Chapter 6 Classification Problems
Next up we consider the issue of building a model to predict a binary (e.g. “yes” / “no” or “positive /”negative“) outcome although we might also predict more than one class. For the sake of explanation we’ll keep our attention to the”two class" situation.
6.1 Performance Measures
With Linear Regression we were predicting a continuous outcome with the goal of being able to minimize the RMSE (root mean square error). In classification problems we need a metric or “performance measure” that we can use to judge the effectiveness of any model we create. Typically in classification we would be predicting some binary outcome such as whether someone has a disease or not. In this case it would not make sense to use something like RMSE. Other measures such as Accuracy, Precision, or Sensitivity are more appropriate.
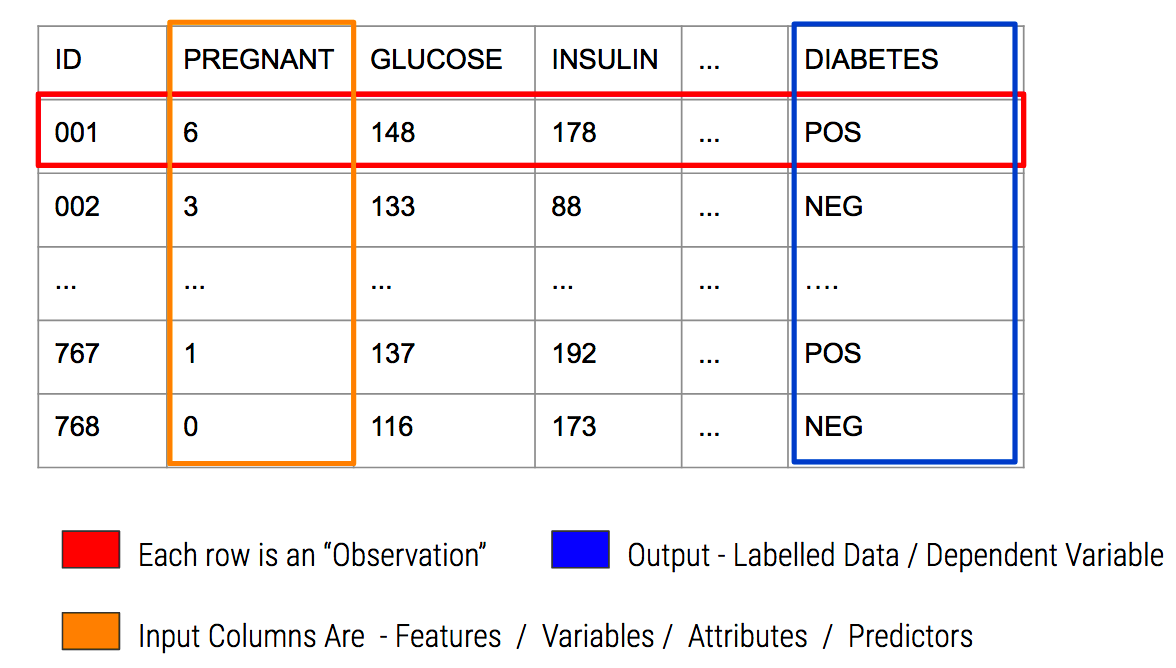
An example might help - we’ll be spending some time with the PimaIndiansDiabetes dataframe that is part of the mlbench package. This is part of the mlbench package or you can read it in straight from the internet.
Once you have it installed then load it into the work space as follows:
Or just read it in.
url <- "https://raw.githubusercontent.com/steviep42/bios534_spring_2020/master/data/pima.csv"
pm <- read.csv(url)The description of the data set is as follows:

So we now have some data on which we can build a model. Specifically, there is a variable in the data called “diabetes” which indicates the disease / diabetes status (“pos” or “neg”) of the person. It would be good to come up with a model that we could use with incoming data to determine if someone has diabetes.
6.2 Important Terminology
In predictive modeling there are some common terms to consider:
6.3 A Basic Model
Since we are attempting to predict a binary outcome here (“pos” or “neg”) we’ll need to use something other than linear regression which is used to predict numeric outcomes. We’ll go with Logistic Regression as it is a tried and true method for doing this type of thing.
Let’s use the native glm function to do this since it will motivate some important concepts. We’ll split the data into a train / test pair using the createDataPartition function from caret. We’ll go with an 80% / 20% split. You’ve seen this before with the linear modelling examples.
set.seed(891)
idx <- createDataPartition(pm$diabetes, p=.80, list=FALSE)
glm_train <- pm[idx,]
glm_test <- pm[-idx,]
glm_model <- glm(diabetes ~ .,
data = glm_train,
family = "binomial")
# Next well make some predictions using the test data
glm_preds <- predict(glm_model,
glm_test,
type="response")
glm_preds[1:10]## 2 6 8 22 23 30 33
## 0.05836318 0.15559574 0.67209318 0.31189099 0.93064630 0.27846273 0.05726965
## 36 38 40
## 0.14730284 0.39319711 0.53563224What do we get back from our prediction ? These are probabilities that, for each row in the test data frame, represent the likelihood of that person being positive for diabetes.
The trick then is to figure out the threshold value (aka “alpha value”) over which we would classify the person as being positive for diabetes. Most people will generally pick 0.5:
pos_neg <- ifelse(glm_preds > 0.5,"pos","neg")
# Then they would compare this against the known data
(my_conf <- table(predicted=pos_neg,actual=glm_test$diabetes))## actual
## predicted neg pos
## neg 89 20
## pos 11 33# Then they might use this table to compute an accuracy metric
estimated_accuracy <- sum(diag(my_conf))/sum(my_conf)
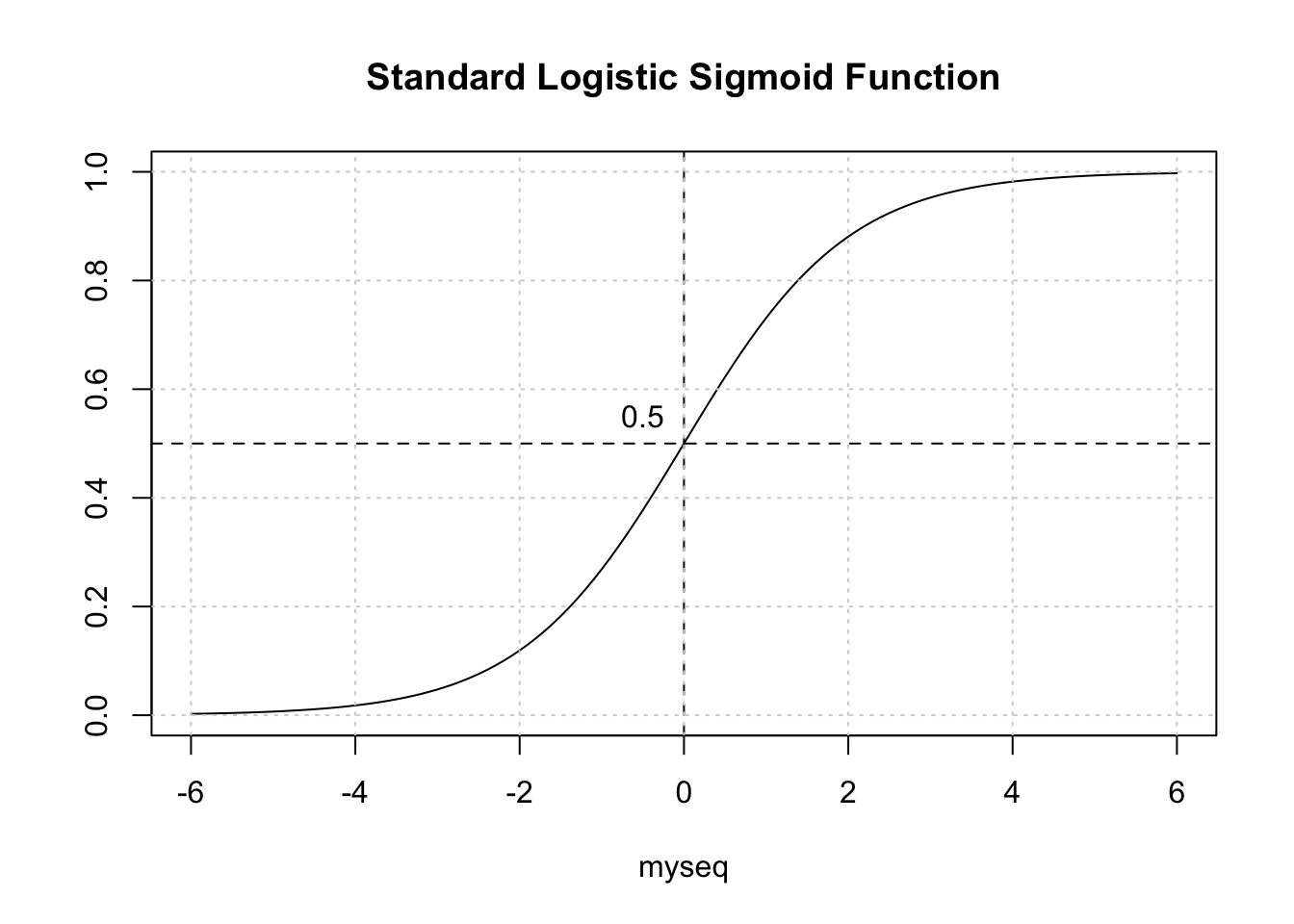
print(paste("Accuracy is",round(estimated_accuracy,2)))## [1] "Accuracy is 0.8"Is this okay ? Not really. To better address this question, we need to back up a bit and recall that we are dealing with a curve like the one below which is a sigmoid function. The idea is to take our probabilities, which range between 0 and 1, and then pick a threshold over which we would classify that person as being positive for diabetes.
6.4 Selecting The Correct Threshold / Alpha
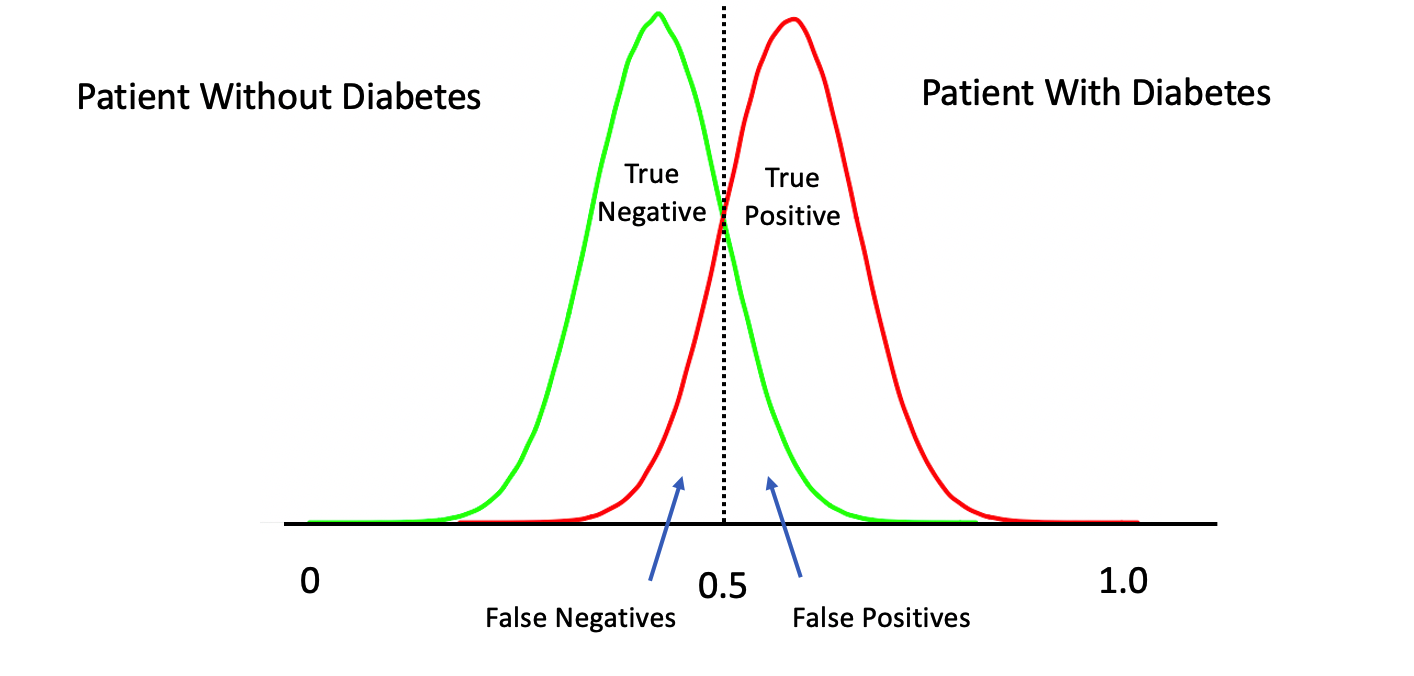
The temptation is to select 0.5 as the threshold such that if a returned probability exceeds 0.5 then we classify the associated subject as being “positive” for the disease. But then this assumes that the probabilities are distributed perfectly. This is frequently NOT the case though it doesn’t stop people from using 0.5. Here is another view of the situation.
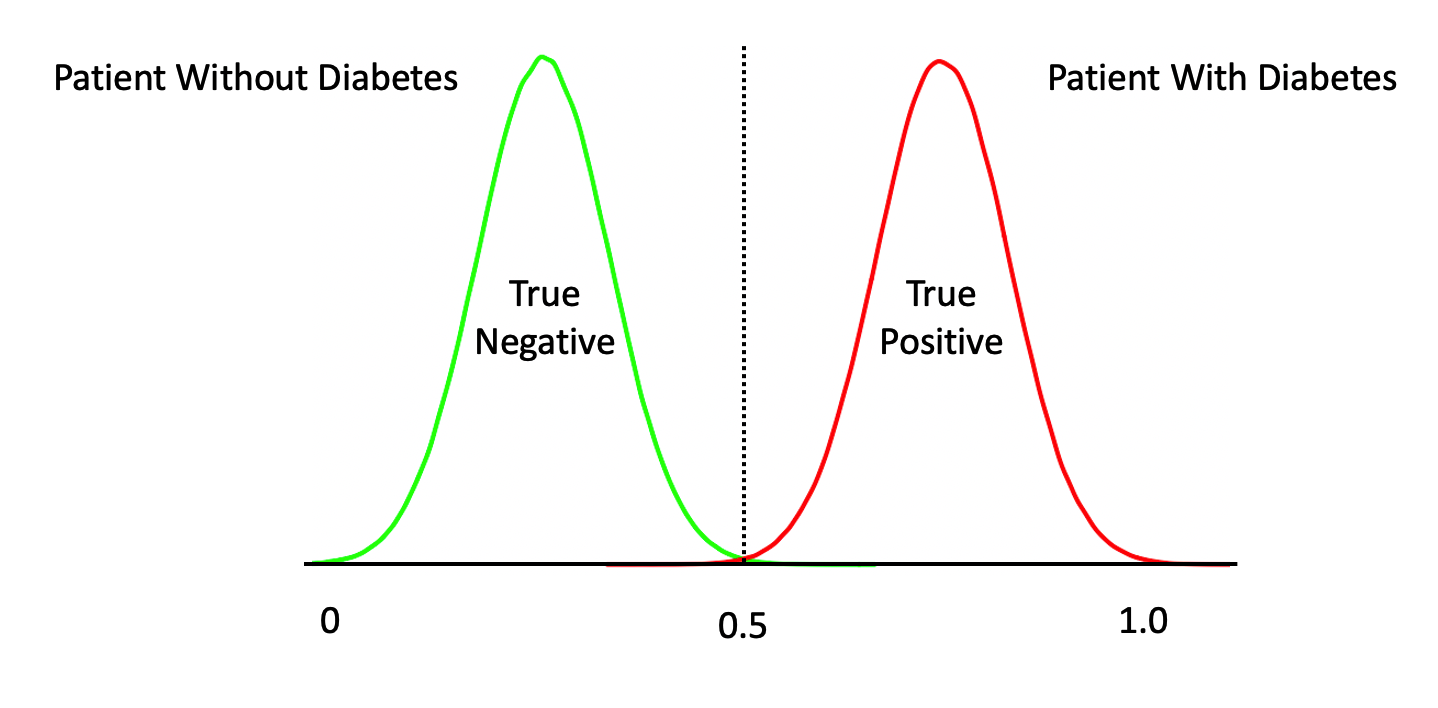
The above represents a perfect classifier wherein we can cleanly distinguish between True Positives and Negatives. Note that, the cutoff point is at 0.5 which represents an ideal case. However, in most situations, what we have is something like this:
6.4.1 Moving The Threshold
What happens if we move our threshold towards 0 ? We would definitely get more of the actual positive cases. What if we moved it to say 0.1 ? We would probably get ALL of the True Positives at the expense of getting a lot of False Positives.
What happens if we move our threshold towards 1 ? We would definitely get more of the actual negative cases. What if we moved it to say 0.9 ? We would probably get ALL of the True Negatives at the expense of getting a lot of False Negatives.
6.4.2 Distribution of Predicted Probabilities
We might first wish to look at the distribution of the returned probabilities before making a decision about where to set the threshold. You should now be able to clearly that simply selecting 0.5 in a general case might not be the best approach.
par(mfrow=c(1,2))
boxplot(glm_preds,
main="GLM Model Probabilities")
grid()
plot(glm_preds[order(glm_preds)],type="l",
main="Prediction Probabilities",ylab="probability",xlab="Patients")
grid()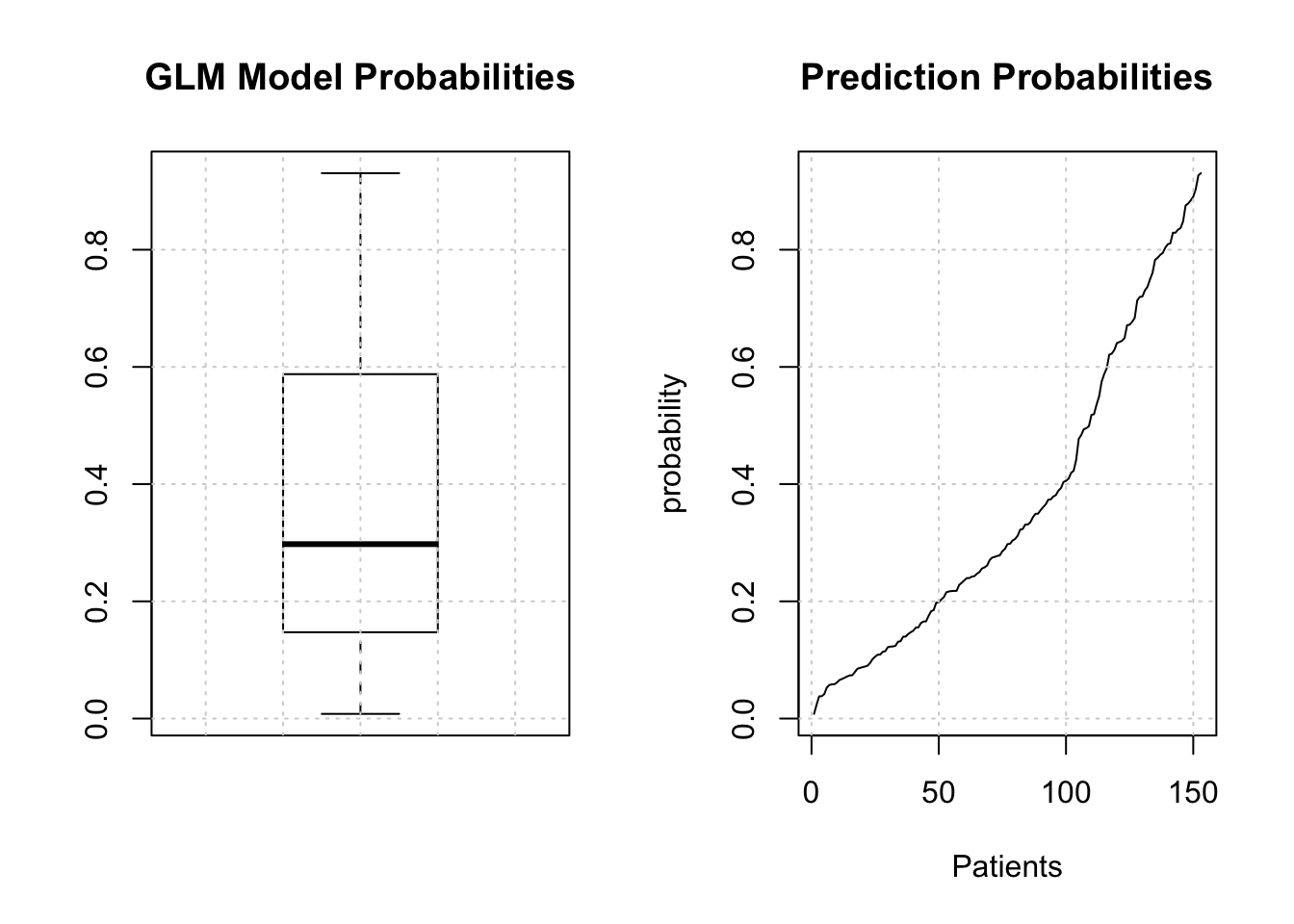
The median is somewhere around .25 so we could use that for now although we are just guessing.
glm_label_preds <- ifelse(glm_preds > 0.25,"pos","neg")
# We have to make the labels into a factor since
# the diabetes column is a factor in the original data dset
glm_label_preds <- factor(glm_label_preds,
levels = levels(glm_test[["diabetes"]]))
glm_label_preds[1:10]## 2 6 8 22 23 30 33 36 38 40
## neg neg pos pos pos pos neg neg pos pos
## Levels: neg pos6.5 Hypothesis Testing
Now, before we dig into the details our classifier, remember that most things in statistics and classification revolves around the idea of a hypothesis. In this case, the “null” hypothesis is that a patient does NOT have the disease whereas the alternative hypothesis is that they do. Well, for a statistician that’s a bit strong. Let’s just say that if there is enough evidence to reject the null hypothesis then we will.
Anyway, the larger idea is that we might apply our test to someone and subsequently determine, by mistake, that they have a disease when in fact they don’t.
- This would be an example of a "false positive" also known as a "Type I Error". It is also possible that we apply the test to someone and we say that the do not have the disease when they actually do.
- This is known as a "false negative" also known as a Type II Error" Here we fail to reject the null hypothesis for this person. A perfect test would have zero false positives and zero false negatives.

6.6 Confusion Matrix
So now we have our predictions in terms of actual labels that we could then use to compare to the actual labels that are stored in the “diabetes” column of the test data frame. This table provides the basis for computing a number of performance measures such as accuracy, precision, sensitivity, specificity and others. In predictive modeling we are always interested in how well any given model will perform on “new” data.
# How does this compare to the truth ?
my_confusion <- table(predicted = glm_label_preds,
actual = glm_test$diabetes)
my_confusion## actual
## predicted neg pos
## neg 59 6
## pos 41 47Let’s break this down since it is really important to know how to use this construct. First, we notice that there are N = 153 people in this study.

True Positives - With respect to the second row - we predicted that 47 people have the disease that actually do have it. You could then say that the number of TRUE POSITIVES (abbreviated as “TP”) is 47.
False Positives - We also predicted that 41 people have the condition when they in fact do not. We could then say that the number of FALSE POSITIVES, abbreviated as “FP”, is 41.
False Negatives - In the first row we predicted that 6 people do NOT have the disease/condition when they actually do. So you could say that the number of FALSE NEGATIVES (abbreviated as FN) is 6.
True Negatives - We also predicted that 59 people do not have the condition and they do not. So then the number of TRUE NEGATIVES (abbreviated as TN) is also 59.
6.6.1 Computing Performance Metrics
Now comes the fun part in that you might be concerned with specific metrics to assess the quality of your model in specific terms. Since our model, such as it is, seems to relate to the quality of a medical diagnostic we might be concerned with its accuracy, precision, and sensitivity.
The first two terms in particular are frequently used synonymously when they are not the same thing.Below is a graphic from Wikipedia which presents many (if not all) of the metrics that can be computed against a confusion matrix.
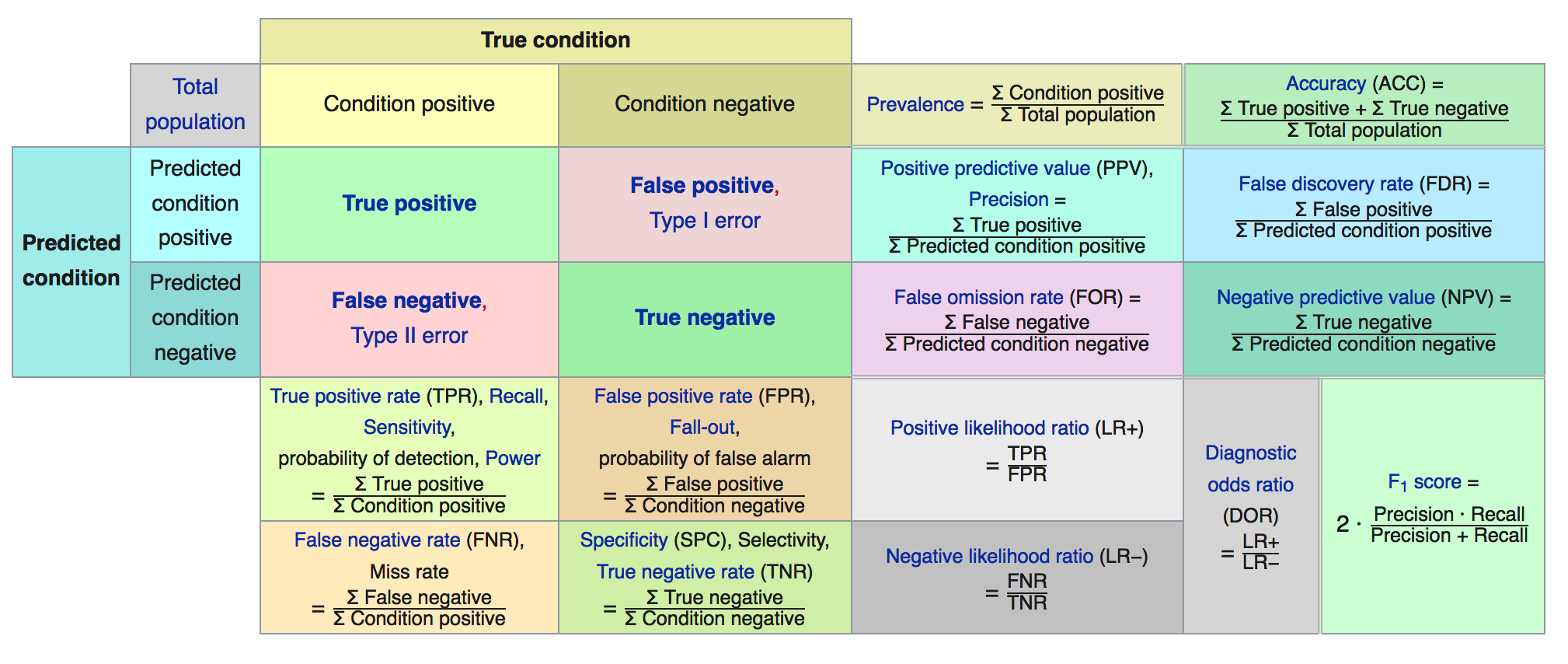
We’ll focus on some specific metrics as they will assist our understanding of how to assess a model.
## actual
## predicted neg pos
## neg 59 6
## pos 41 47## [1] 1536.6.1.1 Accuracy
So let’s take the number of observed True Positives and True Negatives, add them together, and divide them by the total number of patients in the study group to arrive at what is known as the Accuracy of our model. Another way to think of the denominator is as the sum of all observed results, True and False.
Accuracy = (TP + TN) / (TP + TN + FP + FN) = (59 + 47)/153 = 0.69
## [1] 0.696.6.1.2 Sensitivity
Sensitivity, also known as the True Positive rate, tells us how frequently we find a positive case given that it is actually positive. It is the number of True Positives (TP) divided by the sum of True Positives and False Negatives (which are actually Positives). This
Sensitivity = TP / (TP + FN) = 47 / (47 + 6) = 0.89
## [1] 0.89Sensitivity also has the synonyms of “recall” and “hit rate” which might be referenced depending on your domain on interest.
6.6.1.3 False Positive Rate
Just as there is the True Positive Rate there is a False Positive Rate. This tells us how likely it is we will falsely reject the null hypothesis which is a Type I error.
False Positive Rate = FP / (FP + TN) = 41 / (41 + 59) = .41
## [1] 0.416.6.1.4 Specificity
Specificity tells us how frequently we find a negative case given that it is actually negative. This is also known as the “True Negative Rate”
Specificity = TN / (TN + FP) = 59 / (59 + 41) = 0.59
specificity <- my_confusion[1,1] / (my_confusion[1,1]+ my_confusion[2,1])
(specificity %>% round(.,2))## [1] 0.596.6.1.5 Precision
How precise is the model ? Precision is a measure of the ability of a classification model to identify only the relevant data points. This is also known as Positive Predictive Value. We take the number of True Positives (TP) and divide that by the sum of True Positives (TP) and False Positives (FP). The denominator is the sum of row 2 in our matrix.
It is helpful to know that Precision is also known as the PPV “Positive Predictive Value” since it is concerned with the ratio of True Positives over the sum of all Positive related quantities including the False Positives. The larger the number of FP then the smaller the ratio which results in a lower precision.
Precision = TP / (TP + FP) = 47 / (47 + 41) = 0.53
## [1] 0.536.7 Picking the Right Metric
There are more ratios we could compute some of which might be more relevant to our classification issue. In reality, picking the “right” metric is a function of your domain of study. Frequently, the sensitivity and specificity are used in medical testing scenarios as is the false positive rate. But you should search the literature in your area of interest to determine what is commonly used. We could say much more about these metrics but we’ll keep it simple for now.
For now, we’ll use both the True Positive Rate and the False Positive Rate.
6.8 Wait. Where Are We ?
We’ve been doing a lot. We did the following:
- Built a model against the training data
- Used the model to make a prediction against the test data
- Took the probabilities from Step #2 and
- Selected a threshold / alpha value (e.g. .3) and
- Decided that probabilities over that threshold would be “pos”
- Created a table of outcomes (confusion matrix) to compare predictions vs reality
- Computed some important ratios
While this process was useful the resulting confusion matrix corresponded to just ONE particular threshold ? What if we had picked another value ? We would then get a different confusion matrix as well as different performance measures.
In effect we would have to repeat steps 4-7 all over again for each threshold !!!
Let’s find a way to generalize these steps. First, let’s create a function that allows us to compute the True Positive Rate (aka “Sensitivity”) and the False Positive Rate ( 1 - Specificity). If we apply it to our predictions from our example in progress, the output would be as follows.
get_tprfpr <- function(pred,true) {
myt <- table(pred,true)
tpr <- myt[2,2]/(myt[2,2]+myt[1,2])
fpr <- myt[2,1] / (myt[2,1] + myt[1,1])
return(c(tpr=tpr,fpr=fpr))
}
get_tprfpr(glm_label_preds,glm_test$diabetes)## tpr fpr
## 0.8867925 0.4100000We could now use this function to compute these metrics for any set of predictions vs actual outcomes. We could generalize this function to accept an alpha so we could explore the full probability domain (0 - 1) and then plot the TPR vs FPR. This is, in effect, creating something known as a ROC Curve aka Receiver Operating Characteristic Curve.
get_tprfpr <- function(thresh=.25,probs=glm_preds) {
diabetes <- ifelse(probs > thresh,"pos","neg")
myt <- table(diabetes,glm_test$diabetes)
tpr <- myt[2,2]/(myt[2,2]+myt[1,2])
fpr <- myt[2,1] / (myt[2,1] + myt[1,1])
return(c(tpr=tpr,fpr=fpr,alpha=thresh))
}
get_tprfpr(.30)## tpr fpr alpha
## 0.8113208 0.3200000 0.3000000## tpr fpr alpha
## 0.7358491 0.1600000 0.4000000Let’s look at a sequence of alpha values:
metrics <- t(sapply(seq(0.01,.95,.09),function(x) get_tprfpr(x)))
plot(tpr~fpr,metrics,
ylim=c(0,1),xlim=c(0,1),
main="Steve's Super Cool ROC Curve",
xlab="False Positve Rate (1-Specificity)",
ylab="True Positive Rate",type="l")
grid()
abline(a=0, b=1,lty=2)
# Put the associated threshold values on the plot to help you identify
# the right value to maximize the AUC (Area Under Curve)
text(metrics[,2],metrics[,1],labels=metrics[,3],cex=0.8)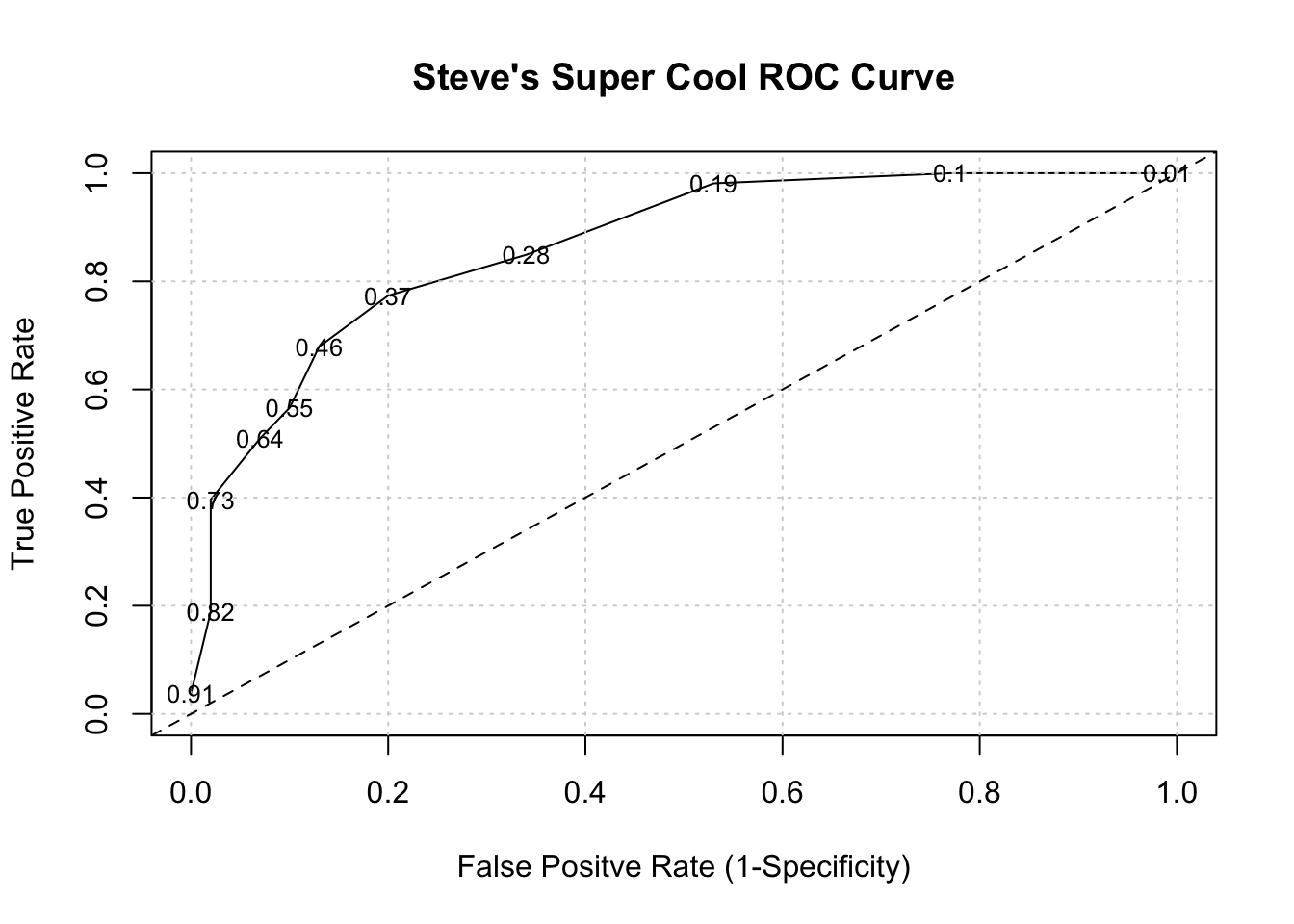
It turns out that area under an ROC curve is a measure of the usefulness of a test in general, where a greater area (with respect to TPR and FPR) means a more useful test. Ideally we would want the area under the curve (also known as “AUC”) to be as close to 1 as possible. The dashed line above represents a classifier that basically “guesses” the outcome (pos vs neg) using a “coin flip” mentality.
for (ii in c(0.01,.2,.3,.4)) {
perc <- sum(glm_preds > ii)/length(glm_preds)*100
mys <- paste(round(perc,2),"of prediction probabilities are greater than",ii)
cat(mys,"\n")
}## 99.35 of prediction probabilities are greater than 0.01
## 67.32 of prediction probabilities are greater than 0.2
## 49.02 of prediction probabilities are greater than 0.3
## 35.95 of prediction probabilities are greater than 0.4In case you are wondering, there is a command in R which will make the curve for you. We need to use the prediction PROBABILITES as part of the call to the colAUC function. We also pass in the actual labels for comparison.
# Use the colAUC function from the caTools package
pm_model_glm_probs <- predict(glm_model,glm_test,type="response")
caTools::colAUC(pm_model_glm_probs,glm_test$diabetes,plotROC=TRUE)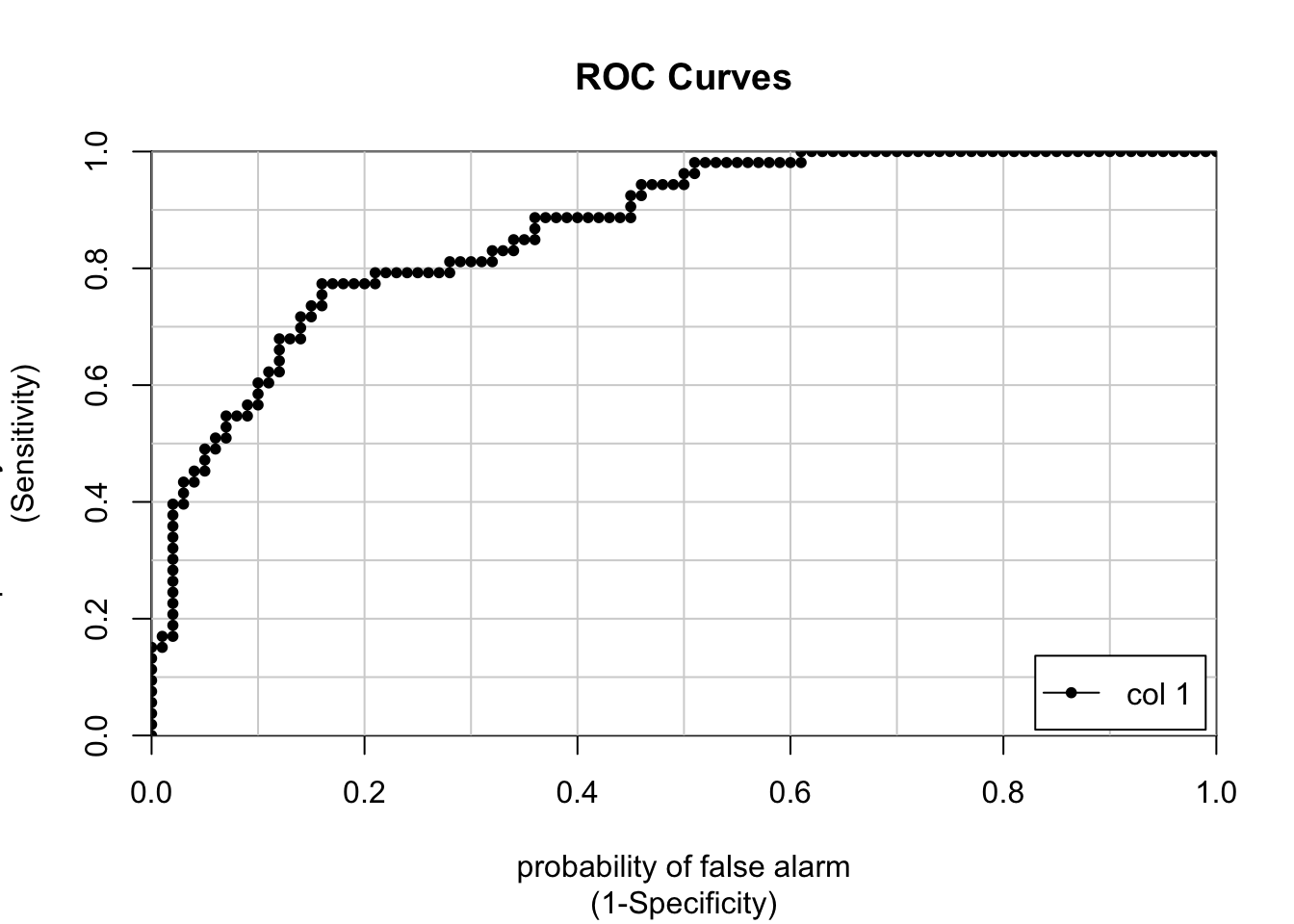
## [,1]
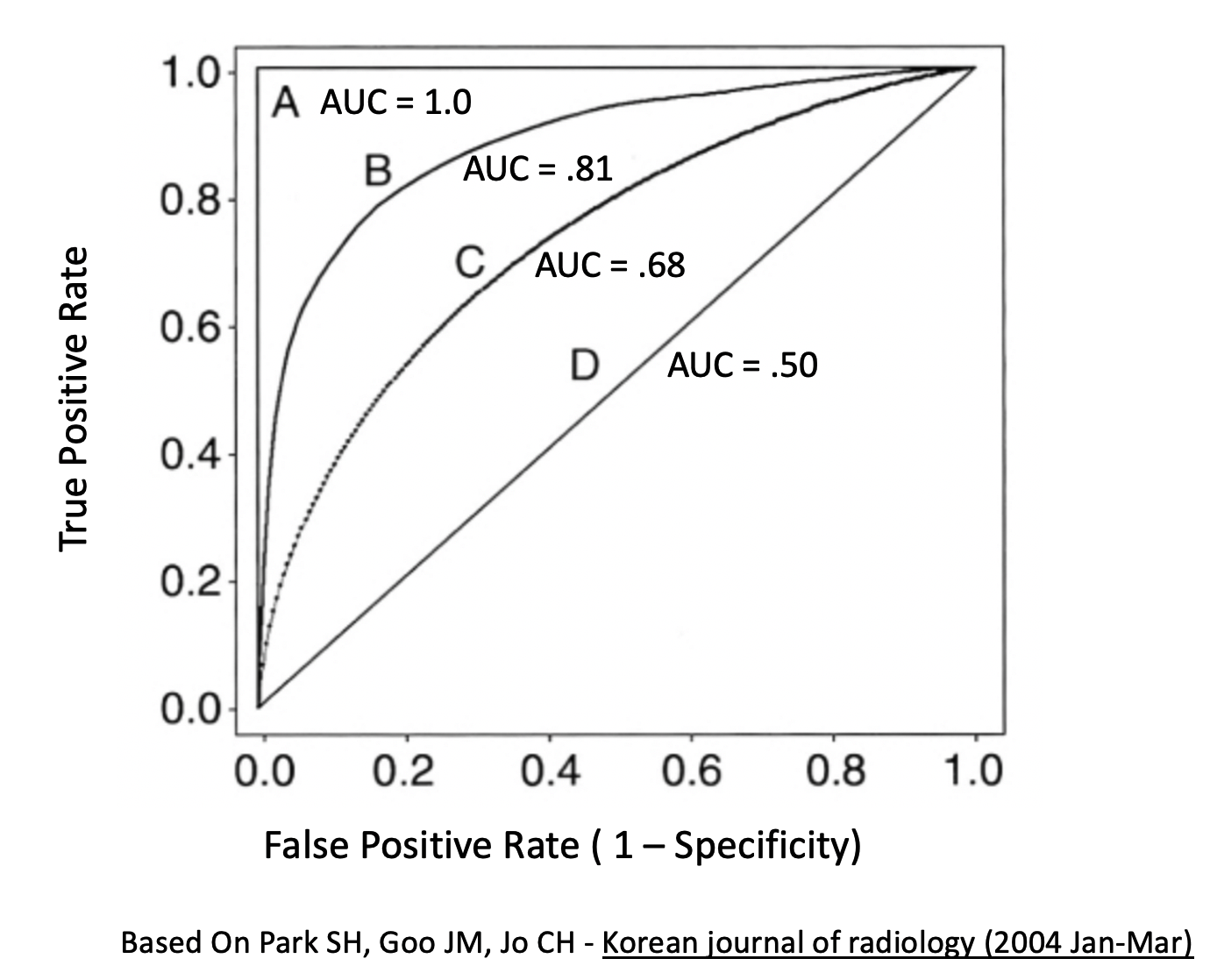
## neg vs. pos 0.8677358Here are some more examples of general curves including one that is “perfect”. B and C are okay where as D represents mere guessing.
Here is another view of determining how good a ROC curve is:
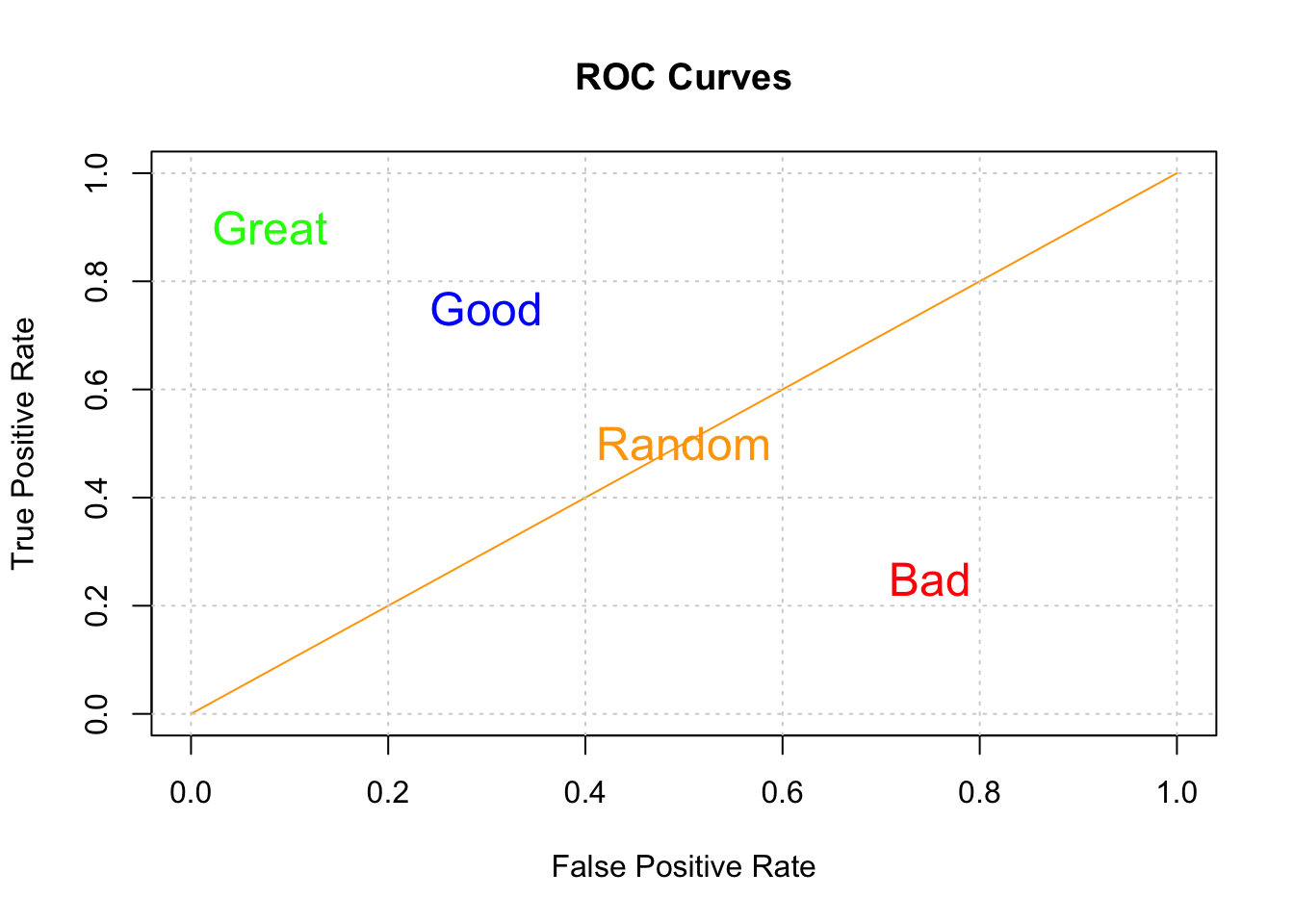
So, our classifier does better than that but certainly not perfectly. Now, we also care about the threshold that gives us a good balance between the TPR and FPR. I mean if we wanted a max AUC with no other concerns, we would also be accepting a very high FPR. So this is why looking at the curve is useful.
6.9 Other Ways To Compute The ROC Curve
So by now your head might be reeling from all the details and tedium associated with selecting alpha values, computing matrices, and plotting ROC curves though I it should be no surprise that R (as well as Python) has a number of functions that can compute these things for you.
As an example, if we wanted to plot the ROC curve we generated by hand we could use the ROCR package. It takes the probabilities returned by our first prediction object as well as the known labels in the glm_test data frame.
library(ROCR)
pred <- ROCR::prediction(predictions = glm_preds,
labels = glm_test$diabetes)
perf <- ROCR::performance(pred,
"tpr",
"fpr")
ROCR::plot(perf,colorize=T,
print.cutoffs.at=seq(0,1,by=0.1),
lwd=3,las=1,main="A Pretty ROC Curve")
abline(a = 0, b = 1)
grid()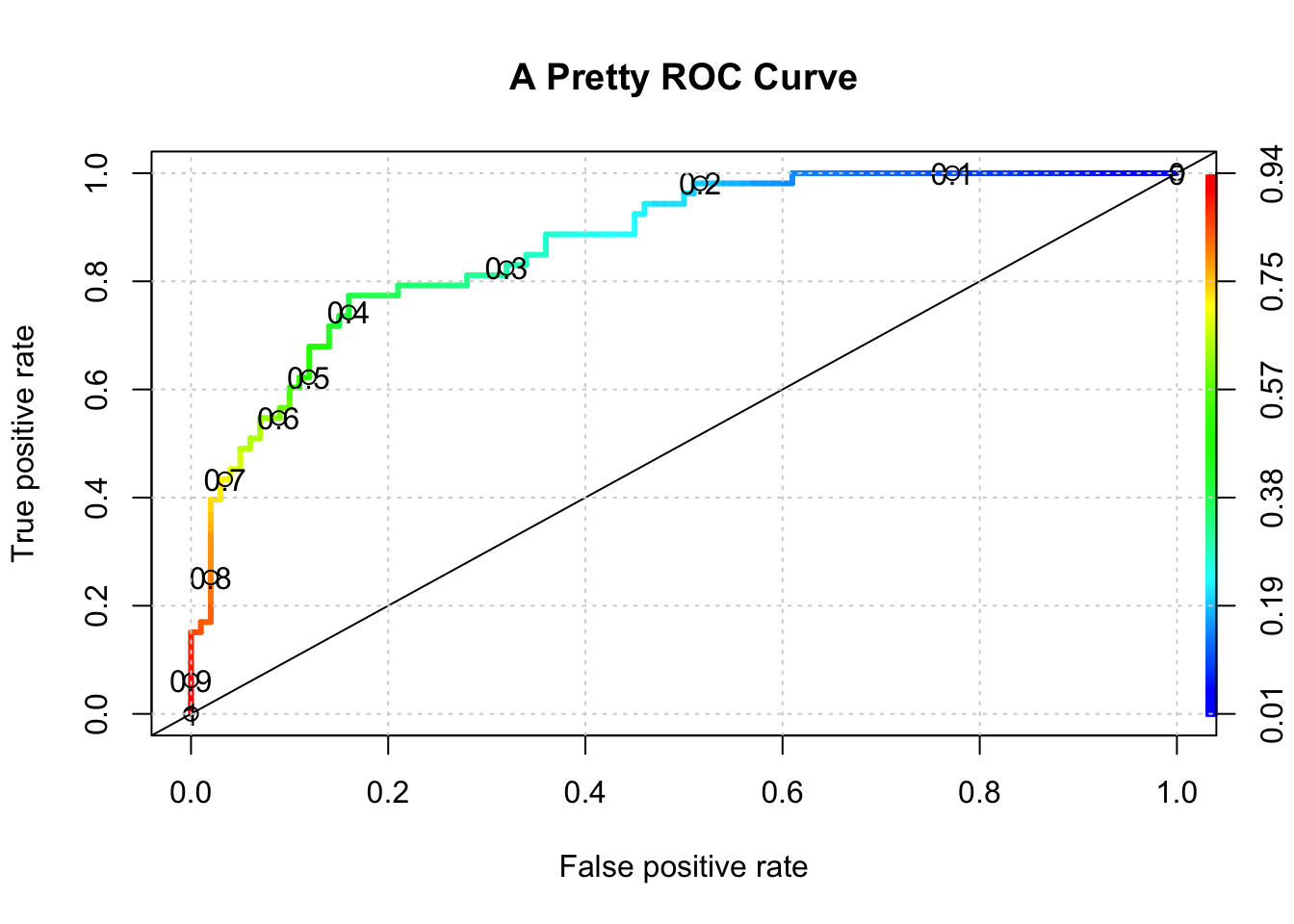
# Get the optimal AUC
auc_ROCR <- ROCR::performance(pred,measure="auc")
auc_ROCR <- auc_ROCR@y.values[[1]]
cat("Optimal AUC is: ",auc_ROCR,"\n")## Optimal AUC is: 0.8677358And if we wanted to see the auc associated with the “optimal” alpha we could use some functions to get that for us:
pm_model_glm_probs <- predict(glm_model,glm_test,type="response")
myRoc <- pROC::roc(diabetes~pm_model_glm_probs,
auc=TRUE,data=glm_test)
pROC::coords(myRoc, "best", ret = "threshold",transpose = TRUE)## threshold
## 0.3850002## tpr fpr alpha
## 0.7735849 0.1600000 0.3850002And while I’m at it, I might as well show you how easy it is to compute a confusion matrix corresponding to the ideal threshold.
glm_label_preds <- ifelse(glm_preds > 0.385,"pos","neg")
# We have to make the labels into a factor since
# the diabetes column is a factor in the original data dset
glm_label_preds <- factor(glm_label_preds,
levels = levels(glm_test[["diabetes"]]))# How does this compare to the truth ?
my_confusion <- table(predicted = glm_label_preds,
actual = glm_test$diabetes)
my_confusion## actual
## predicted neg pos
## neg 84 12
## pos 16 41We could use a function from the caret package called confusionMatrix to show us the relevant metrics although it can be a bit confusing (no pun intended) because it’s idea of what represents a “positive” and “negative” is not always what you expect.
## Confusion Matrix and Statistics
##
## actual
## predicted neg pos
## neg 84 12
## pos 16 41
##
## Accuracy : 0.817
## 95% CI : (0.7465, 0.8748)
## No Information Rate : 0.6536
## P-Value [Acc > NIR] : 6.204e-06
##
## Kappa : 0.6029
##
## Mcnemar's Test P-Value : 0.5708
##
## Sensitivity : 0.7736
## Specificity : 0.8400
## Pos Pred Value : 0.7193
## Neg Pred Value : 0.8750
## Prevalence : 0.3464
## Detection Rate : 0.2680
## Detection Prevalence : 0.3725
## Balanced Accuracy : 0.8068
##
## 'Positive' Class : pos
## 6.10 ROC Curve Summary
The above can be confusing although what you will soon discover is that being able to compute the AUC (Area Under Curve) will be sufficient to judge the quality of a model - well in general it’s a good start. The caret package can do that for you so you don’t need to use the various functions about to find that.
You might want to put up a ROC curve based on some predictions in which case you would still need to use one of the above functions. If you just want to see a basic ROC Curve then take this approach which will give you both the AUC and a ROC Curve albeit it much less “pretty” than the one above.