Chapter 5 Caret Package
By now you are probably fatigued with understanding the details of writing the code to split data, doing Cross Validation, storing the results, and looking at descriptive stats associated with the resulting RMSE. And this is all before considering the various parameters associated with whatever method we wish to implement.
Each function has its own set of requirements which may not extend to other functions. What we need (well, what we would like) is a framework to streamline this process and automate it as much as possible but not at the expense of understanding the results.
The caret (Classification And Regression Training) package provides a uniform interface for calling different algorithms while simplifying the data splitting and RMSE calculation. It supports many different model types and also provides the ability to tune hyper parameters. Here are some of the features:
- Streamlined and consistent syntax to implement any of the 238 different methods using a single function
- Easy data splitting to simplify the creation of train / test pairs
- Realistic model estimates through built-in resampling
- Convenient feature importance determination
- Easy selection of different performance metrics (e.g. “ROC”,“Accuracy”, “Sensitivity”)
- Automated and semi-automated parameter tuning
- Simplified comparison of different models
Note that caret provides a nice wrapper around the various modeling functions. Since each underlying model is itself a standalone R package and associated set of functions you can always call them directly should you prefer that approach. That’s what we have been doing in the earlier part of this text.
5.1 Putting caret To Work
It’s easy to get lost in all that we have been doing so let’s review what the typical predictive modeling workflow will look like:
- Data Import (.csv., extraction from a database, etc)
- Some Data Visualization
Data Prep (We haven’t done any of this yet) - Missing, imputation - Scaling - Create dummy variables / one hot encoding - Dimensionality Reduction
Data Splitting (training / test) - Determine split ration - K-Fold Cross Validation (repeated)
Modeling / Prediction
Evaluation
To do step 5 requires some predefined idea of a performance metric. We have been using RMSE and will continue to do so as we rework some of the previous examples using the caret package.
5.2 Back To The Beginning
It is implied that in predictive modeling the ultimate goal is to generate a model that could be reasonably applied to new data. As we have learned, it is best to train any model on a data set that has been (re)sampled in some way (e.g. K Fold CV) which should help provide a more realistic estimate of “out of sample” error.
In our earliest example we tried to predict the MPG from mtcars using a basic linear modeling function. The caret package provides a uniform way to do this which allows us to easily substitute in alternative functions without having to majorly change our code.
We can call the train function in such a way as to pass in any arguments that are specific to a given method though in a way we could do for other methods. We can also tell the train function that we want to evaluate RMSE as a performance measure. That is, it will “know” that our primary performance measure for a model is RMSE. Before we do that, however, we’ll make a test / train pair. The caret package provides ways to do that.
5.3 Splitting
createDataPartition can be used to create test and train data splits according to some proportion. There is a function called createFolds can be used to generate balanced cross–validation groupings from a set of data. createResample can be used to make simple bootstrap samples. For now, we’ll just stick with createDataPartition for creating a test/train pair.
set.seed(123) # Make this example reproducible
idx <- createDataPartition(mtcars$mpg, p = .8,
list = FALSE,
times = 1)
head(idx)## Resample1
## [1,] 1
## [2,] 3
## [3,] 4
## [4,] 5
## [5,] 6
## [6,] 8## [1] 28## [1] 45.4 Calling The train() Function
To actually create a model involves use of the train function which is the premier function in the caret package. It does what it name suggests - train models. Note that we tell it:
- What we are trying to predict (a formula)
- What our data set is (e.g. Train)
- The desired method (“lm”)
- Note that this method name MUST match an existing R modeling function
- A desired scoring metric. In this case we seek to minimize RMSE on future predictions
set.seed(123) # Make this example reproducible
lm_fit <- train(mpg~wt,
data=Train,
method="lm",
metric="RMSE")We get back a single object that contains a lot of information that could help us figure out if the model is worth anything. But first, just type the name of fit object to see what you can see. This shows us information that has been derived from some re sampling activity across a number of bootstrapped samples.
## Linear Regression
##
## 28 samples
## 1 predictor
##
## No pre-processing
## Resampling: Bootstrapped (25 reps)
## Summary of sample sizes: 28, 28, 28, 28, 28, 28, ...
## Resampling results:
##
## RMSE Rsquared MAE
## 2.676533 0.79883 2.138882
##
## Tuning parameter 'intercept' was held constant at a value of TRUE##
## Call:
## lm(formula = .outcome ~ ., data = dat)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.890 -2.163 -0.091 1.361 7.140
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 36.2505 1.7925 20.223 < 2e-16 ***
## wt -4.9957 0.5249 -9.516 5.89e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.75 on 26 degrees of freedom
## Multiple R-squared: 0.7769, Adjusted R-squared: 0.7684
## F-statistic: 90.56 on 1 and 26 DF, p-value: 5.889e-10Note that the summary of the model “summary(lm_fit)” returns the same information that would be returned had we used the lm function directly as we did in the previous section. The point is that the train function doesn’t not seek to replace or obscure the resulting model in any way. We can always get whatever information we need from it. So let’s apply this model to the test data frame
## [1] 4.622936There is more here than meets the eye.
## [1] "method" "modelInfo" "modelType" "results" "pred"
## [6] "bestTune" "call" "dots" "metric" "control"
## [11] "finalModel" "preProcess" "trainingData" "resample" "resampledCM"
## [16] "perfNames" "maximize" "yLimits" "times" "levels"
## [21] "terms" "coefnames" "xlevels"## List of 28
## $ method : chr "boot"
## $ number : num 25
## $ repeats : logi NA
## $ search : chr "grid"
## $ p : num 0.75
## $ initialWindow : NULL
## $ horizon : num 1
## $ fixedWindow : logi TRUE
## $ skip : num 0
## $ verboseIter : logi FALSE
## $ returnData : logi TRUE
## $ returnResamp : chr "final"
## $ savePredictions : chr "none"
## $ classProbs : logi FALSE
## $ summaryFunction :function (data, lev = NULL, model = NULL)
## $ selectionFunction: chr "best"
## $ preProcOptions :List of 6
## $ sampling : NULL
## $ index :List of 25
## $ indexOut :List of 25
## $ indexFinal : NULL
## $ timingSamps : num 0
## $ predictionBounds : logi [1:2] FALSE FALSE
## $ seeds :List of 26
## $ adaptive :List of 4
## $ trim : logi FALSE
## $ allowParallel : logi TRUE
## $ yLimits : num [1:2] 9.3 33.5Check out the some of the model characteristics
##
## Call:
## lm(formula = .outcome ~ ., data = dat)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.890 -2.163 -0.091 1.361 7.140
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 36.2505 1.7925 20.223 < 2e-16 ***
## wt -4.9957 0.5249 -9.516 5.89e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.75 on 26 degrees of freedom
## Multiple R-squared: 0.7769, Adjusted R-squared: 0.7684
## F-statistic: 90.56 on 1 and 26 DF, p-value: 5.889e-10## [1] 0.7769458We can go right to the final Model which contains the information for the
##
## Call:
## lm(formula = .outcome ~ ., data = dat)
##
## Coefficients:
## (Intercept) wt
## 36.250 -4.996So it looks like caret did some re sampling for us by default. Actually, it was bootstrap sampling that we discussed earlier. However, we can specify cross fold validation if we wanted to. This requires a slightly more involved form of the train function.
You can influence the train function by passing a “special” list / object to it via the trControl argument. This gets a bit confusing because the primary function to train models is called train and the command used to create the special is called trainControl and the argument in the train function is called trControl. With use, it becomes easier to remember the difference though at first it’s confusing.
Here we train the model as before but specifically requesting a Cross Fold Validation method. We are requesting verbose output.
control <- trainControl(method = "cv", # Cross Fold
number = 5, # 5 Folds
verboseIter = TRUE) # Verbose
# Train the model
set.seed(123) # Make this example reproducible
my_lm <- train(
mpg ~ .,
Train,
method = "lm",
metric = "RMSE",
trControl = control
)## + Fold1: intercept=TRUE
## - Fold1: intercept=TRUE
## + Fold2: intercept=TRUE
## - Fold2: intercept=TRUE
## + Fold3: intercept=TRUE
## - Fold3: intercept=TRUE
## + Fold4: intercept=TRUE
## - Fold4: intercept=TRUE
## + Fold5: intercept=TRUE
## - Fold5: intercept=TRUE
## Aggregating results
## Fitting final model on full training setSo the object returned from caret gives us an estimate of how well the model will perform (based on RMSE) for out of sample data.
## Linear Regression
##
## 28 samples
## 10 predictors
##
## No pre-processing
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 22, 22, 23, 22, 23
## Resampling results:
##
## RMSE Rsquared MAE
## 2.955532 0.7487594 2.528231
##
## Tuning parameter 'intercept' was held constant at a value of TRUE## [1] 4.808981We could also repeat the 5 times CV validation an arbitrary number of times to generate greater confidence in the RMSE estimates returned by the model. Remember, a major reason for using K Fold validation is to better estimate the out of sample error by holding out a portion of the data frame being trained upon.
control <- trainControl(method = "repeatedcv", # Repeated Cross Fold
number = 3, # 3 Folds
repeats = 3, # Repeats
verboseIter = FALSE) # Verbose
set.seed(123) # Make this example reproducible
my_lm <- train(
mpg ~ .,
Train,
method = "lm",
metric = "RMSE",
trControl = control
)
Metrics::rmse(Test$mpg,predict(my_lm,Test))## [1] 4.8089815.5 Reproducible Results
So this is where using a package like caret really pays off in that not only does it provide a nice, consistent front end for a large number of methods, it gives you back an object containing all of the results plus all thing used to provide the final estimate on out of band error.
While digging in deeper into the object can be scary, it does pay off to spend time looking at it. Think of it this way, if you don’t use something like caret then you will have to write your own loops to keep track of, for example, the RMSE resulting from each train/test pair in a cross fold validation. This of course is fine but caret makes it easier. Let’s study the previous example in greater detail.
To get the best result (e.g. RMSE, R-Squared, MAE) directly:
## intercept RMSE Rsquared MAE RMSESD RsquaredSD MAESD
## 1 TRUE 4.574962 0.6092634 3.584692 2.811159 0.2692945 1.881702To see the results coming from each train / test pair using to build the final Out of Sample Error estimate. Why are there 9 rows here ?
## RMSE Rsquared MAE Resample
## 1 3.217212 0.68744503 2.744463 Fold1.Rep1
## 2 5.348479 0.27930338 3.923923 Fold2.Rep1
## 3 5.670200 0.48061619 4.860719 Fold3.Rep1
## 4 2.346548 0.83748766 1.989082 Fold1.Rep2
## 5 3.220792 0.76252308 2.511865 Fold2.Rep2
## 6 4.150818 0.74640561 3.858077 Fold3.Rep2
## 7 2.386493 0.86674237 1.915139 Fold1.Rep3
## 8 3.438640 0.73519906 2.592498 Fold2.Rep3
## 9 11.395476 0.08764857 7.866464 Fold3.Rep3Given that this is the underlying information that was used to build the ultimate out of sample error estimate, we should be able to take the average of the RMSE column which should match what we get in the final result.
## [1] 3.217212 5.348479 5.670200 2.346548 3.220792 4.150818 2.386493
## [8] 3.438640 11.395476## [1] 4.574962## [1] 4.574962The object is even more complete in that it provides you with access to the underlying sampled data used to generate the intermediate train / test and final results. The following will give us the row numbers of the training data used per iteration.
## $Fold1.Rep1
## [1] 1 3 7 8 9 10 11 12 13 14 16 17 18 20 21 22 24 25 28
##
## $Fold2.Rep1
## [1] 2 4 5 6 7 8 10 13 14 15 19 22 23 24 25 26 27 28
##
## $Fold3.Rep1
## [1] 1 2 3 4 5 6 9 11 12 15 16 17 18 19 20 21 23 26 27
##
## $Fold1.Rep2
## [1] 1 2 4 6 7 8 9 10 14 15 16 17 18 19 20 22 24 27
##
## $Fold2.Rep2
## [1] 1 3 5 6 7 9 10 11 12 13 15 17 20 21 22 23 25 26 28
##
## $Fold3.Rep2
## [1] 2 3 4 5 8 11 12 13 14 16 18 19 21 23 24 25 26 27 28
##
## $Fold1.Rep3
## [1] 1 4 6 7 8 11 13 15 16 19 20 21 22 24 25 26 27 28
##
## $Fold2.Rep3
## [1] 2 3 5 6 9 10 11 12 14 17 18 19 20 21 23 25 26 27 28
##
## $Fold3.Rep3
## [1] 1 2 3 4 5 7 8 9 10 12 13 14 15 16 17 18 22 23 24The following will give us the row numbers of the corresponding test data used per iteration. The general idea here is that you could recreate the final result by writing your own code if you were asked to do so.
## $Resample1
## [1] 2 4 5 6 15 19 23 26 27
##
## $Resample2
## [1] 1 3 9 11 12 16 17 18 20 21
##
## $Resample3
## [1] 7 8 10 13 14 22 24 25 28
##
## $Resample4
## [1] 3 5 11 12 13 21 23 25 26 28
##
## $Resample5
## [1] 2 4 8 14 16 18 19 24 27
##
## $Resample6
## [1] 1 6 7 9 10 15 17 20 22
##
## $Resample7
## [1] 2 3 5 9 10 12 14 17 18 23
##
## $Resample8
## [1] 1 4 7 8 13 15 16 22 24
##
## $Resample9
## [1] 6 11 19 20 21 25 26 27 285.6 One Size Fits All
So this is where things get interesting. If we wanted to use another method such as Random Forests, we do NOT have to change much at all. We just provide the name of the desired method which in this case, is ranger which is a function to create Random Forests.
control <- trainControl(method = "cv",
number = 5)
set.seed(123) # Make this example reproducible
my_ranger <- train(
mpg ~ .,
Train,
method = "ranger",
metric = "RMSE",
trControl = control
)
my_ranger## Random Forest
##
## 28 samples
## 10 predictors
##
## No pre-processing
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 22, 22, 23, 22, 23
## Resampling results across tuning parameters:
##
## mtry splitrule RMSE Rsquared MAE
## 2 variance 2.587753 0.9017899 2.180380
## 2 extratrees 2.694316 0.8805852 2.297226
## 6 variance 2.490290 0.9091406 2.147651
## 6 extratrees 2.608913 0.8938029 2.240797
## 10 variance 2.535569 0.9107767 2.186020
## 10 extratrees 2.523521 0.8992038 2.170427
##
## Tuning parameter 'min.node.size' was held constant at a value of 5
## RMSE was used to select the optimal model using the smallest value.
## The final values used for the model were mtry = 6, splitrule = variance
## and min.node.size = 5.## [1] 2.2884125.7 Alternative Calling Sequence
It is native to R to want to use a formula when specifying the goal of the modeling process. We’ve been using something along the lines of “mpg ~ .” because R uses this format for many different statistical functions. However, it is also possible to specify the predictor variables as X and the predicted variable as Y. In the above example, this would look like:
my_ctrl <- trainControl(
method = "cv",
number = 3,
verboseIter = FALSE
)
my_ranger <- train(
x = Train[,-1], # Everything BUT the MPG column
y = Train[,1], # The MPG column
method = "ranger",
tuneLength = 6,
trControl = my_ctrl
)
my_ranger## Random Forest
##
## 28 samples
## 10 predictors
##
## No pre-processing
## Resampling: Cross-Validated (3 fold)
## Summary of sample sizes: 19, 18, 19
## Resampling results across tuning parameters:
##
## mtry splitrule RMSE Rsquared MAE
## 2 variance 2.890146 0.8056424 2.266813
## 2 extratrees 2.926584 0.7983939 2.326078
## 3 variance 2.843515 0.8124454 2.219626
## 3 extratrees 2.884787 0.8097881 2.310120
## 5 variance 2.830262 0.8086326 2.217911
## 5 extratrees 2.887976 0.8122192 2.317901
## 6 variance 2.819049 0.8125409 2.190555
## 6 extratrees 2.972158 0.7987946 2.378725
## 8 variance 2.822495 0.8085079 2.214570
## 8 extratrees 2.944229 0.7993095 2.365574
## 10 variance 2.834211 0.8025443 2.247054
## 10 extratrees 2.951646 0.8008366 2.357687
##
## Tuning parameter 'min.node.size' was held constant at a value of 5
## RMSE was used to select the optimal model using the smallest value.
## The final values used for the model were mtry = 6, splitrule = variance
## and min.node.size = 5.## [1] 2.3387025.8 Hyperparameters
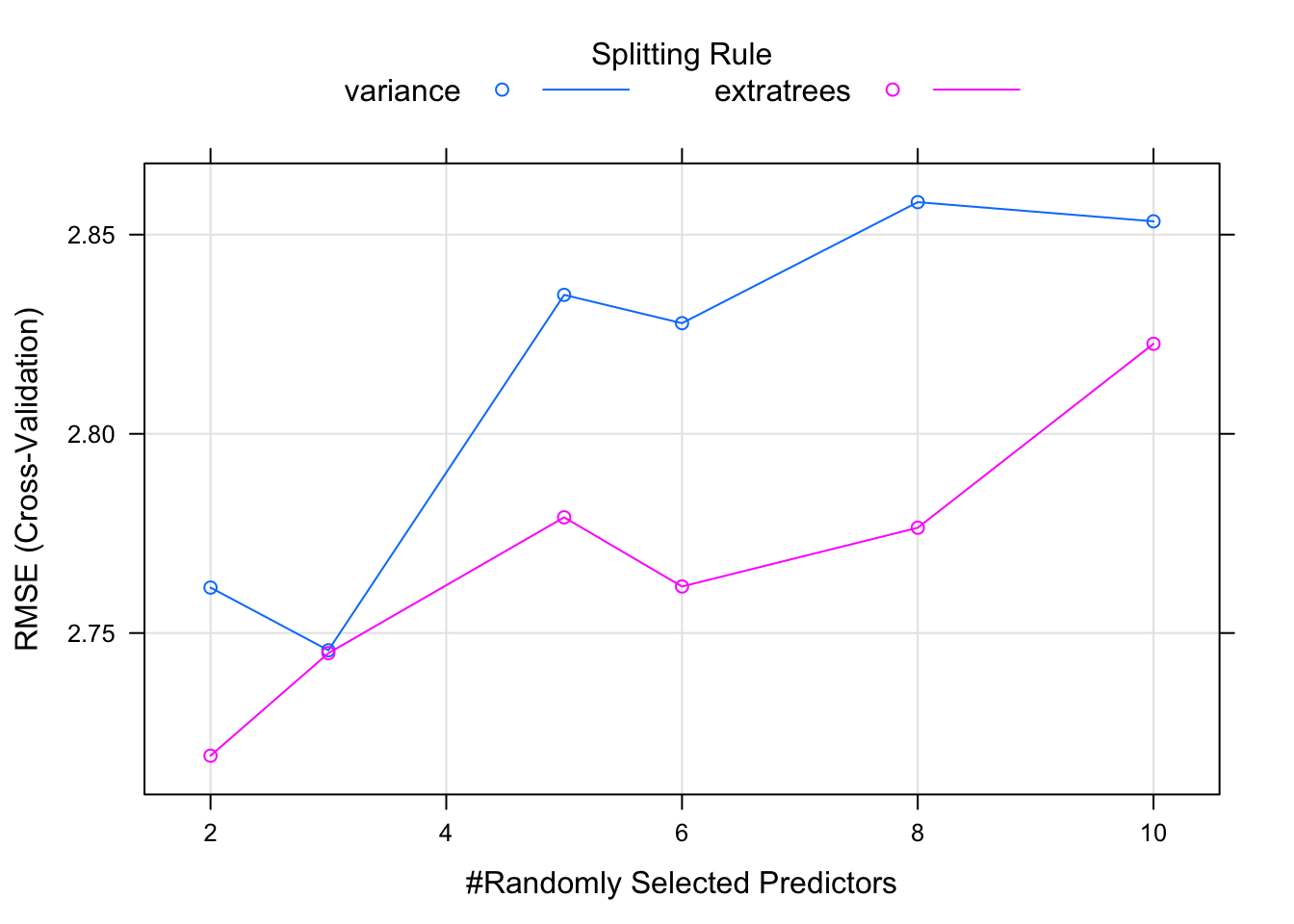
This model returns more information than say the lm function because this method uses something called “hyperparameters” which are arguments to a given method that gets set before you call the method. In this case there are two hyperparameters called mtry and splitrule that assume default variables if we don’t supply values.
We can get a plot of how the RMSE and R squared value varied with different values of mtry as well the splitrule. Here we see that an mtry value of 6 randomly selected columns / variables provides the lowest RMSE.
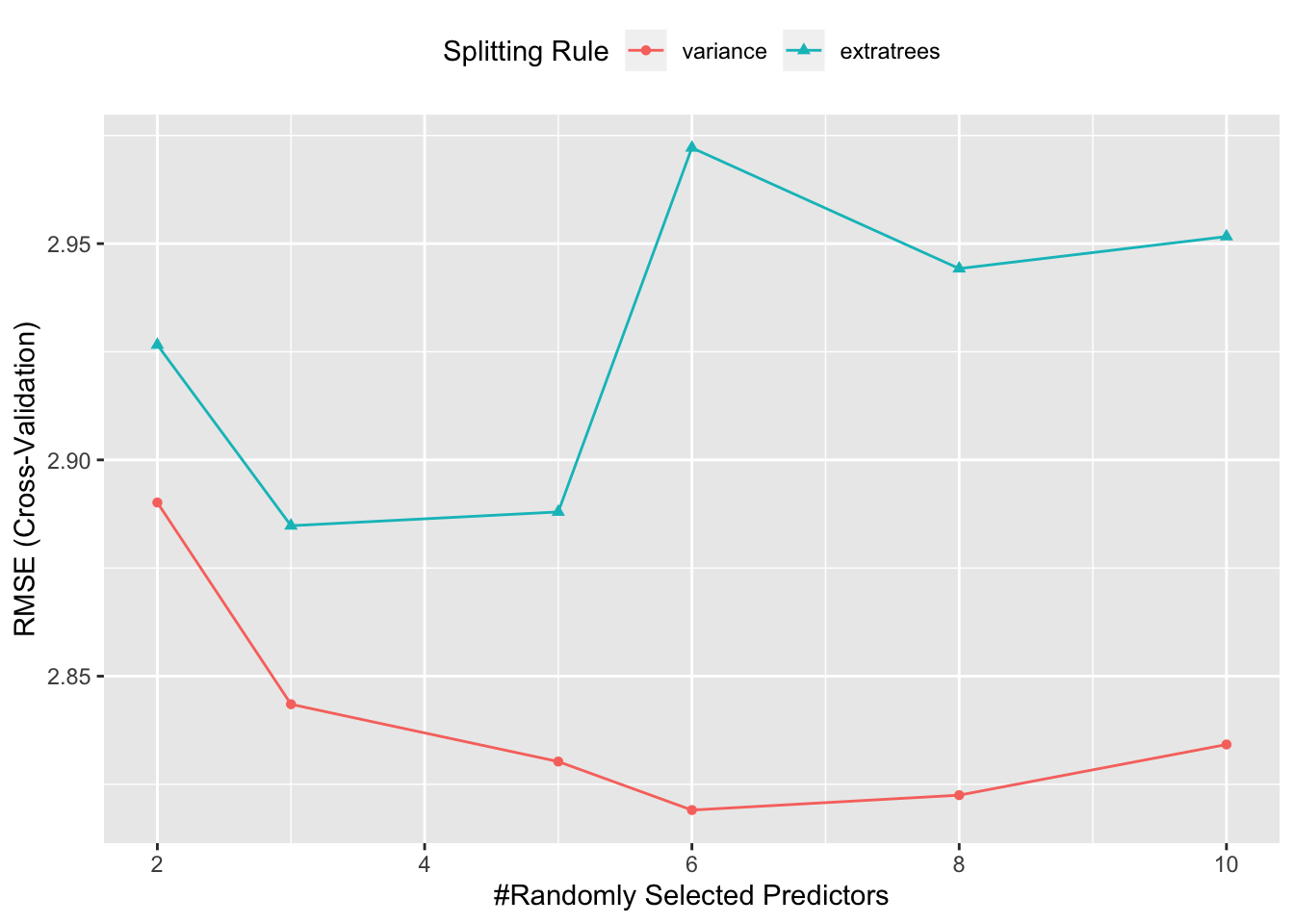
We can use the tuneLength argument to tell the train function to use N different values of mtry which is a hyperparameter to the randomForest package. The value relates to the number of columns in the data frame. We have 11 total and we are trying to predict one of them (mpg). So we can tell the train function to randomly select N variables (up to 10) when a tree is split.
my_ctrl <- trainControl(
method = "cv",
number = 5,
verboseIter = TRUE
)
set.seed(123) # Make this example reproducible
my_rf <- train(
mpg ~ .,
Train,
method = "rf",
tuneLength = 9, # We'll use 9 different values
trControl = my_ctrl
)## + Fold1: mtry= 2
## - Fold1: mtry= 2
## + Fold1: mtry= 3
## - Fold1: mtry= 3
## + Fold1: mtry= 4
## - Fold1: mtry= 4
## + Fold1: mtry= 5
## - Fold1: mtry= 5
## + Fold1: mtry= 6
## - Fold1: mtry= 6
## + Fold1: mtry= 7
## - Fold1: mtry= 7
## + Fold1: mtry= 8
## - Fold1: mtry= 8
## + Fold1: mtry= 9
## - Fold1: mtry= 9
## + Fold1: mtry=10
## - Fold1: mtry=10
## + Fold2: mtry= 2
## - Fold2: mtry= 2
## + Fold2: mtry= 3
## - Fold2: mtry= 3
## + Fold2: mtry= 4
## - Fold2: mtry= 4
## + Fold2: mtry= 5
## - Fold2: mtry= 5
## + Fold2: mtry= 6
## - Fold2: mtry= 6
## + Fold2: mtry= 7
## - Fold2: mtry= 7
## + Fold2: mtry= 8
## - Fold2: mtry= 8
## + Fold2: mtry= 9
## - Fold2: mtry= 9
## + Fold2: mtry=10
## - Fold2: mtry=10
## + Fold3: mtry= 2
## - Fold3: mtry= 2
## + Fold3: mtry= 3
## - Fold3: mtry= 3
## + Fold3: mtry= 4
## - Fold3: mtry= 4
## + Fold3: mtry= 5
## - Fold3: mtry= 5
## + Fold3: mtry= 6
## - Fold3: mtry= 6
## + Fold3: mtry= 7
## - Fold3: mtry= 7
## + Fold3: mtry= 8
## - Fold3: mtry= 8
## + Fold3: mtry= 9
## - Fold3: mtry= 9
## + Fold3: mtry=10
## - Fold3: mtry=10
## + Fold4: mtry= 2
## - Fold4: mtry= 2
## + Fold4: mtry= 3
## - Fold4: mtry= 3
## + Fold4: mtry= 4
## - Fold4: mtry= 4
## + Fold4: mtry= 5
## - Fold4: mtry= 5
## + Fold4: mtry= 6
## - Fold4: mtry= 6
## + Fold4: mtry= 7
## - Fold4: mtry= 7
## + Fold4: mtry= 8
## - Fold4: mtry= 8
## + Fold4: mtry= 9
## - Fold4: mtry= 9
## + Fold4: mtry=10
## - Fold4: mtry=10
## + Fold5: mtry= 2
## - Fold5: mtry= 2
## + Fold5: mtry= 3
## - Fold5: mtry= 3
## + Fold5: mtry= 4
## - Fold5: mtry= 4
## + Fold5: mtry= 5
## - Fold5: mtry= 5
## + Fold5: mtry= 6
## - Fold5: mtry= 6
## + Fold5: mtry= 7
## - Fold5: mtry= 7
## + Fold5: mtry= 8
## - Fold5: mtry= 8
## + Fold5: mtry= 9
## - Fold5: mtry= 9
## + Fold5: mtry=10
## - Fold5: mtry=10
## Aggregating results
## Selecting tuning parameters
## Fitting mtry = 6 on full training set## Random Forest
##
## 28 samples
## 10 predictors
##
## No pre-processing
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 22, 22, 23, 22, 23
## Resampling results across tuning parameters:
##
## mtry RMSE Rsquared MAE
## 2 2.579696 0.8997291 2.181764
## 3 2.543545 0.9002549 2.181950
## 4 2.538643 0.9059724 2.193849
## 5 2.467108 0.9142192 2.129060
## 6 2.457545 0.9203487 2.130067
## 7 2.510544 0.9103018 2.168747
## 8 2.541710 0.9096472 2.210990
## 9 2.539938 0.9136301 2.198482
## 10 2.592113 0.9070706 2.214741
##
## RMSE was used to select the optimal model using the smallest value.
## The final value used for the model was mtry = 6.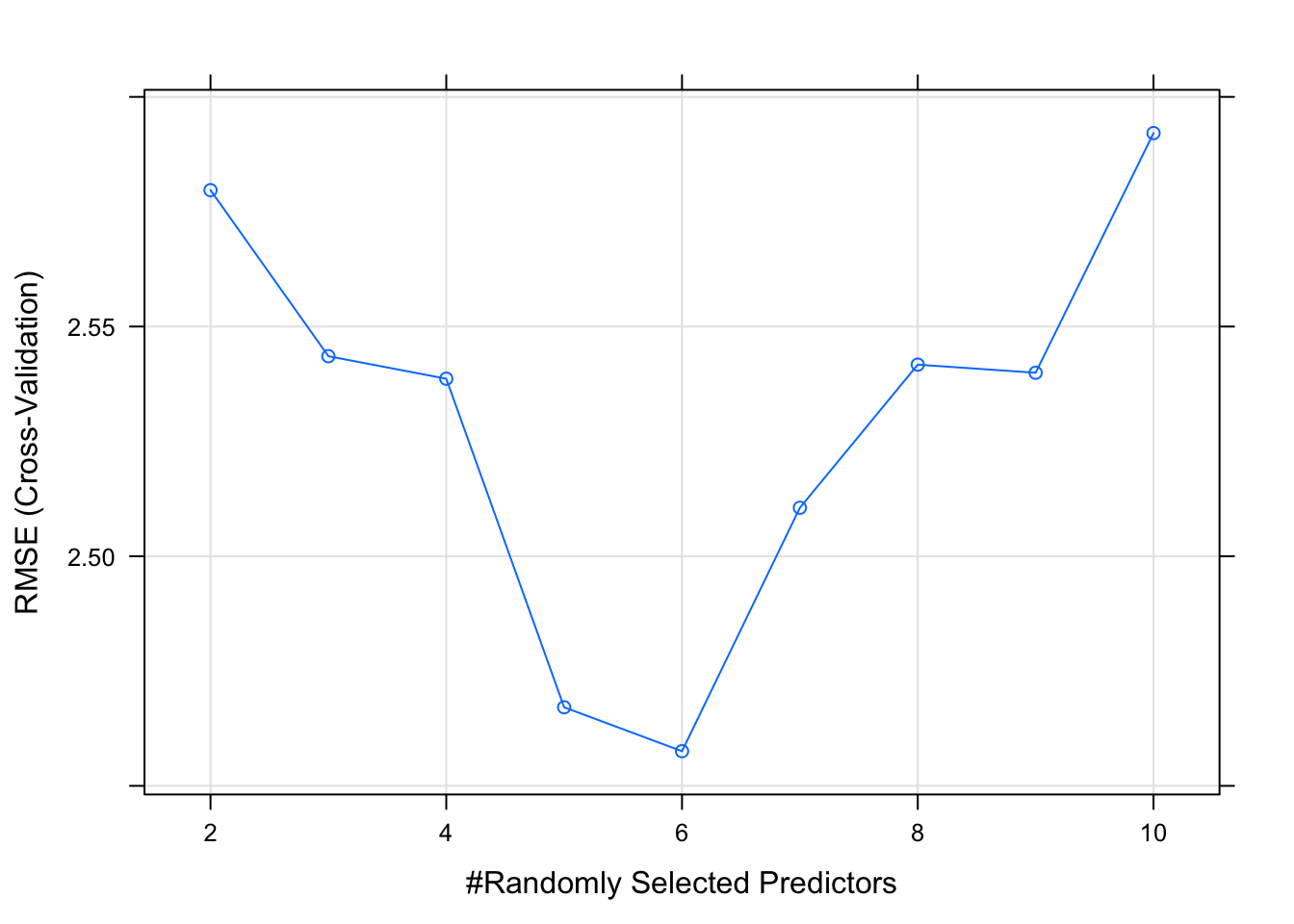
## [1] 2.23303If you have a questions about what hyper parameters can be tuned for a given method then you can refer to the online caret documentation Here is a screenshot of the table of supported models and associated tuning parameters.
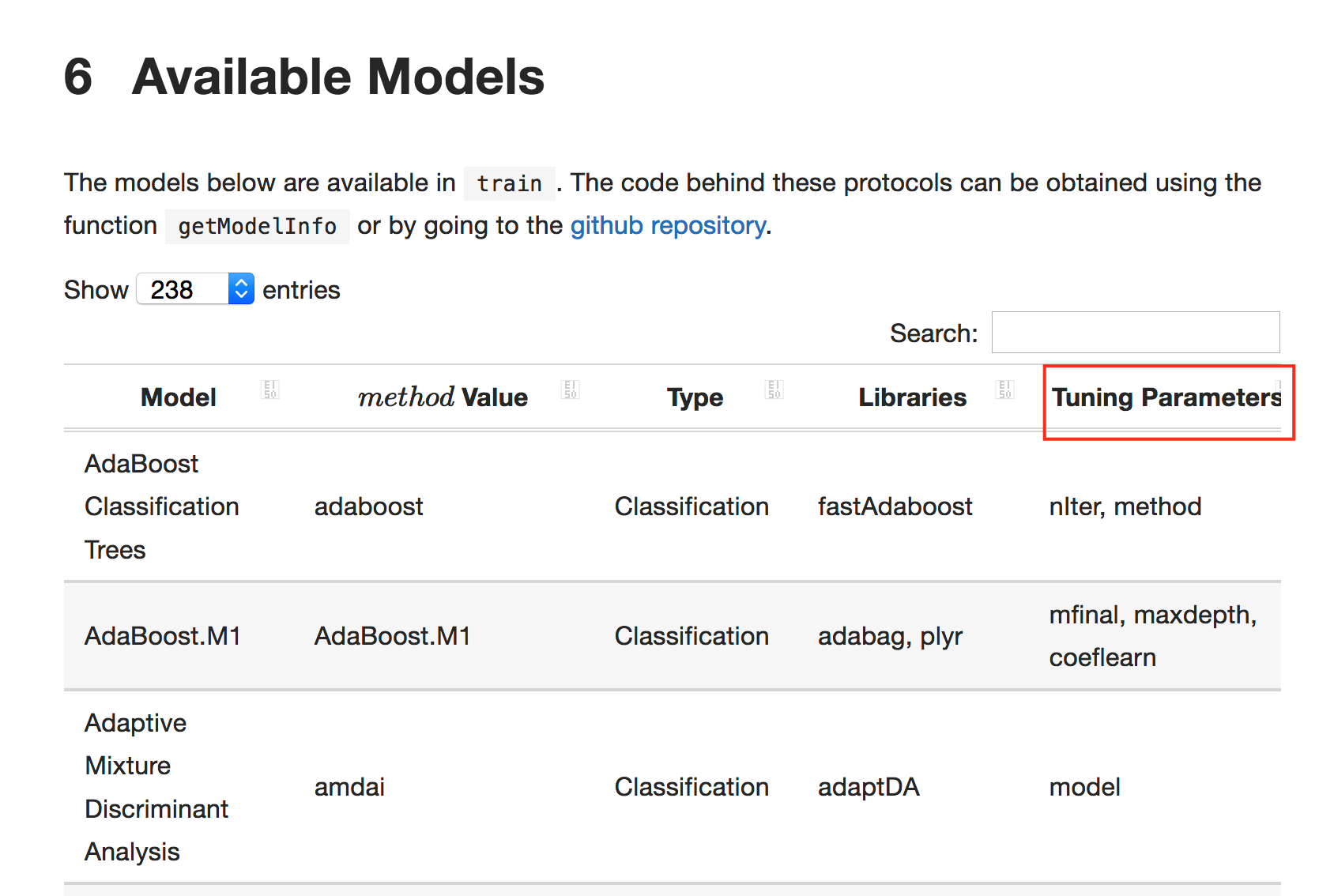
Another way to do this within the caret package itself is that if you already know the abbreviation for the specific method you wish to use (e.g. “rf”) then you can use some built in functions to help you. Remember that caret does not replace or rewrite functions, it merely provides a nice wrapper around them. Since each underlying model is it a standalone R package and associated set of functions you can always call them directly.
## model parameter label forReg forClass probModel
## 1 rf mtry #Randomly Selected Predictors TRUE TRUE TRUEHere we get the hyper parameters for the ranger function. We see that it has three hyper parameters that could be varied in some way to influence a final model.
## model parameter label forReg forClass probModel
## 1 ranger mtry #Randomly Selected Predictors TRUE TRUE TRUE
## 2 ranger splitrule Splitting Rule TRUE TRUE TRUE
## 3 ranger min.node.size Minimal Node Size TRUE TRUE TRUEIf you just want a list of all the models supported by caret then do something like this:
## [1] 502## model parameter label
## 365 rf mtry #Randomly Selected Predictors## model parameter label
## 351 ranger mtry #Randomly Selected Predictors
## 352 ranger splitrule Splitting Rule
## 353 ranger min.node.size Minimal Node SizeSo in the case of the ranger function there are actually three hyper parameters that could be tuned.
my_ctrl <- trainControl(
method = "cv",
number = 3,
verboseIter = FALSE
)
my_ranger <- train(
mpg ~ .,
Train,
method = "ranger",
tuneLength = 6,
trControl = my_ctrl
)
my_ranger## Random Forest
##
## 28 samples
## 10 predictors
##
## No pre-processing
## Resampling: Cross-Validated (3 fold)
## Summary of sample sizes: 18, 19, 19
## Resampling results across tuning parameters:
##
## mtry splitrule RMSE Rsquared MAE
## 2 variance 2.761408 0.8672659 2.374636
## 2 extratrees 2.719210 0.8528162 2.323624
## 3 variance 2.745672 0.8706840 2.383784
## 3 extratrees 2.744949 0.8486200 2.367447
## 5 variance 2.834880 0.8593408 2.431688
## 5 extratrees 2.779045 0.8534449 2.397243
## 6 variance 2.827772 0.8627602 2.415079
## 6 extratrees 2.761680 0.8580494 2.404353
## 8 variance 2.858153 0.8550033 2.461909
## 8 extratrees 2.776434 0.8535960 2.438577
## 10 variance 2.853339 0.8602301 2.480190
## 10 extratrees 2.822600 0.8541223 2.444921
##
## Tuning parameter 'min.node.size' was held constant at a value of 5
## RMSE was used to select the optimal model using the smallest value.
## The final values used for the model were mtry = 2, splitrule = extratrees
## and min.node.size = 5.## [1] 3.042224