Chapter 9 Comparing Different Methods
We could look at random forests to see how they perfom. It also provides an opportunity to introduce the concept of hyperparameters which are important to consider since many ML methods will use them. Many people are surprised to learn that random Forests (or even a single Decision Tree) can be used to predict a numeric outcome, but they can be. The advantages of using random Forests include the following:
- easy to use
- resistant to overfitting
- accurate use for non linear models
- can be used to predict numeric or binary outcomes Some problems include:
- the rf function requires setting hyperparameters
- adjustment of hyperparameters can be specific to the data set
- default vlaues will requie adjustment or "tuning"Random Forests are a generalization, and frequently an improvement, over a single decsion tree although a single decision tree is usually more intuitive and easier to inperpret. As an example, let’s use the rpart function to predict the mpg variable from the mtcars data frame:
9.1 A Single Decision Tree
library(rpart)
library(rpart.plot)
#
set.seed(123)
my_small_tree <- rpart(mpg~.,data=mtcars)
my_small_tree## n= 32
##
## node), split, n, deviance, yval
## * denotes terminal node
##
## 1) root 32 1126.04700 20.09062
## 2) cyl>=5 21 198.47240 16.64762
## 4) hp>=192.5 7 28.82857 13.41429 *
## 5) hp< 192.5 14 59.87214 18.26429 *
## 3) cyl< 5 11 203.38550 26.66364 *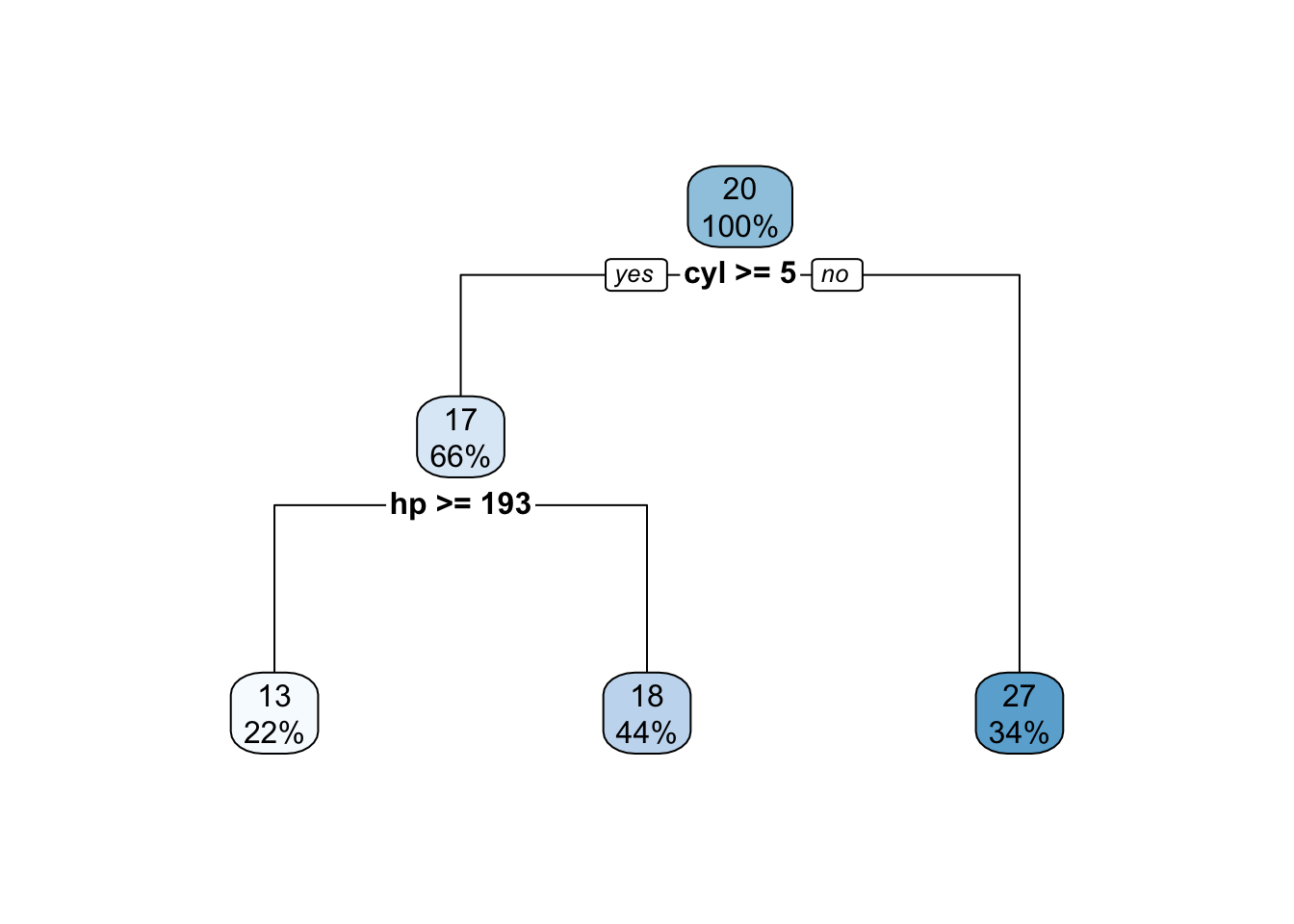
Pretty basic and easy to use to get predictions and compute an RMSE.
tree_preds <- predict(my_small_tree, mtcars)
Metrics::rmse(actual= mtcars$mpg, predicted = tree_preds)## [1] 3.021207Using a single tree, though easy to understand, can be improvded upon by looking at multiple trees on the same data. Better yet, maybe sample some number of the features, especially the more important ones, and then somehow combine the trees to product an aggregate or “bagged” tree to get a better model - at least that is the goal. So we can use a function such as randomForest to do this. In this case, the performance of the RMSE is better.
library(randomForest)
set.seed(123)
mpg_rf <- randomForest(mpg~.,data=mtcars)
#
tree_preds <- predict(mpg_rf, mtcars)
Metrics::rmse(actual= mtcars$mpg, predicted = tree_preds)## [1] 1.209968The way bagged trees work is to use bootstrap sampling to look at different versions of the input for each tree that it makes. The number of trees to make is specified before running the function. Since the sampling is bootstrap-based, some of the rows from the input will be duplicated perhaps more than once whereas other rows will not be involved at all in the training. These are commonly known as Out of Bag samples. After a give tree is formed it is then used to predict performance on the OOB samples to arrive at an OOB error.
# This generates row numbers for indexing into the mtcars data frame
tre_samp <- sample(1:nrow(mtcars),replace=TRUE)
#
in_samp <- mtcars[tre_samp,]
sum(duplicated(in_samp))## [1] 11# The indices corresponding to the Out of Band rows would be
out_of_bag <- mtcars[-tre_samp,]
head(out_of_bag)## mpg cyl disp hp drat wt qsec vs am gear carb
## Hornet Sportabout 18.7 8 360.0 175 3.15 3.44 17.02 0 0 3 2
## Valiant 18.1 6 225.0 105 2.76 3.46 20.22 1 0 3 1
## Duster 360 14.3 8 360.0 245 3.21 3.57 15.84 0 0 3 4
## Merc 230 22.8 4 140.8 95 3.92 3.15 22.90 1 0 4 2
## Merc 280 19.2 6 167.6 123 3.92 3.44 18.30 1 0 4 4
## Merc 450SL 17.3 8 275.8 180 3.07 3.73 17.60 0 0 3 3We could extend this concept by plotting the “out of band” error using the “out of band” dataset associated with each tree. Remember, for each tree, we sample the input data WITH replacement which menas that some of the rows in the data frame will be left which are used to create the OOB “test” set. We can then do a prediction on this data set and compute, for example, an AUC to approximate the out of band error.
myl <- data.frame()
# We'll build a series of trees from 10 - 1000 in increments of 10
trees <- seq(10,1000,10)
for (ii in 1:length(trees)) {
model <- randomForest(diabetes ~ .,
data = PimaIndiansDiabetes,
ntree=trees[ii],keep.inbag=TRUE)
#
preds <- predict(model, PimaIndiansDiabetes, type="prob")
preds <- apply(preds,1,max)
auc <- caTools::colAUC(preds,PimaIndiansDiabetes$diabetes)
err <- 1-auc
myl <- rbind(myl,c(err,model_means,trees[ii]))
}
names(myl) <- c("err","means","trees")Look at this data frame which has a compute error / validation rate for each set of trees that we create:
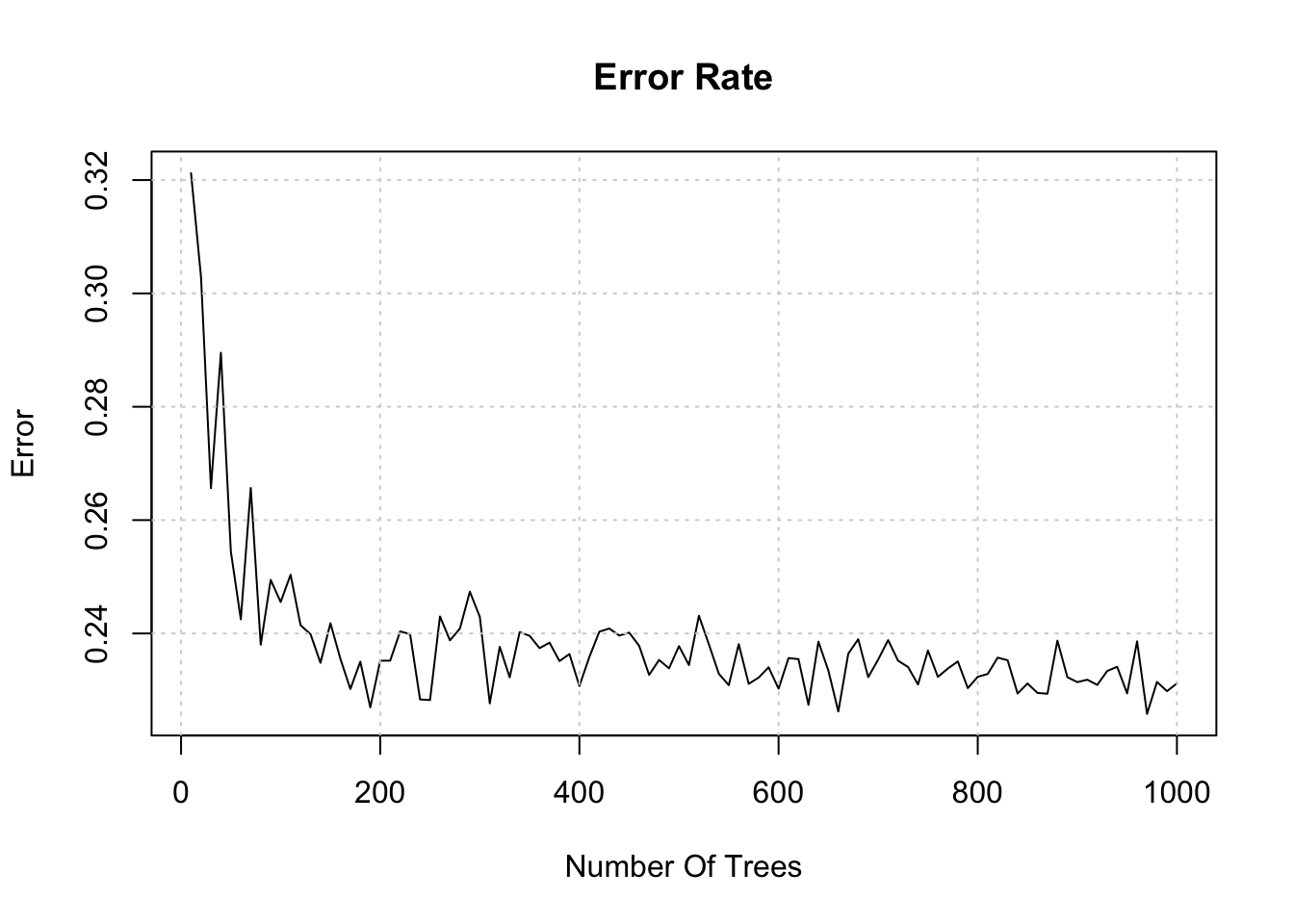
9.2 Parameters vs Hyperparameters
Model parameters are things that are generated as part of the modeling process. They are the product or result of model fitting. These might be things like slope and intercept from a linear model - or coefficients.
Hyperparameters have default values for various arguments but this does not mean that the defaults are appropriate for all cases.
So with rf there is a hyperarameter called mtry that influences the outcome but is not necessarily something that we know how to optimally set. The mtry value is the number of variables that are randomly sampled at each tree split.
To put this into perspective, if we had called the random Forest function without using caret we would have to supply a value for mtry or be prepared to accept whatever the default value is.
library(randomForest)
non_caret_rf <- randomForest(mpg~.,
data = new_train,
mtry = 3, # This is the default
importance = TRUE)
# Check out the RMSE of the preditcions
Metrics::rmse(new_test$mpg,predict(non_caret_rf,new_test))## [1] 1.469268The randomForest function will generate “importance” information on the variables. This information is considered as the method makes its splits.
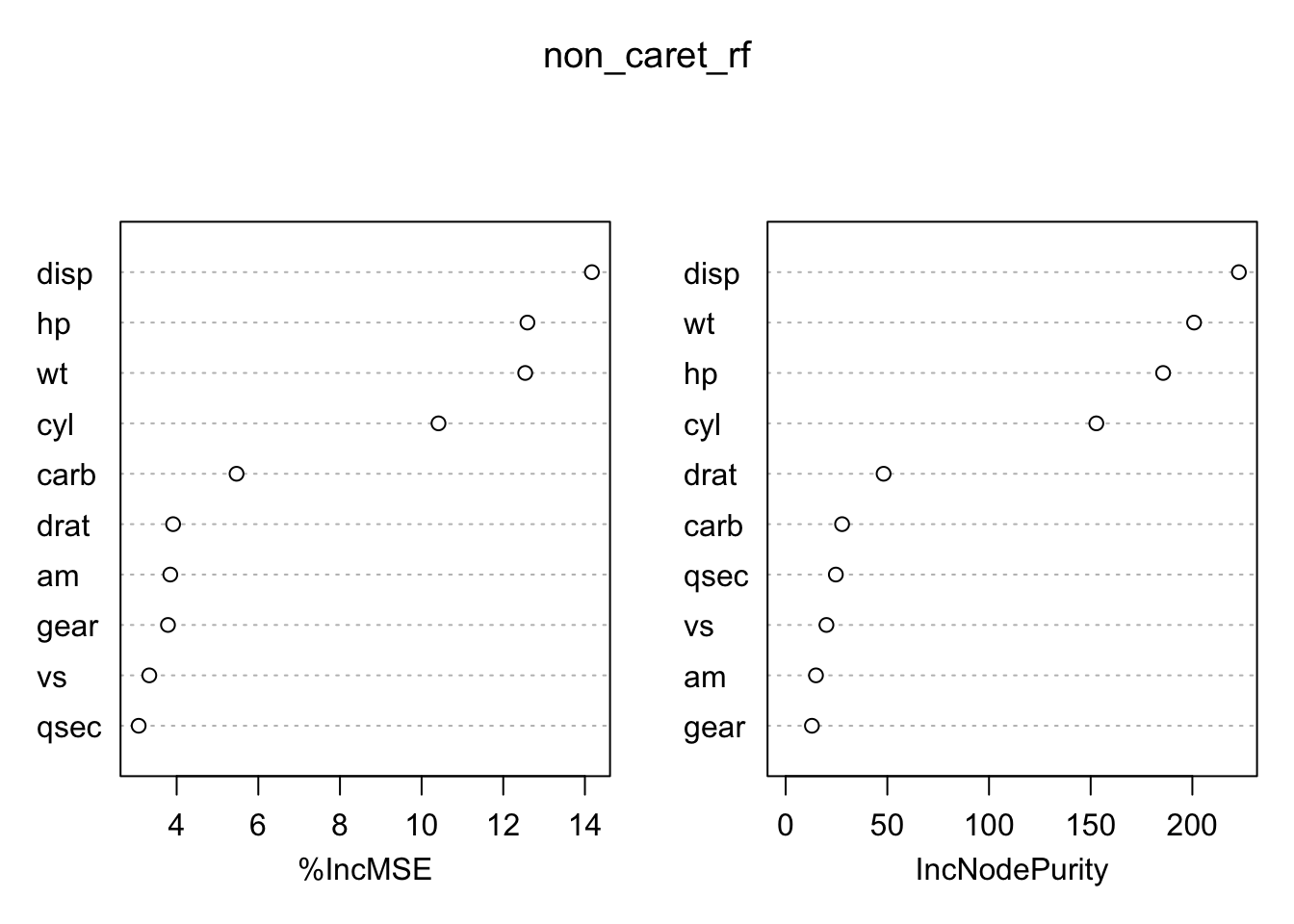
To get an idea about how the model performs with other values of mtry we could write a function to accept this value as an argument. Our function will return the RMSE corresponding to the supplied value of mtry.
make_mtcars_rf <- function(mtry=3) {
my_rf <- randomForest(mpg~.,
data = new_train,
mtry = mtry,
importance = TRUE)
# Check out the predictions
rmse_rf <- Metrics::rmse(new_test$mpg,predict(my_rf,new_test))
return(rmse_rf)
}So now, the following example will call the randomForest package 5 times. Starting with the first iteration, the value of mtry will be 3, the next time it will be 4, and so on until the last iteration where it will be 8. This is just an experiment to see if varying mtry will help minimize the RMSE of our model.
We also have to be careful not to pick incorrect values for mtry so reading the help page for the randomForest package would be helpful. On the other hand, since mtry represents the number of features / variables to sample at each potential split, we know that it cannot practically exceed the total number of features in the data frame.
## [1] 1.535346 1.569709 1.540436 1.702148 1.691068 1.607935 1.625691## [1] 1.610333We could even create a plot of this information to simplify the selection of mtry corresponding to the lowest RMSE.
plot(1:length(total_rmse),total_rmse,type="b",
xlab = "Value of mtry",
ylab = "RMSE",
main = "How RMSE varies with mtry")
grid()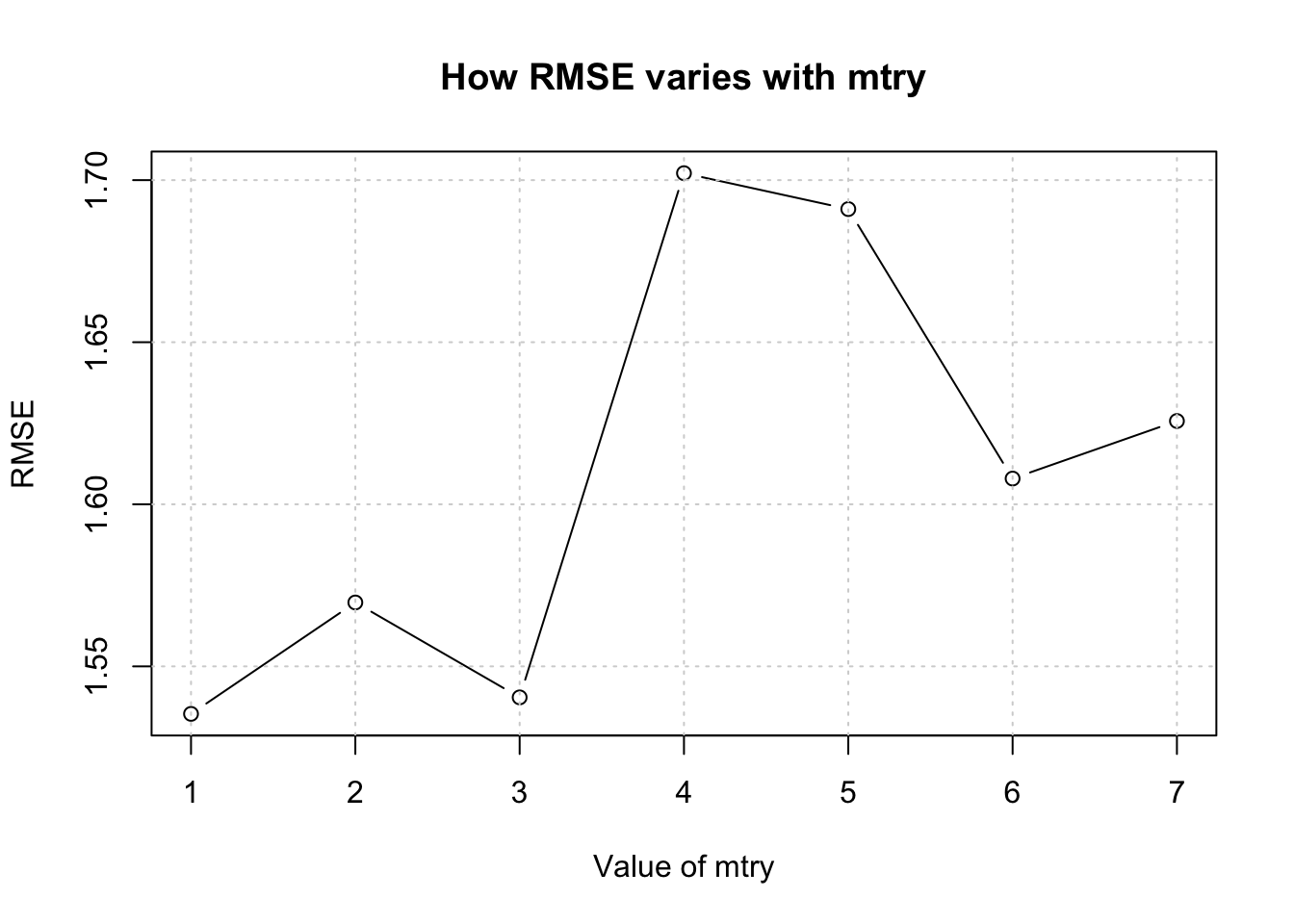
While this is fine what would happen if there were more than one hyperparameter. If we look closer at the documentation for randomForest then we see that there is a hyperparameter called ntree which is set by default to a value of 500. We could build that into our above function to see how that might impact RMSE performance. For example, we’ll work through values of mtry from 2,3,..8. For each of those values of mtry we will use values of ntree ranging from 300, 400, to 500. Let’s go ahead and do that. So let’s build a “grid” of values.
## mtry numoftrees
## 1 2 300
## 2 3 300
## 3 4 300
## 4 5 300
## 5 6 300
## 6 7 300
## 7 8 300
## 8 2 400
## 9 3 400
## 10 4 400
## 11 5 400
## 12 6 400
## 13 7 400
## 14 8 400
## 15 2 500
## 16 3 500
## 17 4 500
## 18 5 500
## 19 6 500
## 20 7 500
## 21 8 500We need to rewrite our function to handle this “training grid”. It’s not terribly difficult, just a bit tedious.
make_mtcars_rf <- function(grid=train_grid) {
retlist <- data.frame()
for (ii in 1:nrow(grid)) {
my_rf <- randomForest(mpg~.,
data = new_train,
mtry = grid[ii,]$mtry,
ntree = grid[ii,]$numoftrees,
importance = TRUE)
rmse_rf <- Metrics::rmse(new_test$mpg,predict(my_rf,new_test))
retlist <- rbind(retlist,c(grid[ii,]$mtry,grid[ii,]$numoftrees,
rmse_rf))
names(retlist) <- c("mtry","ntree","rmse")
}
# Check out the predictions
return(retlist)
}Now we’ll call this function and plot the output. It appears that values of mtry correspinding to the lowest RMSE range from 4,5 to 6 depending on the number of trees. The good news is that we now have a function that we could use with other training grids.
make_mtcars_rf() %>%
ggplot(aes(x=mtry,y=rmse)) +
geom_line() + facet_wrap(~ntree) +
ggtitle("Hyperparameter Experiment") + theme_bw()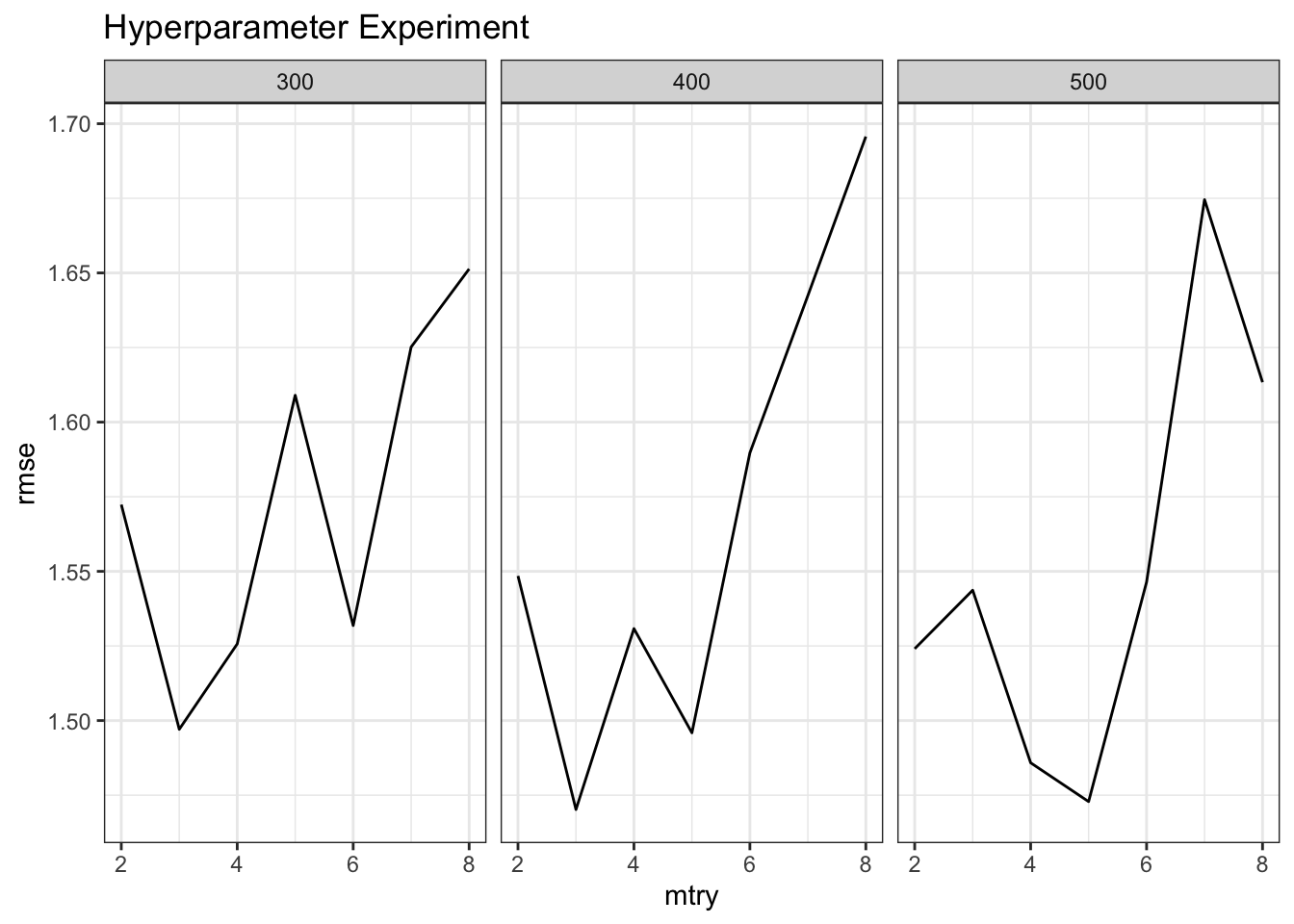
The above is an example of what we would have to do if we didn’t have something like caret to help us try out different values of mtry or other parameters. But we could see how the caret function handles this.
## Random Forest
##
## 28 samples
## 10 predictors
##
## No pre-processing
## Resampling: Bootstrapped (25 reps)
## Summary of sample sizes: 28, 28, 28, 28, 28, 28, ...
## Resampling results across tuning parameters:
##
## mtry RMSE Rsquared MAE
## 2 2.781338 0.8787494 2.265497
## 6 2.773825 0.8711962 2.220108
## 10 2.820082 0.8629105 2.265783
##
## RMSE was used to select the optimal model using the smallest value.
## The final value used for the model was mtry = 6.As a matter of fact we can plot this model with not a lot of effort and it will show us something interesting. An mtry of 6 seems to be the best. This is the power of methods that use hyperparamters. If we move through a number of values for the mtry then perhaps we can find the best value to get the best result.
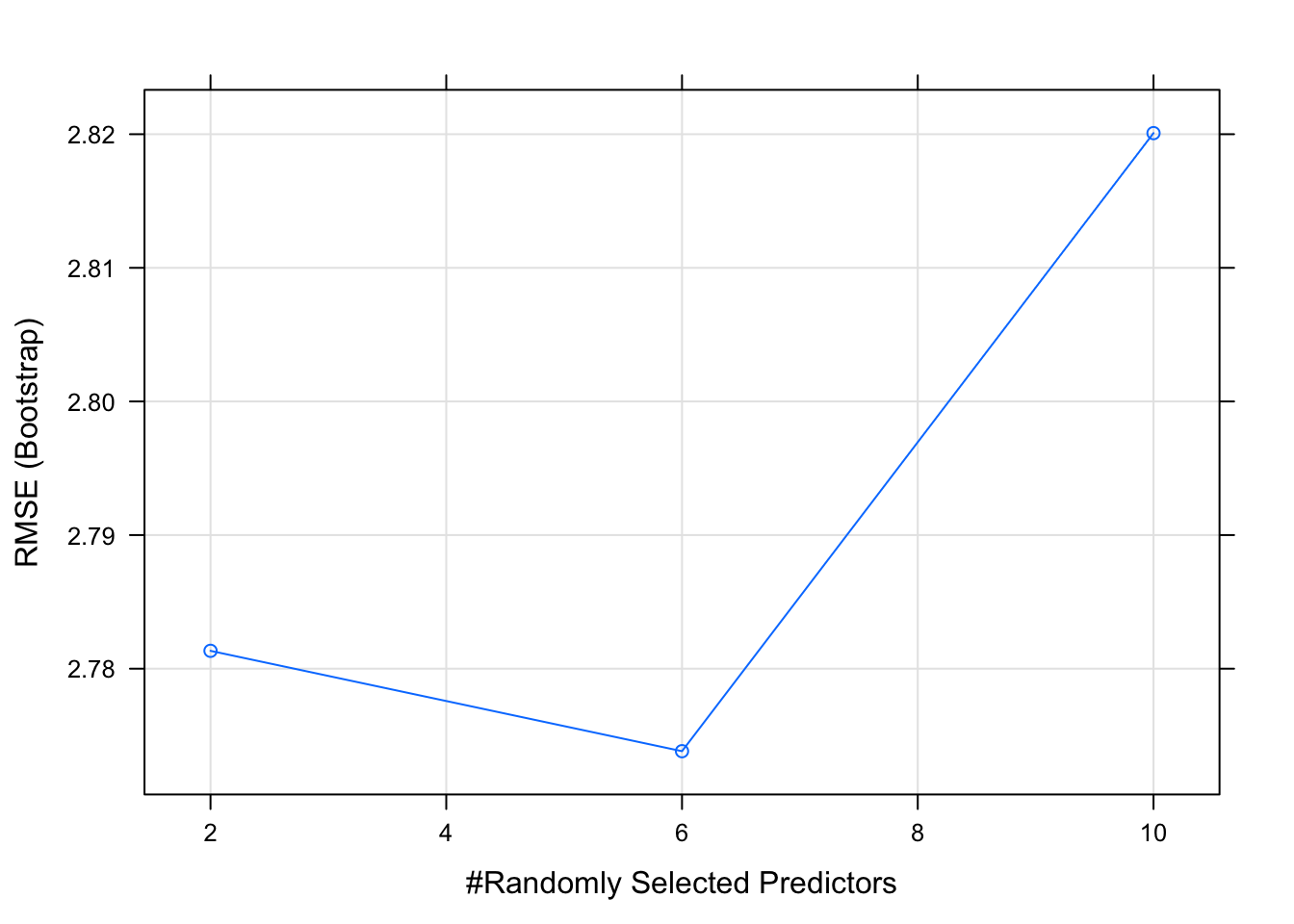
Telling caret to use more values of mtry is possible. This will explicitly try all values from 1 - 9 inclusive. Note that the model gets built for each value of mtry. This causes the model building process to take longer than it normally would.
set.seed(333)
caret_rf <- train(mpg ~ .,
data = new_train,
method = "rf",
tuneLength = 9,
metric="RMSE")
caret_rf$results## mtry RMSE Rsquared MAE RMSESD RsquaredSD MAESD
## 1 2 2.777893 0.8329378 2.306009 0.8075533 0.08524712 0.6122838
## 2 3 2.707934 0.8364533 2.223756 0.8257185 0.08264879 0.6285948
## 3 4 2.688368 0.8327089 2.180973 0.7997112 0.09027142 0.6120849
## 4 5 2.698068 0.8270306 2.185700 0.7959108 0.09627627 0.6034921
## 5 6 2.713194 0.8248066 2.202417 0.7985325 0.09966876 0.6083930
## 6 7 2.713078 0.8244281 2.204616 0.8095515 0.10280832 0.6112903
## 7 8 2.754981 0.8171458 2.232152 0.8230639 0.10889844 0.6196007
## 8 9 2.747497 0.8167239 2.221001 0.8126412 0.10930454 0.6134222
## 9 10 2.788511 0.8072585 2.258000 0.8357519 0.12390190 0.6244098## [1] 1.565494It looks like a value of 5 will produce the lowest value for RMSE.
![]()
9.3 Hyperparameter Tuning
The process of finding the “right” values for these parameters is generally referred to as “hyperparameter tuning”. Different values are supplied for each invocation of a method (as we did in the above example) to see the effect on the model. We might do this many times to arrive at the optimal parameter set to produce a model that offers the “best” explanatory and predictive power.
Just to review - things like coefficients and residuals are parameters that are generated by a call to the lm function. They don’t actually exist until the function does some work. The hyperparameters are specific to whatever algorithm (and supporting R function) you are using. Concepts such as coefficients and intercept, however, are parameters that would be generated in this case by lm.
More generally, what if we wanted to use other functions to do some predicting ? You can check this page for a list of caret supported methods along with any hyperparamters available for tuning. Obviously, if you know the underlying method you can refer directly to the help page for it.
9.3.1 Multiple Hyperparameters ?
Let’s look at another method for random forests such as the ranger function which builds trees very rapidly. We can easily call it via the train function. If you consult the reference manual for the caret implementation of ranger you will see that it supports three hyperparameters: mtry, splitrule, and min.node.size.
control <- trainControl(method="cv",number=5)
caret_ranger <- train(mpg ~ .,
data = new_train,
method = "ranger",
trControl=control)
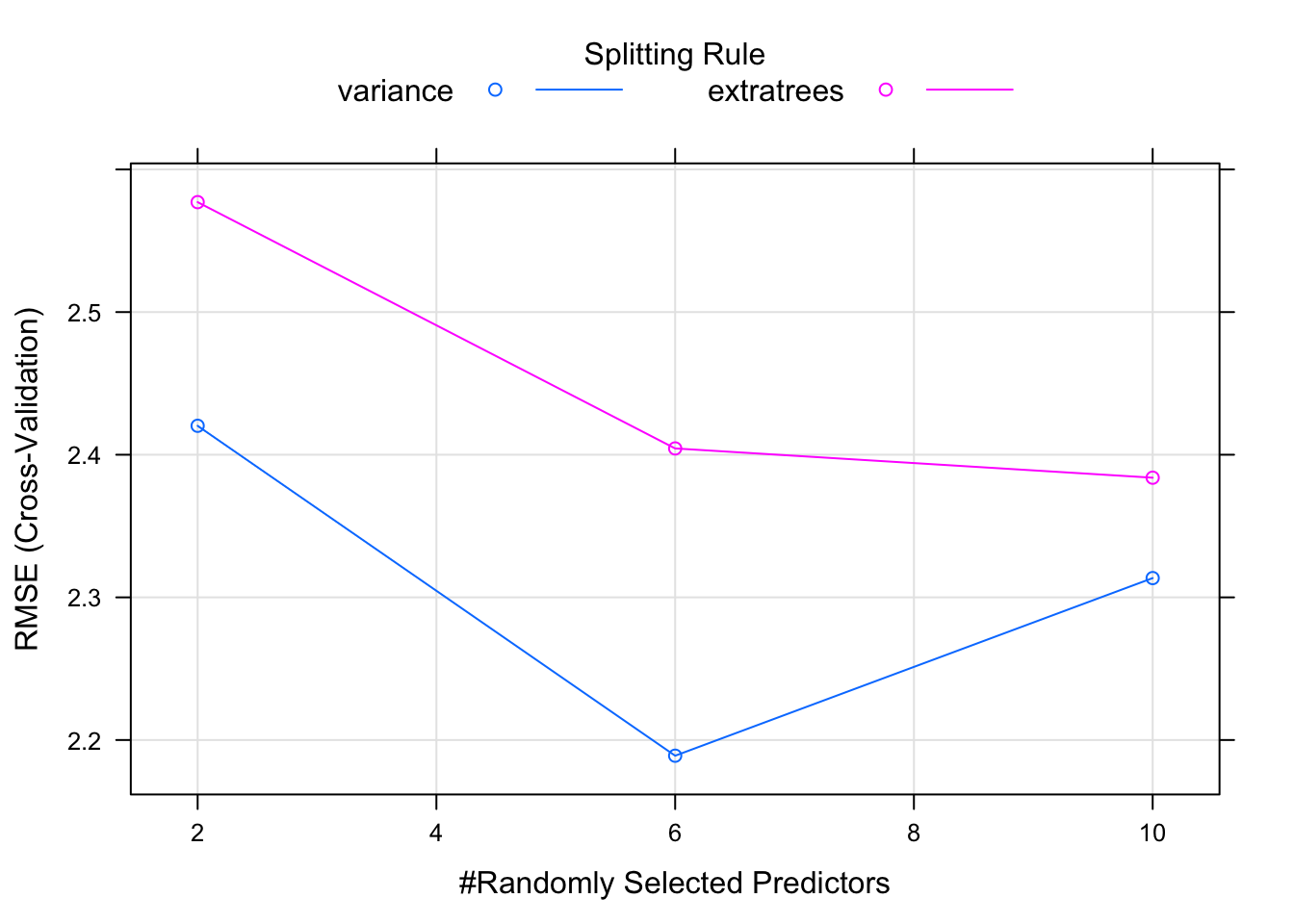
caret_ranger$results## mtry min.node.size splitrule RMSE Rsquared MAE RMSESD
## 1 2 5 variance 2.420283 0.8817709 2.070881 0.9629579
## 2 2 5 extratrees 2.577072 0.8675261 2.189386 0.9148562
## 3 6 5 variance 2.188993 0.9129126 1.902930 0.9468856
## 4 6 5 extratrees 2.404408 0.8864300 2.059083 0.9755153
## 5 10 5 variance 2.313519 0.9034322 1.986604 1.0152668
## 6 10 5 extratrees 2.383894 0.8804195 2.067131 0.9810274
## RsquaredSD MAESD
## 1 0.09413014 0.8113495
## 2 0.09087771 0.7718545
## 3 0.06021190 0.8339764
## 4 0.08509933 0.8222557
## 5 0.06925268 0.8933195
## 6 0.09000082 0.8484198## [1] 1.622359And then we can plot these results to get a more intuitive view of the output. What we see is that it sweeps through three values of mtry. for each of those it tries out a split rule of “variance” or “extratrees” and min.node.size of 5.
caret_ranger <- train(mpg ~ .,
data = new_train,
method = "ranger",
tuneLength = 5)
caret_ranger$results## mtry min.node.size splitrule RMSE Rsquared MAE RMSESD
## 1 2 5 variance 2.745110 0.8386075 2.232059 0.8775407
## 2 2 5 extratrees 2.858267 0.8288605 2.331372 0.8267875
## 3 4 5 variance 2.646856 0.8499870 2.096958 0.8781255
## 4 4 5 extratrees 2.763223 0.8355882 2.236276 0.7847133
## 5 6 5 variance 2.678067 0.8426597 2.119717 0.8921418
## 6 6 5 extratrees 2.756968 0.8357985 2.218871 0.7717121
## 7 8 5 variance 2.704707 0.8350572 2.137650 0.8888951
## 8 8 5 extratrees 2.749264 0.8379402 2.221612 0.7653985
## 9 10 5 variance 2.786513 0.8248111 2.201705 0.8994882
## 10 10 5 extratrees 2.742293 0.8351907 2.221480 0.7747831
## RsquaredSD MAESD
## 1 0.08171881 0.6139693
## 2 0.07691352 0.5993940
## 3 0.07947436 0.6269710
## 4 0.08185904 0.5547715
## 5 0.08815717 0.6512297
## 6 0.08007810 0.5254076
## 7 0.09355277 0.6582032
## 8 0.08155265 0.5213806
## 9 0.09426723 0.6965009
## 10 0.08672079 0.5322976## [1] 1.504538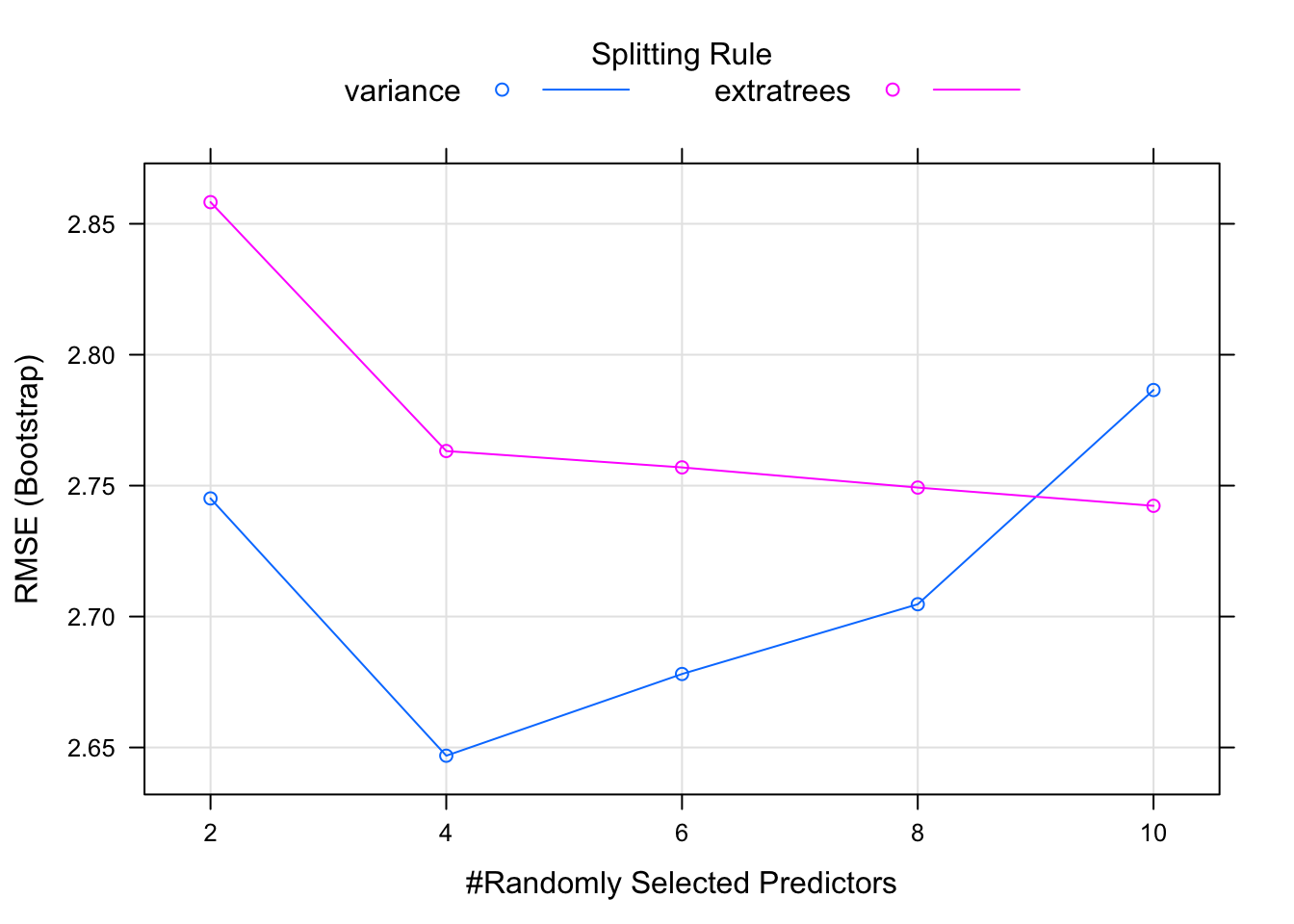
9.3.2 Custom Tuning Grid
So it’s possible to go even deeper when tuning hyperparameters. We can create a custom tuning grid instead of letting caret pick the values. Of course, using tuneLength is fine but the custom tuning grid allows for finer grained control. It’s easy, all we need to do is to specify our own “tuneGrid” and then pass it to train.
MyGrid <- data.frame(
mtry = c(2, 4, 6),
splitrule = "variance",
min.node.size = 4
)
# Now we supply it when calling train
caret_ranger <- train(mpg ~ .,
data = new_train,
method = "ranger",
tuneGrid = MyGrid)
caret_ranger$results## mtry splitrule min.node.size RMSE Rsquared MAE RMSESD RsquaredSD
## 1 2 variance 4 2.521752 0.8611547 2.032140 0.7317098 0.05969499
## 2 4 variance 4 2.424938 0.8666951 1.947128 0.7115724 0.06316216
## 3 6 variance 4 2.424197 0.8630825 1.956374 0.6950800 0.06778541
## MAESD
## 1 0.5151851
## 2 0.5184218
## 3 0.5013023## [1] 1.5163959.4 Applied To Classification
We could extend this it deal with classification problems. We can adapt our randomForest function for use in predicting the Pima Indians diabetes outcome.
url <- "https://raw.githubusercontent.com/steviep42/bios534_spring_2020/master/data/pima.csv"
pm <- read.csv(url)We’ll implement the train / test pair
Next, we’ll build the model using the randomForest method
Then we’ll do the usual things of making some predictions and then look at an Accuracy and an AUC.
Compute the AUC:
## [,1]
## neg vs. pos 0.75Well, that was nice but how would we work in the search grid approach to see how this might be impacted by varying the hyper parameters ? We could start by picking parameters at random - as long as they are valid. mtry needs to be from 2 up to some number of features in the data set (this varies with the method) The number of trees should be somewhere between 100 and 1600.
set.seed(12)
mtry = sample(3:8,5)
ntrees = sample(200:1200,5)
my_grid <- data.frame()
for (ii in 1:length(mtry)) {
for (jj in 1:length(ntrees)) {
my_grid <- rbind(my_grid,c(mtry[ii],ntrees[jj]))
}
}
names(my_grid) <- c("mtry","numoftrees")
my_grid## mtry numoftrees
## 1 4 373
## 2 4 652
## 3 4 268
## 4 4 675
## 5 4 745
## 6 8 373
## 7 8 652
## 8 8 268
## 9 8 675
## 10 8 745
## 11 6 373
## 12 6 652
## 13 6 268
## 14 6 675
## 15 6 745
## 16 5 373
## 17 5 652
## 18 5 268
## 19 5 675
## 20 5 745
## 21 3 373
## 22 3 652
## 23 3 268
## 24 3 675
## 25 3 745So we could write a function to accept the combined set of randmoized parameters to see how it impacts performance:
make_diabetes_rf <- function(grid=train_grid) {
retlist <- data.frame()
for (ii in 1:nrow(grid)) {
my_rf <- randomForest(diabetes ~ . ,
data = rf_train,
mtry = grid[ii,]$mtry,
ntree = grid[ii,]$numoftrees,
importance = TRUE)
# Get the AUC
rf_probabilities <- predict(my_rf,rf_test,type="prob")
auc <- caTools::colAUC(rf_probabilities[,1],rf_test$diabetes)
# Get the Accuracy
rf_labels <- predict(my_rf,rf_test)
myt <- table(rf_labels,rf_test$diabetes)
acc <- sum(diag(myt))/sum(myt)
# Return a data frame with the information
retlist <- rbind(retlist,
c(grid[ii,]$mtry,grid[ii,]$numoftrees,auc,acc))
names(retlist) <- c("mtry","ntree","auc","acc")
}
#
return(retlist)
}Let’s see what we get back:
## mtry ntree auc acc
## 1 4 373 0.7324528 0.7189542
## 2 4 652 0.7366038 0.6993464
## 3 4 268 0.7350943 0.6928105
## 4 4 675 0.7394340 0.7058824
## 5 4 745 0.7274528 0.6993464
## 6 8 373 0.7183962 0.6993464
## 7 8 652 0.7211321 0.6928105
## 8 8 268 0.7163208 0.6993464
## 9 8 675 0.7224528 0.6993464
## 10 8 745 0.7171698 0.6928105
## 11 6 373 0.7237736 0.6993464
## 12 6 652 0.7243396 0.6993464
## 13 6 268 0.7276415 0.7058824
## 14 6 675 0.7232075 0.6993464
## 15 6 745 0.7260377 0.6928105
## 16 5 373 0.7233019 0.6928105
## 17 5 652 0.7295283 0.6928105
## 18 5 268 0.7281132 0.7058824
## 19 5 675 0.7307547 0.6928105
## 20 5 745 0.7293396 0.6993464
## 21 3 373 0.7444340 0.7058824
## 22 3 652 0.7422642 0.6993464
## 23 3 268 0.7387736 0.7058824
## 24 3 675 0.7393396 0.6993464
## 25 3 745 0.7383019 0.7058824So there isn’t a lot of variance in the outcomes although we didn’t know that previously which is why we performed the random search in the first place. If we wanted to, we could do something less random and more systematic by creating a predictable seqeucne of values for the hyperparameters which would result in a more granular search. In this example, we’ll also take advantage of a function called expand.grid which will help make the training grid. We could still use the above approach which uses for loops if we wanted to.
## mtry numoftrees
## 1 2 200
## 2 3 200
## 3 4 200
## 4 5 200
## 5 6 200
## 6 7 200
## 7 8 200
## 8 2 400
## 9 3 400
## 10 4 400
## 11 5 400
## 12 6 400
## 13 7 400
## 14 8 400
## 15 2 600
## 16 3 600
## 17 4 600
## 18 5 600
## 19 6 600
## 20 7 600
## 21 8 600
## 22 2 800
## 23 3 800
## 24 4 800
## 25 5 800
## 26 6 800
## 27 7 800
## 28 8 800
## 29 2 1000
## 30 3 1000
## 31 4 1000
## 32 5 1000
## 33 6 1000
## 34 7 1000
## 35 8 1000
## 36 2 1200
## 37 3 1200
## 38 4 1200
## 39 5 1200
## 40 6 1200
## 41 7 1200
## 42 8 1200
## 43 2 1400
## 44 3 1400
## 45 4 1400
## 46 5 1400
## 47 6 1400
## 48 7 1400
## 49 8 1400make_diabetes_rf <- function(grid=train_grid) {
retlist <- data.frame()
for (ii in 1:nrow(grid)) {
my_rf <- randomForest(diabetes ~ . ,
data = rf_train,
mtry = grid[ii,]$mtry,
ntree = grid[ii,]$numoftrees,
importance = TRUE)
# Get the AUC
rf_probabilities <- predict(my_rf,rf_test,type="prob")
auc <- caTools::colAUC(rf_probabilities[,1],rf_test$diabetes)
# Get the Accuracy
rf_labels <- predict(my_rf,rf_test)
myt <- table(rf_labels,rf_test$diabetes)
acc <- sum(diag(myt))/sum(myt)
# Return a data frame with the information
retlist <- rbind(retlist,
c(grid[ii,]$mtry,grid[ii,]$numoftrees,auc,acc))
names(retlist) <- c("mtry","ntree","auc","acc")
}
#
return(retlist)
}So we could look at how the AUC varies for the values of mtry and ntrees. What we will experience here is longer run times because the grid has more values than the one we made when using a random approach.
## [1] 25## [1] 49This plot will show us what is happening.
stats <- stats %>% mutate(ntree=factor(ntree))
ggplot(stats,aes(x=mtry,y=auc)) + geom_line() +
facet_grid(.~ntree) + theme_bw() +
ggtitle("AUC Across Random Forest Hyperparameters")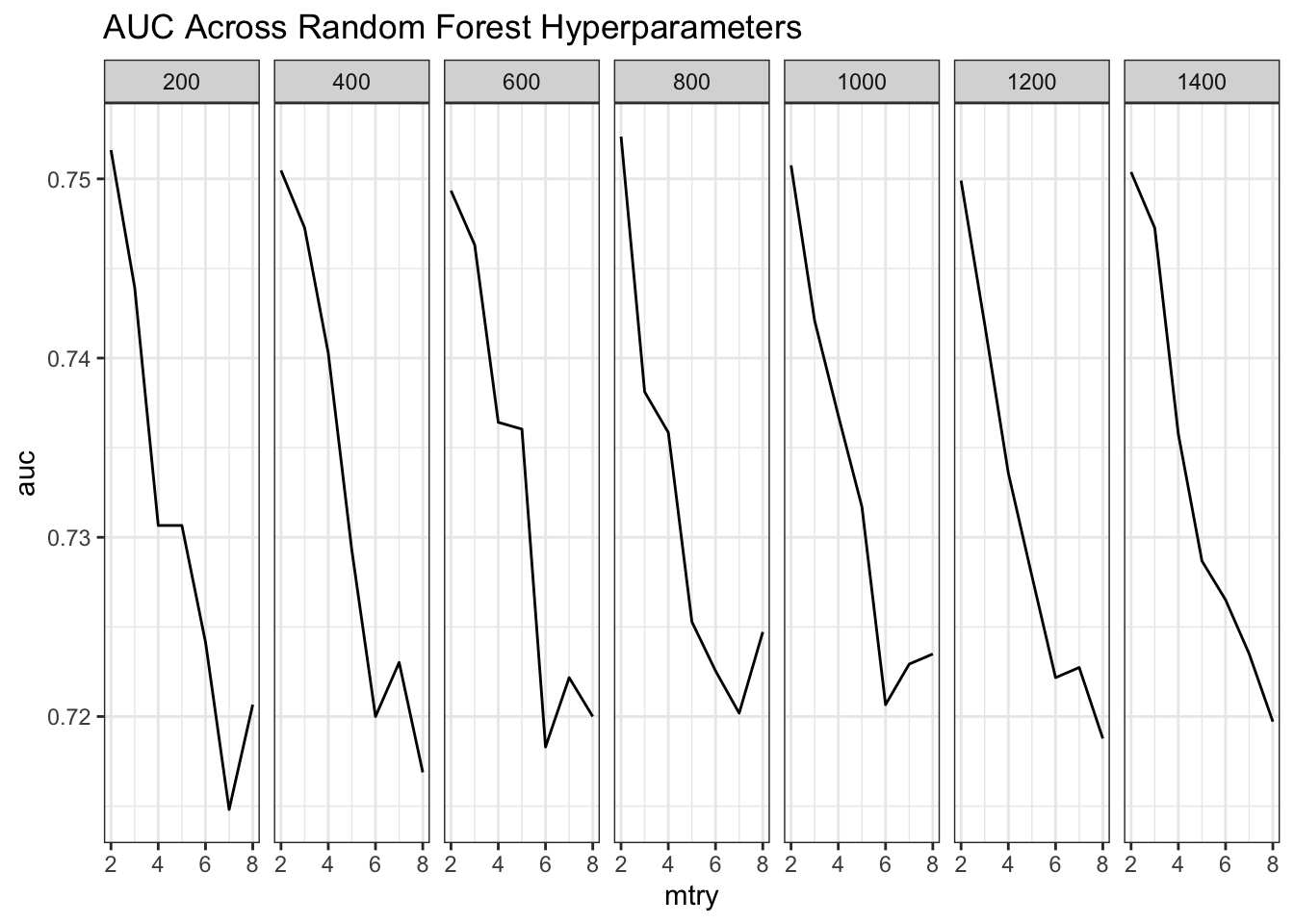
So what about the Accuracy ? It would be nice to see that on the graph also. There aren’t major variations in these metrics across these parameters. It depends on the method
# Reformat the stats data frame into long format
long_stats <- stats %>% gather(key="variable",value="value",-mtry,-ntree)
# Next, make the plot
ggplot(data=long_stats,
aes(x=mtry, y=value, colour=variable)) +
geom_line() + facet_wrap(~ntree) + theme_minimal() +
ggtitle("AUC and Accuracy Across Random Forest Hyperparameters")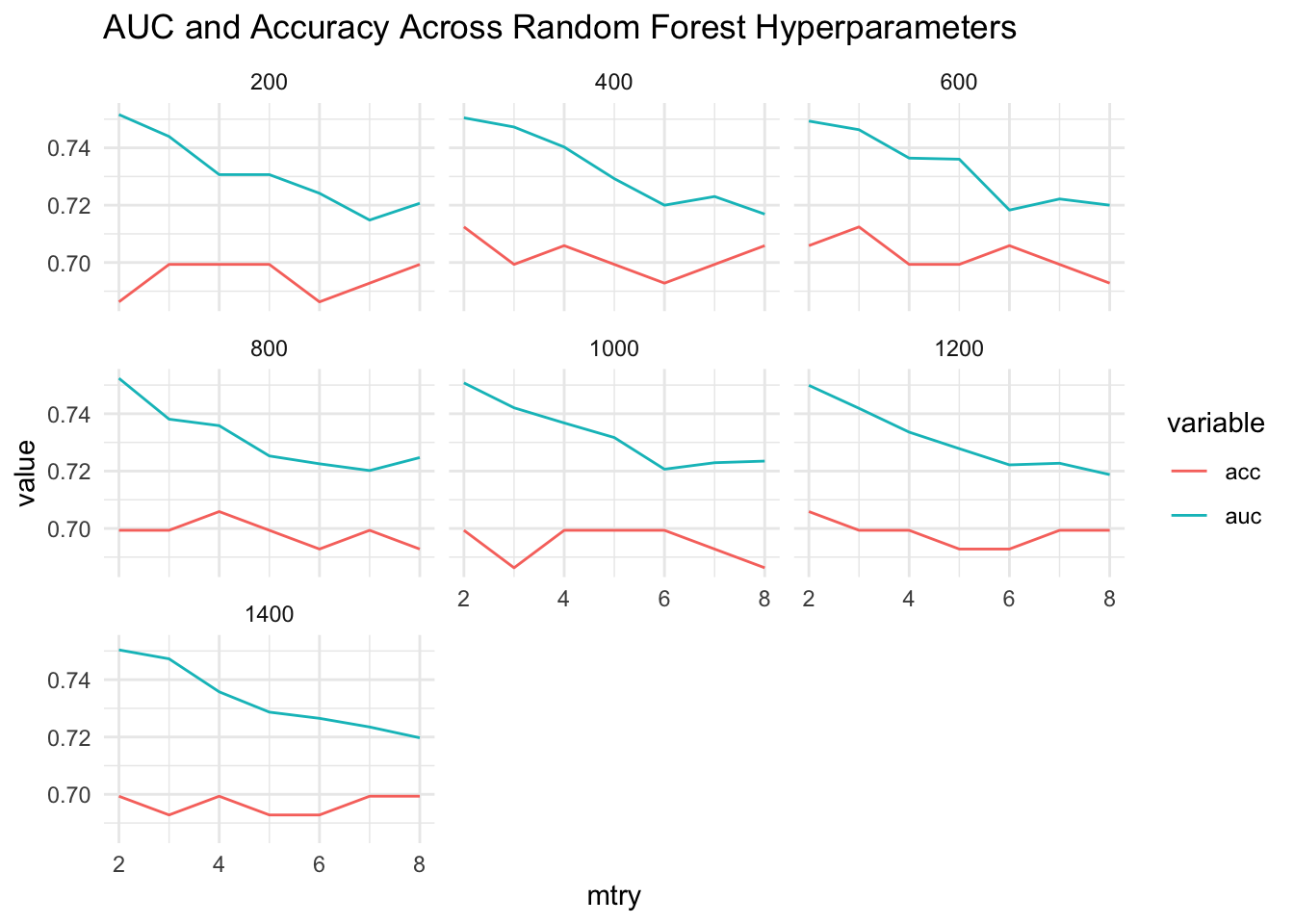
There are other ways to do this as some functions have tuning methods associated with them to help address this issue. The randomForest function is one such function. There is the tuneRF function available. Let’s go back to a basic example:
So we could use the tuneRF function and pass it our X and Y variables along with some arguments to do a grid search with hyperparameters. The function itself will call the randomForest package:
X = rf_train[,1:8]
Y = rf_train[,9]
my_tune <- tuneRF(X,Y,mtryStart=2,ntreeTry=50,stepFactor=2,doBest=T)## mtry = 2 OOB error = 23.74%
## Searching left ...
## mtry = 1 OOB error = 23.9%
## -0.006849315 0.05
## Searching right ...
## mtry = 4 OOB error = 24.39%
## -0.02739726 0.05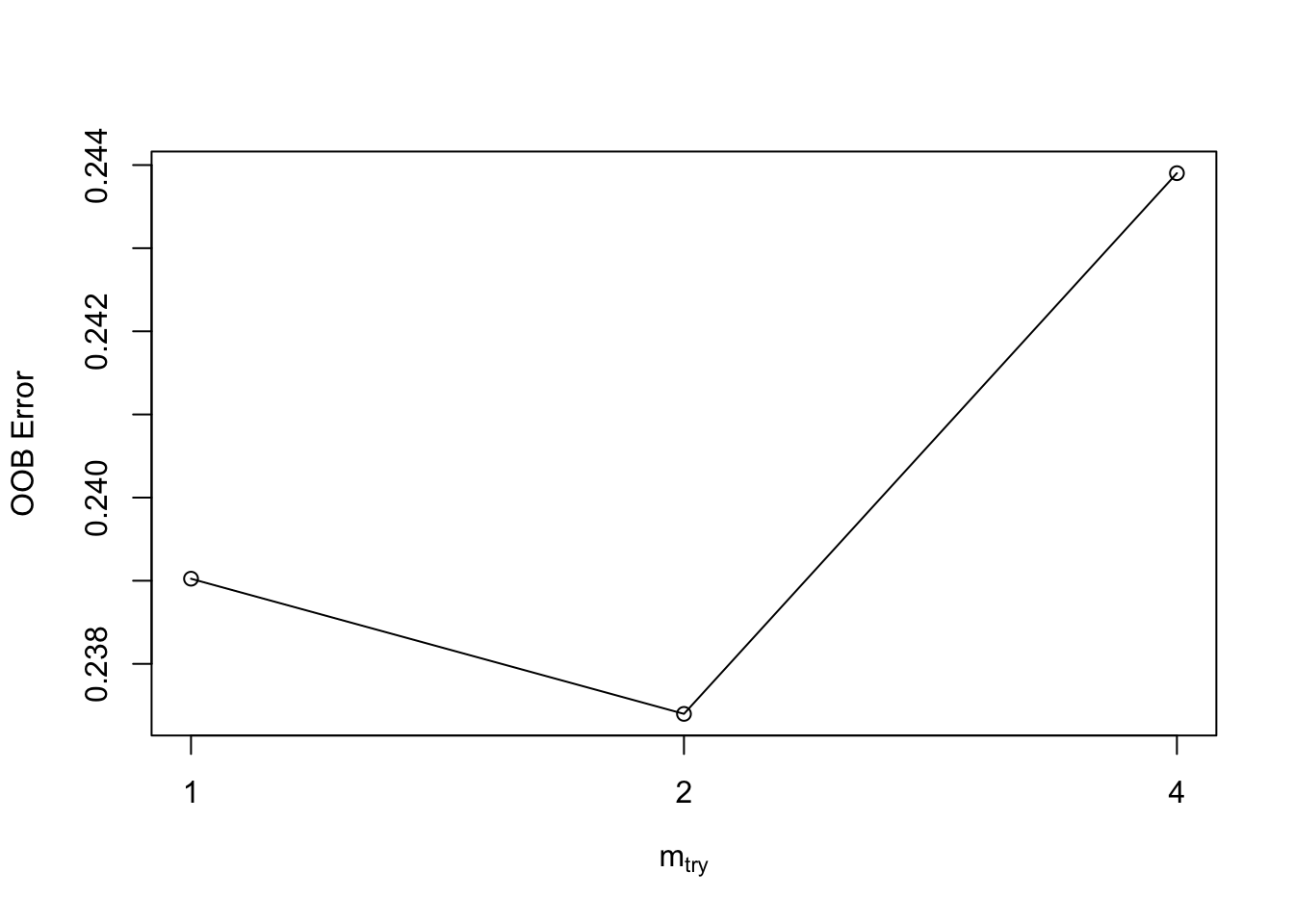
##
## Call:
## randomForest(x = x, y = y, mtry = res[which.min(res[, 2]), 1])
## Type of random forest: classification
## Number of trees: 500
## No. of variables tried at each split: 2
##
## OOB estimate of error rate: 21.95%
## Confusion matrix:
## neg pos class.error
## neg 348 52 0.1300000
## pos 83 132 0.38604659.5 Using Validation Data Sets
When building a model, we generate a training and test data set. We use the former to build a model and, if we are using something like the caret package, that process involves cross fold validation or bootstrap sampling to generate a good estimate for out-of-sample error. We then apply the model to the test data frame.
If we are using a method that has hyperparamters then maybe we want an intermediate data set to help validate our ultimate choice of hyperparameters. By taking this approach we can still keep our test data set off to the side for later use with the trained and validated model. Using this idea doesn’t require us to do much beyond generating a third data set.
The training set is used to build the classifier
The validation set is used to tune the algorithm hyperparameters repeatedly.
So there will be some overfitting here, but that is why there is another stage:
The test set must not be touched until the classifier is final to prevent
overfitting. It serves to estimate the true accuracy, if you would put the model
into production.# Simple into 3 sets.
idx <- sample(seq(1, 3), size = nrow(pm), replace = TRUE, prob = c(.8, .2, .2))
train <- pm[idx == 1,]
test <- pm[idx == 2,]
valid <- pm[idx == 3,]
#
nrow(train)## [1] 509## [1] 144## [1] 115Then we might build a model using the training data. We’ll use Accuracy as a metric.
control <- trainControl(method="cv",number=5)
set.seed(123)
train_rf <- train(diabetes~.,
data = train,
metric = "Accuracy",
method = "rf",
trControl = control)
train_rf## Random Forest
##
## 509 samples
## 8 predictor
## 2 classes: 'neg', 'pos'
##
## No pre-processing
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 407, 408, 407, 407, 407
## Resampling results across tuning parameters:
##
## mtry Accuracy Kappa
## 2 0.7603960 0.4658608
## 5 0.7544943 0.4586780
## 8 0.7446709 0.4365889
##
## Accuracy was used to select the optimal model using the largest value.
## The final value used for the model was mtry = 2.set.seed(123)
valid_rf <- train(diabetes~.,
data=valid,
metric="Accuracy",
method = "rf",
trControl = control)
valid_rf$bestTune## mtry
## 2 5# Now we would use the value of mtry to find an appropriate value
# of mtyry to use in the test data. From tje previous step it is 8
set.seed(123)
test_rf <- train(diabetes~.,
data=test,
metric="Accuracy",
method = "rf",
trControl = trainControl(method="none"),
tuneGrid = data.frame(mtry = 8))
some_preds <- predict(test_rf,test)
confusionMatrix(table(preds=some_preds,actual=test$diabetes),positive="pos")## Confusion Matrix and Statistics
##
## actual
## preds neg pos
## neg 97 0
## pos 0 47
##
## Accuracy : 1
## 95% CI : (0.9747, 1)
## No Information Rate : 0.6736
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 1
##
## Mcnemar's Test P-Value : NA
##
## Sensitivity : 1.0000
## Specificity : 1.0000
## Pos Pred Value : 1.0000
## Neg Pred Value : 1.0000
## Prevalence : 0.3264
## Detection Rate : 0.3264
## Detection Prevalence : 0.3264
## Balanced Accuracy : 1.0000
##
## 'Positive' Class : pos
##