1] 0
##
## $maxdepth
## [1] 4
##
## $xval
## [1] 108.8 Bagged Trees
Now we look at bagged trees which involves looking at many trees in aggregate - this is an ensemble method. It helps to reduce the variance associated with a single decision tree which can be highly sensitive to changes in data. The term bagging refers to “bootstrap aggregation”. To review, the Decision Tree process can be represented like this:
The bootstrap method of sampling will resample the training data some number of times (with replacement) and retrain a number of models on the resampled data to average out the error. This looks something like:
- The input data set is resampled with replacement some number of times (e.g. 10,50, 100)
- The resampled data is usually a subset of the data which leaves some portion of the data available to use a mini test set for prediction (“out of bag data”")
- Get the RMSE from the prediction
- Average out the RMSE
So you get a lot of different trees whose performance can be averaged over boostrapped data sets which might include observations several times or not at all. This should result in less variance. A reason NOT to use bagged trees involves the idea that a collection of trees is not nearly as easy to look at as a single decision tree. We can actually write our own version of bagged trees using a for loop. Sort of like what we did above. First, let’s get our test / train pair for the Pima Indians data.
set.seed(123)
percent <- .80
train_idx <- sample(1:nrow(pm),
round(percent*nrow(pm)))
train_idx[1:10]## [1] 415 463 179 526 195 118 299 229 244 14# Subset the pm data frame to training indices only
pm_train <- pm[train_idx, ]
# Exclude the training indices to create the test set
pm_test <- pm[-train_idx, ] Next, well create 50 different trees based on 50 bootstrapped samples of the training data. We will sample WITH replacement. This means that some of the rows from the data will be repeated and some will be left out all together. We can figure out what rows were not included and use them to create a test set referred to as “out of bag” samples.
training_boot_idx <- sample(1:nrow(pm),replace=TRUE)
test_boot_idx <- !(1:32 %in% training_boot_idx)Let’s start looping
library(Metrics)
modl <- list()
predl <- list()
aucval <- vector()
acc <- vector()
number_of_boostraps <- 50
for (ii in 1:number_of_boostraps) {
training_boot_idx <- sample(1:nrow(pm),replace=TRUE)
test_boot_idx <- !(1:32 %in% training_boot_idx)
modl[[ii]] <- rpart(diabetes ~ .,
data = pm[training_boot_idx,],
method = "class"
)
# This list will contain / hold the models build on the bootstrap
predl[[ii]] <- predict(modl[[ii]],
newdata=pm[test_boot_idx,],
type="prob")
converted <- ifelse(pm[test_boot_idx,]$diabetes == "pos",1,0)
# Let's create an estimate of the AUC
aucval[ii] <- Metrics::auc(actual = converted,
predicted = predl[[ii]][,2])
}Now check all of the accuracy estimates and then average them. Remember this is supposed to help us to better estimate the out of sample error.
## [1] 0.8217163Now we’ll compare this to the function called “bagging” from the ipred package which does bagged trees directly.
library(ipred)
bagged_pm <- bagging(diabetes ~ .,
data = pm_train, coob = TRUE)
bagged_pred <- predict(bagged_pm,
newdata = pm_test, type="prob")converted <- ifelse(pm_test$diabetes == "pos",1,0)
aucval <- Metrics::auc(actual = converted,
predicted = bagged_pred[,2])
aucval## [1] 0.8312594This is better than the 0.7804305 we got when using a single Decision tree. Single decision trees are sometimes called “weak learners” because
8.9 Random Forests
In bagging, all features are used when considering if and when to split. However, with the Random Forest approach, a subset of features are selected at random at each split in a decision tree. You could think of random forests as being an extension of Bagged Trees. Typically they are also an improvement. As with other tree methods, we don’t have to worry a lot about preprocessing the data although we could if we wanted to. Basically, one of the main advantages of tree methods is that it tolerates a combination of data types on different scales which makes it good as a “go to” method for beginners.
Random forests will sample some number of features when considering a split. This can be influenced by a hyperparameter called mtry which is limited to the number of features in the data set.
# Train a Random Forest
set.seed(1) # for reproducibility
pm_rf_model <- randomForest(formula = diabetes ~ .,
data = pm_train)
# Print the model output
print(pm_rf_model)##
## Call:
## randomForest(formula = diabetes ~ ., data = pm_train)
## Type of random forest: classification
## Number of trees: 500
## No. of variables tried at each split: 2
##
## OOB estimate of error rate: 25.57%
## Confusion matrix:
## neg pos class.error
## neg 336 62 0.1557789
## pos 95 121 0.4398148Let’s look at the out of bag error matrix
## OOB neg pos
## [1,] 0.3274336 0.2816901 0.4047619
## [2,] 0.3185596 0.2533333 0.4264706
## [3,] 0.2979684 0.2127660 0.4472050
## [4,] 0.2862903 0.2012579 0.4382022
## [5,] 0.2987013 0.2144928 0.4484536
## [6,] 0.2929825 0.1934605 0.4729064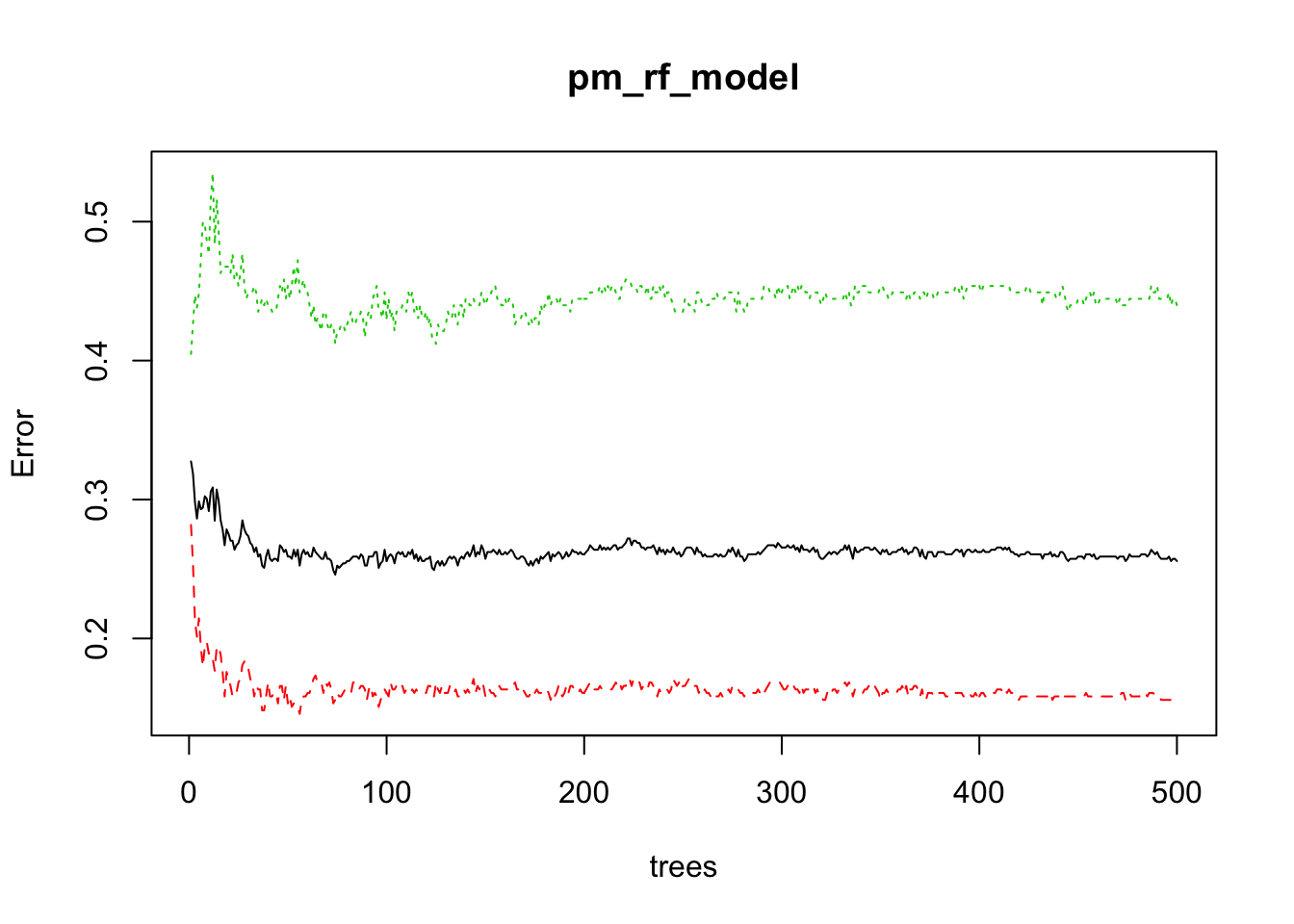
Do some predictions with this model.
rf_pred <- predict(pm_rf_model,
newdata = pm_test, type="prob")
converted <- ifelse(pm_test$diabetes == "pos",1,0)
aucval <- Metrics::auc(actual = converted,
predicted = rf_pred[,2])
aucval## [1] 0.8453054A slight improvement over the bagged trees.
8.10 Boosted Trees
We’ll finish off this section with a discussion on boosted trees which represents an extension to random forests. Here is how we have been progressing thus far:
- Single Decision Tree
- Bagged Decision Trees (Aggregated Trees using all features)
- Random Forests (Many Trees using a number of of sampled features)
Methods 2 and 3 will use bootstrap sampling on the input data which means there will be sampling with replacement to generate a training set. After a tree is built then it will be applied to the OOB (Out Of Band) data left over from the bootstrap sample. This will then be used in the computation of an average.
With boosting, we don’t try to keep up with the idea of reducing the variance emerging from a number of individual trees (aka “learners”). Nor do we consider each tree as being independent and later try to integrate it into an average tree. With boosting we create a sequence of trees such that any subsequent tree represents an improvement on the previous tree(s) thus there is some dependency in the interest of improvement.
The process attempts to learn from previous “mistakes” in the creation of down stream trees. Boosting looks at the residuals from a tree and pays attention to any problematic observations when creating a subsequent tree. Here is an example. We’ll need to do a bit more prep on the data though prior to use:
We had to turn the “pos” / “neg” values into, respectively, 1 and 0. The gbm function requires this for classification problems.
library(gbm)
pm_boost <- gbm(diabetes ~ . ,
distribution="bernoulli",
data = prep_pm_train,n.trees=1000)
summary(pm_boost)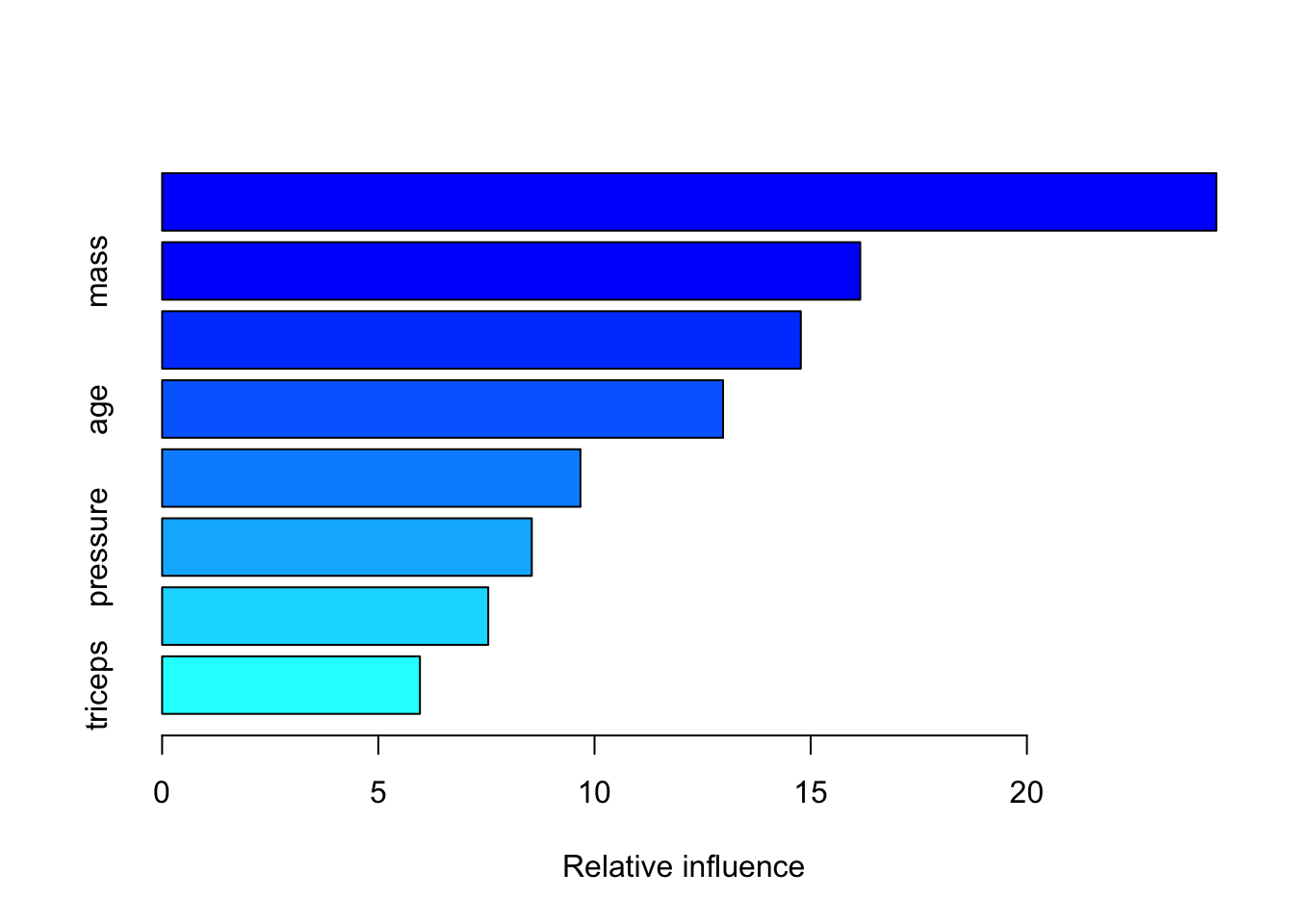
## var rel.inf
## glucose glucose 24.381141
## mass mass 16.145442
## pedigree pedigree 14.771739
## age age 12.973055
## insulin insulin 9.674303
## pressure pressure 8.549152
## pregnant pregnant 7.542437
## triceps triceps 5.962731boost_pred <- predict(pm_boost,
newdata = pm_test,
type="response",
n.trees=50)
converted <- ifelse(pm_test$diabetes == "pos",1,0)
aucval <- Metrics::auc(actual = converted,
predicted = boost_pred)
aucval## [1] 0.8378582Of course, we can use the caret package to knit these altogether into one framework that dispenses wit the need to understand the details of each method although it is important for you to see examples of standalone functions since 1) it can help your understanding of the method and 2) in languages such as Python there is no equivalent to caret.
8.11 Using caret
We looked at individual methods including rpart, bagging, random forests, and boosted trees. Each of these had its own approach and hyperparameters. With caret we can do basically plugin methods.
control <- trainControl(method="cv",
number=10,
summaryFunction = twoClassSummary,
classProbs = TRUE,
savePredictions = TRUE,
verboseIter = FALSE)
rpart_caret <- train(diabetes ~ .,
data = pm_test,
method = "rpart",
metric = "ROC",
trControl = control)
rpart_caret## CART
##
## 154 samples
## 8 predictor
## 2 classes: 'neg', 'pos'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold)
## Summary of sample sizes: 139, 138, 139, 139, 139, 137, ...
## Resampling results across tuning parameters:
##
## cp ROC Sens Spec
## 0.02884615 0.6598333 0.8027273 0.4166667
## 0.04807692 0.6637424 0.8027273 0.4600000
## 0.17307692 0.5006364 0.8518182 0.1600000
##
## ROC was used to select the optimal model using the largest value.
## The final value used for the model was cp = 0.04807692.Next, we try out the bagging approach
bagging_caret <- train(diabetes ~ .,
data = pm_test,
method = "treebag",
metric = "ROC",
trControl = control)
bagging_caret## Bagged CART
##
## 154 samples
## 8 predictor
## 2 classes: 'neg', 'pos'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold)
## Summary of sample sizes: 139, 138, 137, 138, 139, 139, ...
## Resampling results:
##
## ROC Sens Spec
## 0.7810152 0.8336364 0.5566667Next we try out the random forest function
rf_caret <- train(diabetes ~ .,
data = pm_test,
method = "rf",
metric = "ROC",
trControl = control)
rf_caret## Random Forest
##
## 154 samples
## 8 predictor
## 2 classes: 'neg', 'pos'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold)
## Summary of sample sizes: 138, 139, 138, 139, 138, 139, ...
## Resampling results across tuning parameters:
##
## mtry ROC Sens Spec
## 2 0.8137576 0.8636364 0.5500000
## 5 0.8098939 0.8527273 0.5533333
## 8 0.7989091 0.8527273 0.5333333
##
## ROC was used to select the optimal model using the largest value.
## The final value used for the model was mtry = 2.And finally, the boosted approach:
boosted_caret <- train(diabetes ~ .,
data = pm_test,
method = "gbm",
metric = "ROC",
verbose = FALSE,
tuneLength = 10,
trControl = control)Let’s look at how they all performed:
## Results for Rpart## cp ROC Sens Spec ROCSD SensSD SpecSD
## 1 0.02884615 0.6598333 0.8027273 0.4166667 0.1334386 0.09554349 0.2206892## Results for Bagging## parameter ROC Sens Spec ROCSD SensSD SpecSD
## 1 none 0.7810152 0.8336364 0.5566667 0.09758653 0.07879371 0.2096735## Results for Random Forest## mtry ROC Sens Spec ROCSD SensSD SpecSD
## 1 2 0.8137576 0.8636364 0.55 0.1457962 0.1036523 0.2389535## Results for Boosted Trees## shrinkage interaction.depth n.minobsinnode n.trees ROC Sens Spec
## 1 0.1 1 10 50 0.799 0.8445455 0.5333333
## ROCSD SensSD SpecSD
## 1 0.106574 0.109967 0.2591534