Chapter 7 Classification Example
Now that we’ve got an idea about how we might judge the performance quality of classification problem let’s look at the mechanics of implementing a classification model using the caret package. We’ve already seen it in action on a regression problem where we were predicting the MPG for the mtcars data frame.
We’ll be sticking with the Pima Indians dataset. In case you have forgotten, here are the variables in the data frame
pregnant - Number of times pregnant
glucose - Plasma glucose concentration (glucose tolerance test)
pressure - Diastolic blood pressure (mm Hg)
triceps - Triceps skin fold thickness (mm)
insulin - 2-Hour serum insulin (mu U/ml)
mass - Body mass index (weight in kg/(height in m)\^2)
pedigree - Diabetes pedigree function
age - Age (years)
diabetes - Class variable (test for diabetes)url <- "https://raw.githubusercontent.com/steviep42/bios534_spring_2020/master/data/pima.csv"
pm <- read.csv(url) So let’s look at some exploratory plots to see if there is anything interesting happening. We’ll use the Data Explorer package to help us with this although both R and Python have various packages to help with this kind of thing.
7.1 Exploratory Plots
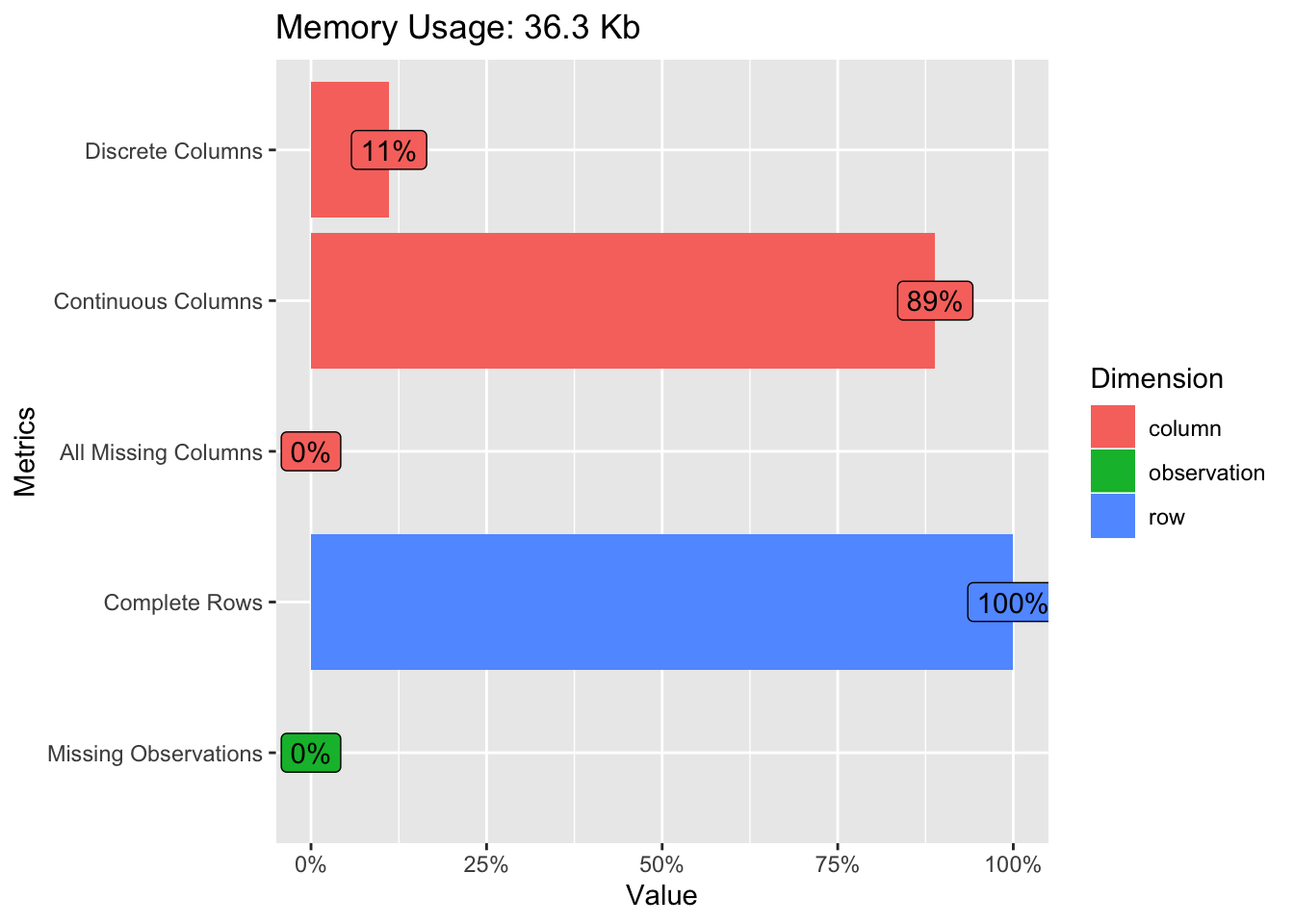
We’ll look use some stock plots from the DataExplorer package to get a feel for the data. Look at correlations between the variables to see if any are strongly correlated with the variable we wish to predict or any other variables. Let’s start out with the plot_intro function which can provide an overview of our data. It turns out that our data is pretty clean. There are no rows with missing values and we have only one categorical feature.
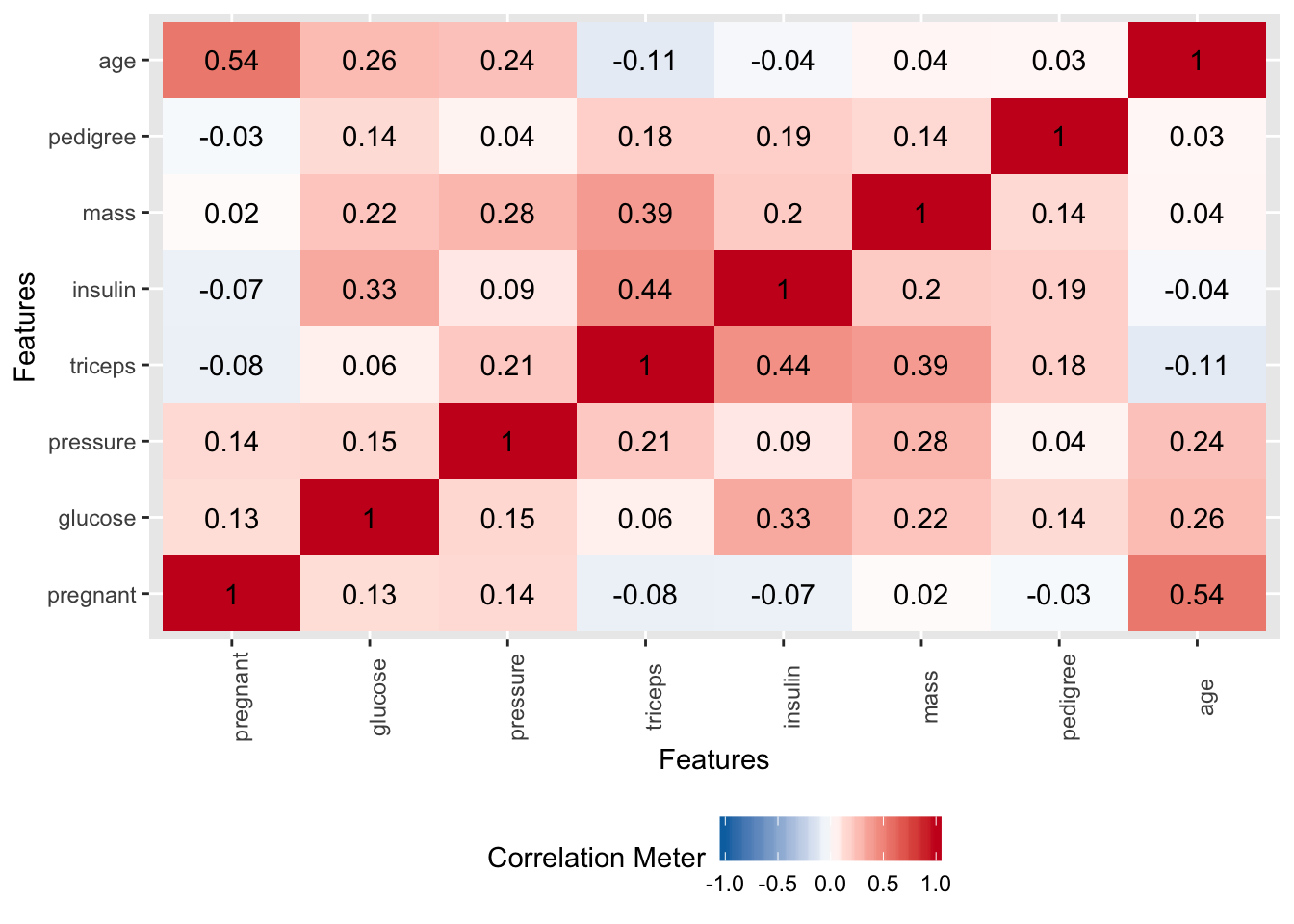
Let’s see if there are any string correlations we need to be aware of.
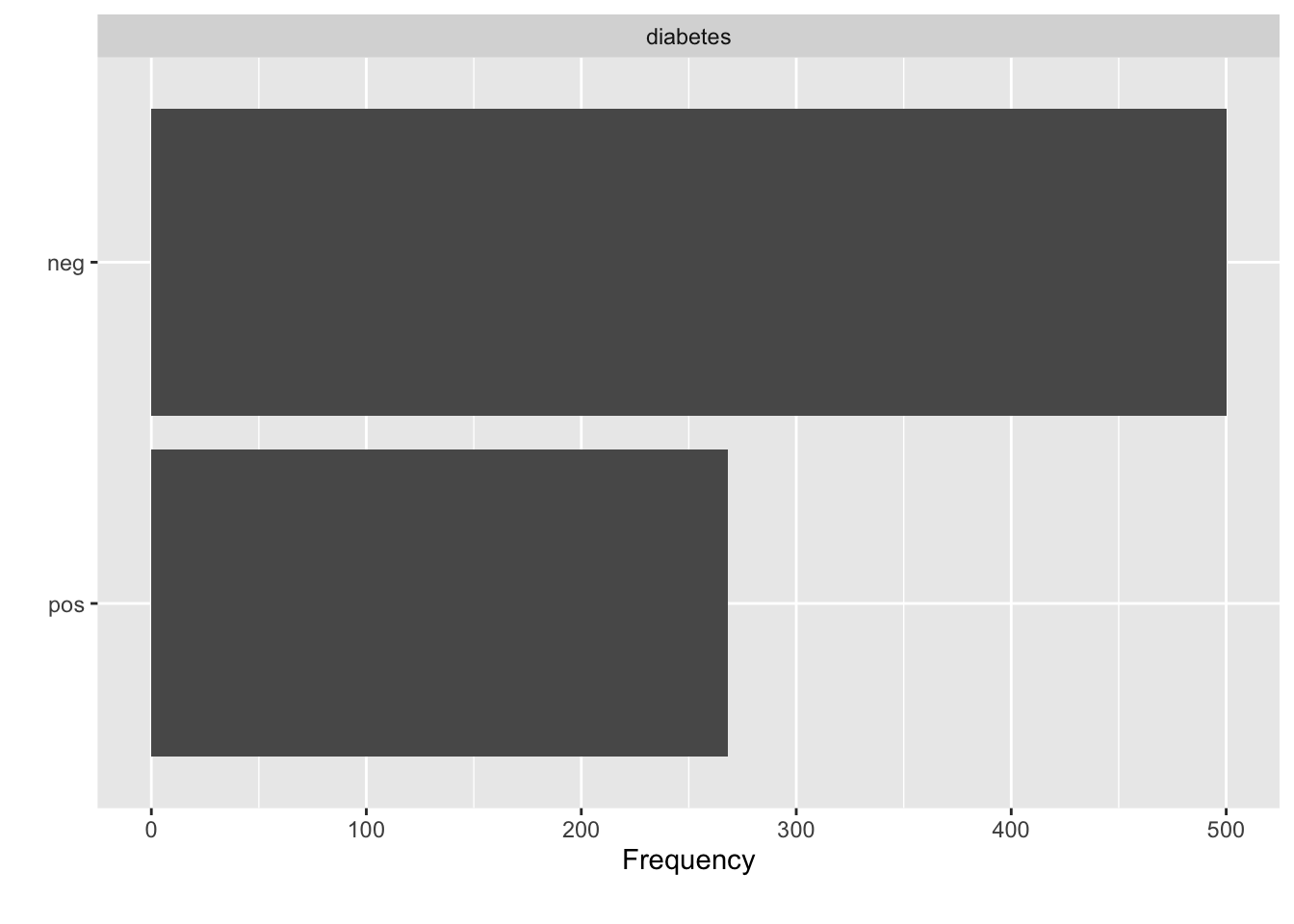
There are more diabetes “negative” people than “positive”.
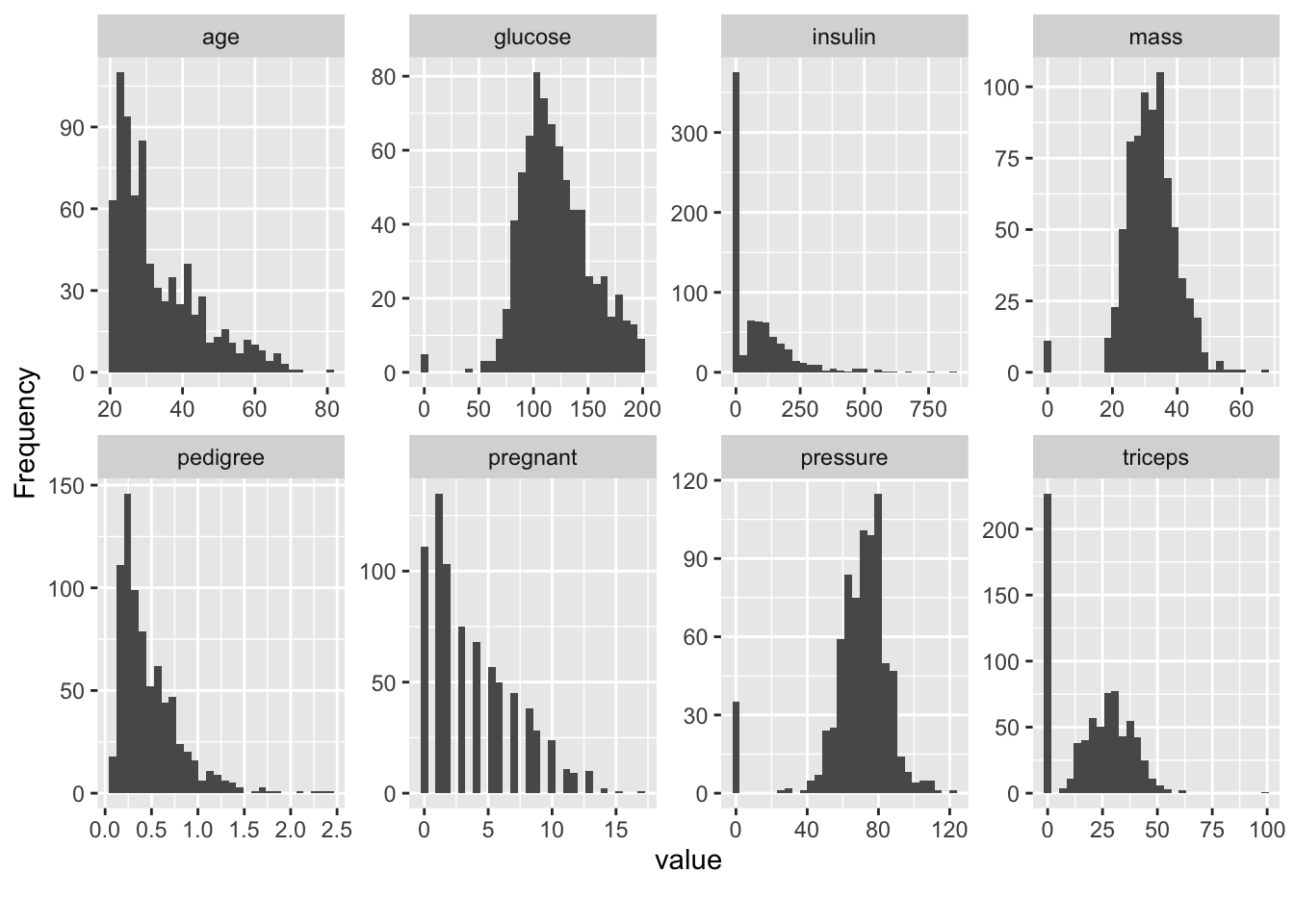
The histograms help us see what variables might be normally distributed although most of our features are skewed which makes sense in this case. For example, as people age, they tend to die so it’s not surprising that we have by far more young people. It looks to me that the insulin data is a little odd and might warrant greater consideration.
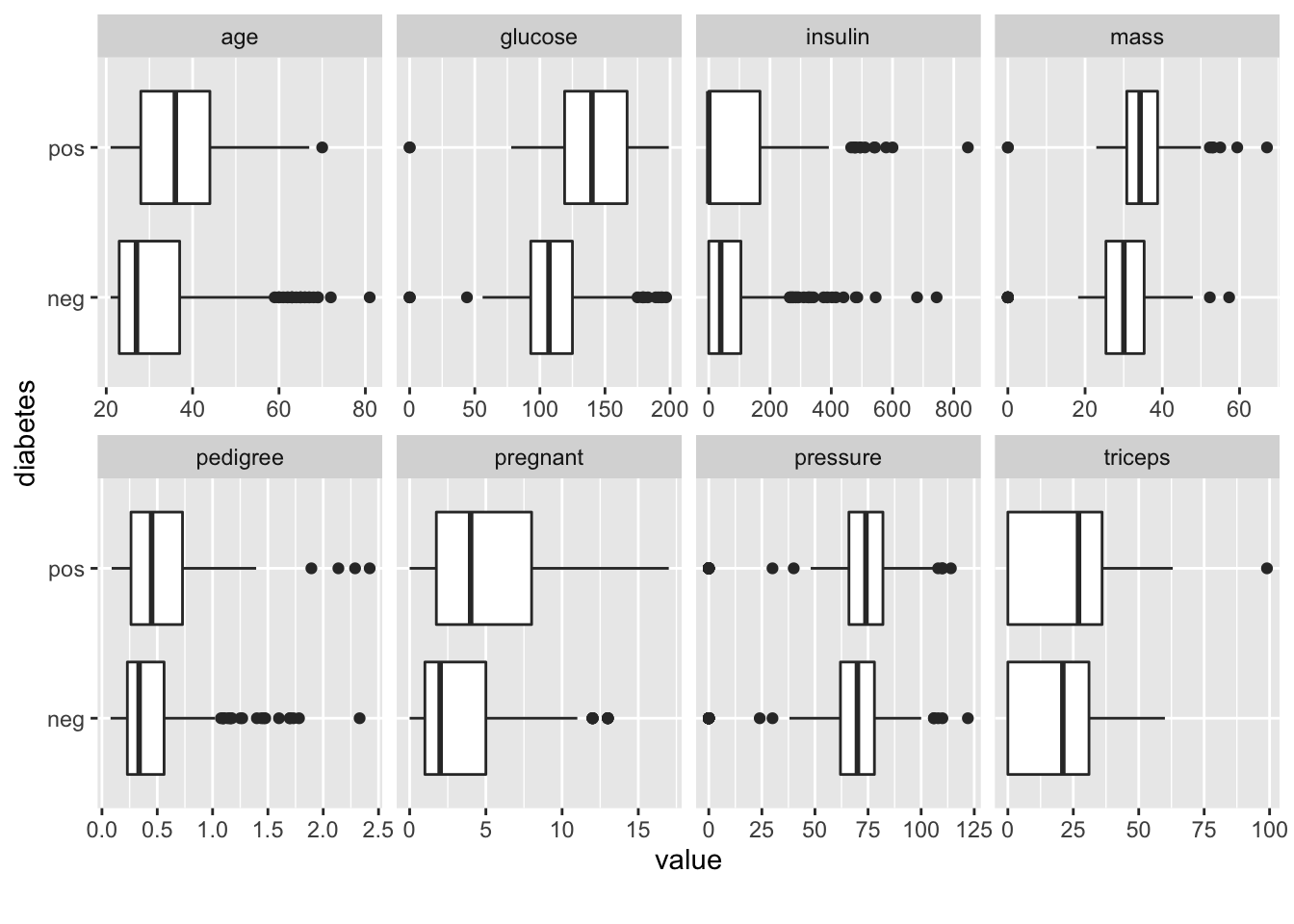
This plot will show us side by side boxplots of the features as a function of “pos” or “neg”. This is helpful to determine if, for example, there might be significant differences between glucose levels across the positive and negative groups. It makes sense that there might be. Insulin might be also although it’s not totally apparent from the following graph. This is the kind of thing you would do to zone in on important variables.
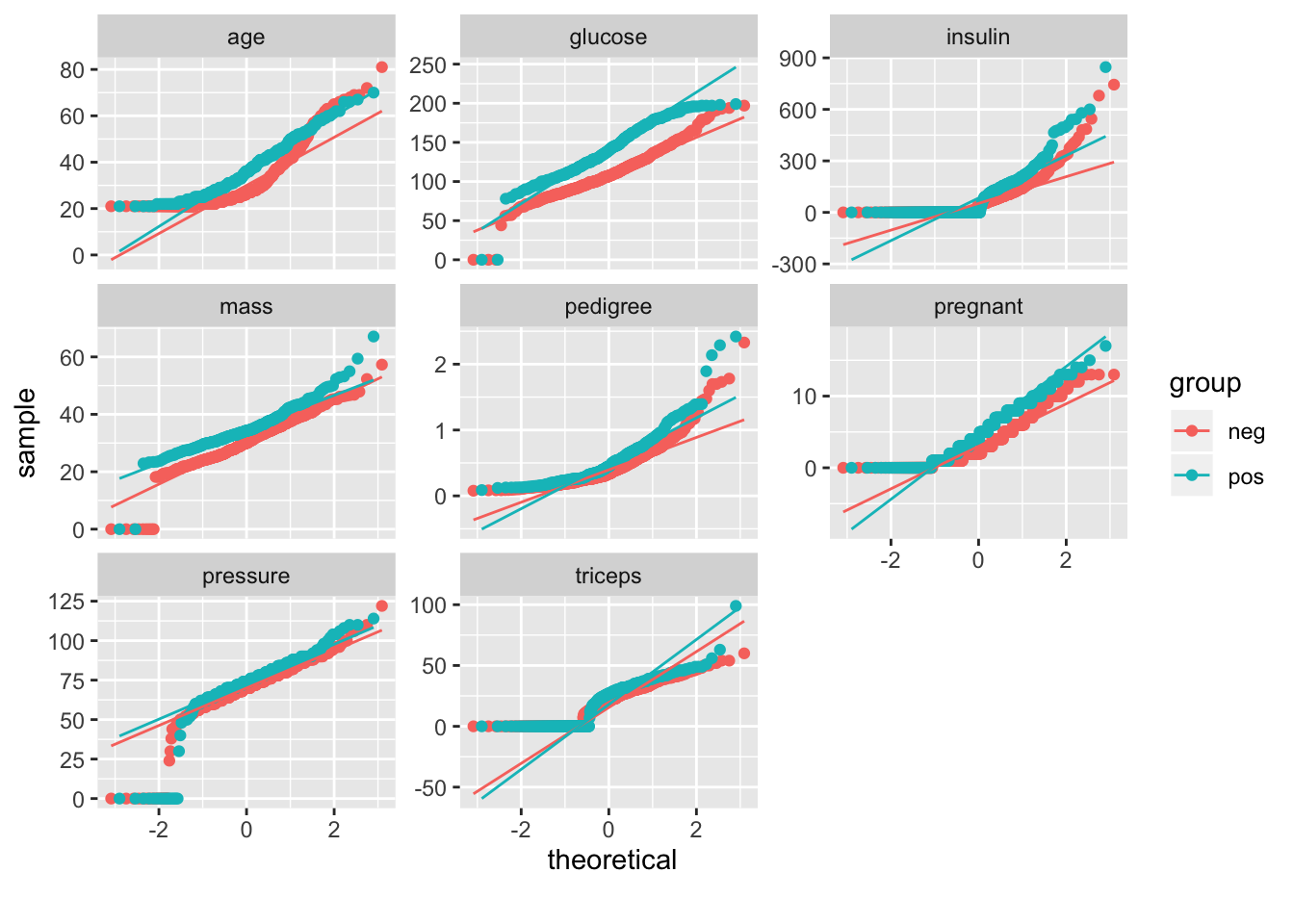
This plot will help us see if any of our features are normally distributed:
It turns out that Data Explorer will help us create a detailed report involving all of these plot tops.
At this point we know that we want to predict “diabetes” and that perhaps glucose is an important variables in the data. We also don’t observe many strong correlations in the data so multicollinearity isn’t a concern. We also don’t see strong evidence in the PCA plot that the data would benefit from a PCA transformation. One thing that we might consider doing is scaling the data since the features do not share the same measurement scale. We’ll take this into consideration.
7.2 Generalized Linear Models
Let’s pick a technique to model the data with the ultimate goal of being able to predict whether someone has diabetes or not. We’ll start with the glm function in R. We’ll take a kitchen sink approach where we predict the diabetes variable (“yes” or “no”) based on the rest of the information in the data frame.
## Resample1
## [1,] 1
## [2,] 3
## [3,] 4
## [4,] 5
## [5,] 7
## [6,] 9## [1] 615## [1] 153If we used the non caret approach we might do something like the following:
pm_model_glm <- glm(diabetes ~ .,
data = train,
family="binomial")
pm_model_fitpreds <- predict(pm_model_glm,test,
type="response")But, as we learned we can also build a ROC curve to get the AUC which can be a general estimator of how well the model is performing.
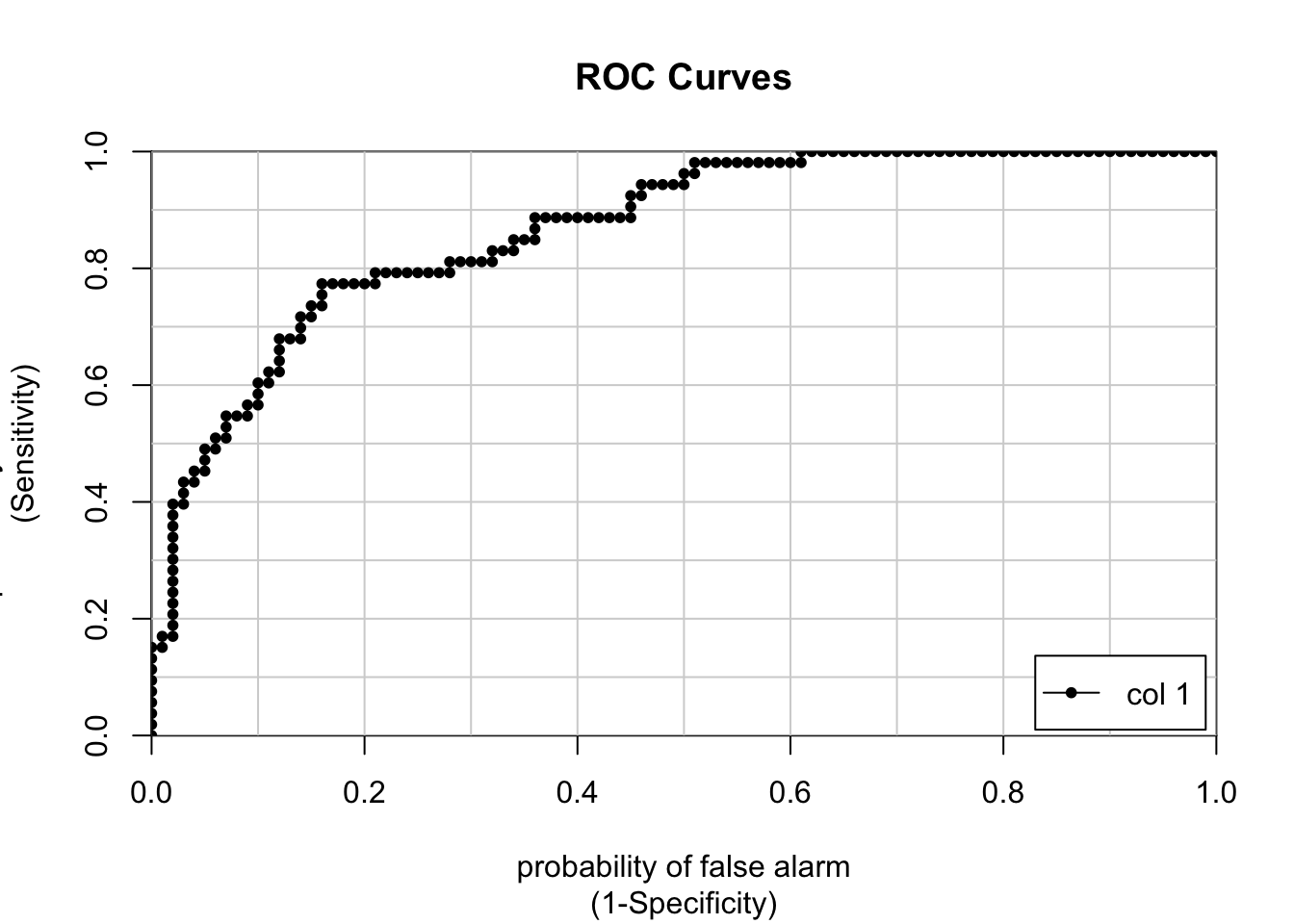
## [,1]
## neg vs. pos 0.8677358fitpredt <- ifelse(pm_model_fitpreds > .385,"pos","neg")
fitpreds <- factor(fitpredt,level=levels(test$diabetes))
mytab <- caret::confusionMatrix(fitpreds,
test$diabetes,positive="pos")
mytab$overall['Accuracy']## Accuracy
## 0.8169935We can explore any number of methods, implement K Fold Cross Validation,and get feedback on the performance measures all at the same time. Let’s reframe our above work using the caret package conveniences. We want to use Cross Fold validation here.
ctrl <- trainControl(method = "cv",
number = 5)
pm_glm_mod <- train(form = diabetes ~ .,
data = train,
trControl = ctrl,
method = "glm",
family = "binomial")
pm_glm_mod## Generalized Linear Model
##
## 615 samples
## 8 predictor
## 2 classes: 'neg', 'pos'
##
## No pre-processing
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 492, 492, 492, 492, 492
## Resampling results:
##
## Accuracy Kappa
## 0.7723577 0.4733393## parameter Accuracy Kappa AccuracySD KappaSD
## 1 none 0.7723577 0.4733393 0.04526638 0.1110331So we get an estimate of a 77% accuracy rate when the model is applied to out of sample data. So let’s make some predictions use thing test data to see what the Accuracy rate is.
pm_glm_pred_labels <- predict(pm_glm_mod,test)
mytab <- table(pm_glm_pred_labels,test$diabetes)
# We can compute accuracy by hand also
sum(diag(mytab))/sum(mytab)## [1] 0.7973856We can change the scoring metric to prioritize, for example, the area under the associated ROC curve. We just need to make some adjustments to the trainControl argument list and the train argument list. But these changes are minor.
To get the AUC for the ROC we’ll need to indicate that this is a two-class problems. Since the ROC curve is based on the predicted class probabilities (which are not computed automatically), the classProbs = TRUE option is used.
ctrl <- trainControl(method = "cv",
number = 5,
classProbs = T,
summaryFunction = twoClassSummary)
pm_glm_mod <- train(form = diabetes ~ .,
data = train,
trControl = ctrl,
metric = "ROC",
method = "glm")
pm_glm_mod$results## parameter ROC Sens Spec ROCSD SensSD SpecSD
## 1 none 0.8248256 0.8725 0.5581395 0.0308541 0.03112475 0.01644434## [,1]
## neg vs. pos 0.8677358If you need to plot the ROC curve just set the extra option to be plotROC = TRUE.
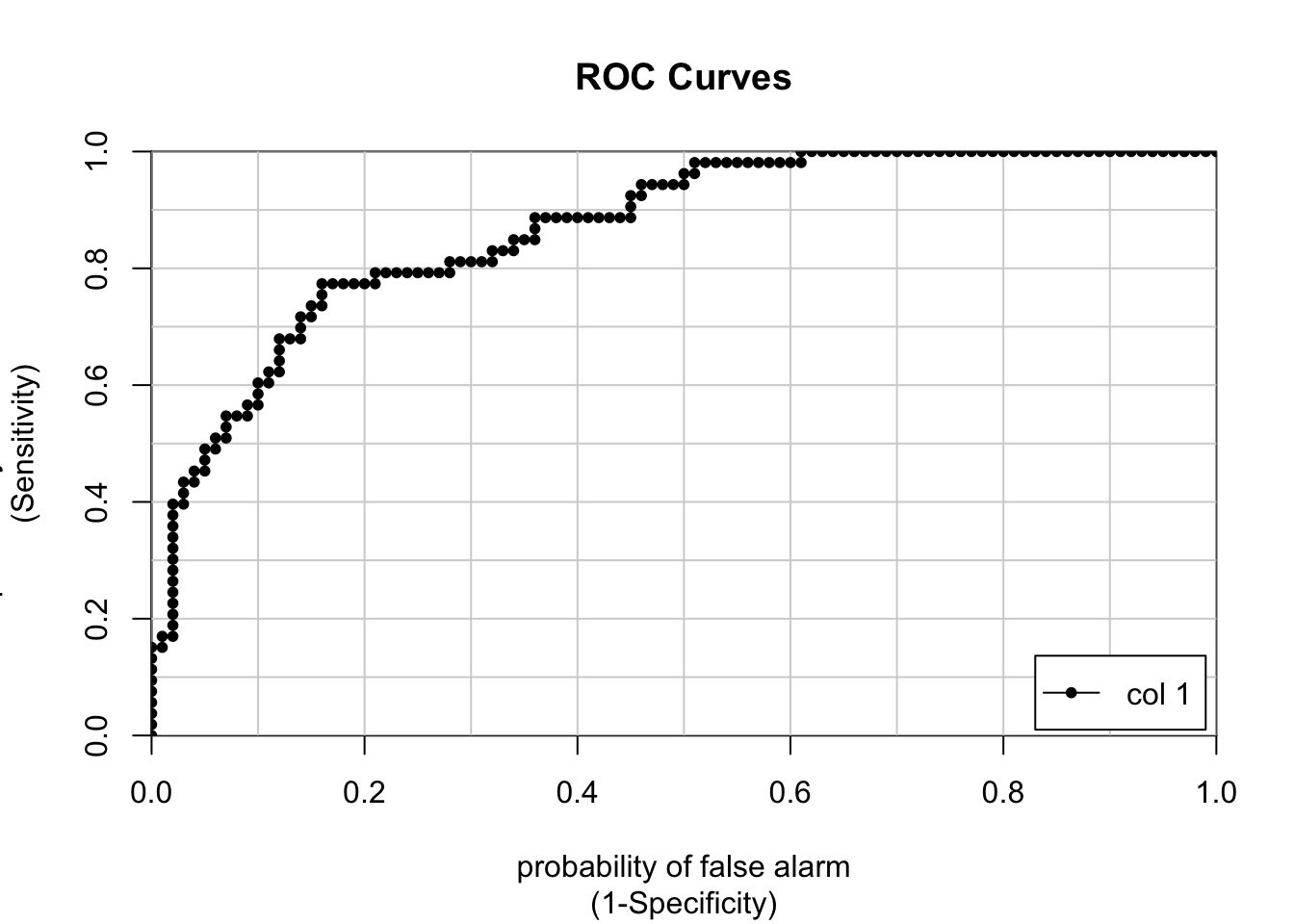
## [,1]
## neg vs. pos 0.86773587.3 Random Forests
Let’s use random forests to see what results we get. Random forests are robust to over fitting and are fairly easy to implement. They can improve accuracy by fitting many trees. Each tree is fit to a resampled version of the input data (usually a bootstrap). This is known as bootstrap aggregation or “bagged” trees. At each split, the function takes a random sample of columns (the mtry argument).
The function we will use here, rf, has at least one “hyper parameter” which could be set to a range of values which, in turn, could influence the resulting model. With glm, we didn’t really have a hyper parameter. We’ll worry about hyper parameters later.
Let’s try this to see how it performs via the ranger method
ctrl <- trainControl(method = "cv",
number = 5,
classProbs = T,
summaryFunction = twoClassSummary)
pm_rf_mod <- train(form = diabetes ~ .,
data = train,
trControl = ctrl,
metric = "ROC",
method = "rf")By default the training process will move through different values of the algorithms hyper parameters - this is called “tuning”. caret knows what hyper parameters the method supports and can cycle through possible valid values of these hyper parameters.
## Random Forest
##
## 615 samples
## 8 predictor
## 2 classes: 'neg', 'pos'
##
## No pre-processing
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 492, 492, 492, 492, 492
## Resampling results across tuning parameters:
##
## mtry ROC Sens Spec
## 2 0.8159884 0.8575 0.5813953
## 5 0.8107267 0.8525 0.5906977
## 8 0.8106977 0.8450 0.6000000
##
## ROC was used to select the optimal model using the largest value.
## The final value used for the model was mtry = 2.The object can be plotted. Here we see that the max AUC of .825 occurs when mtry is 3 and the Gini criterion is used to evaluate a tree.
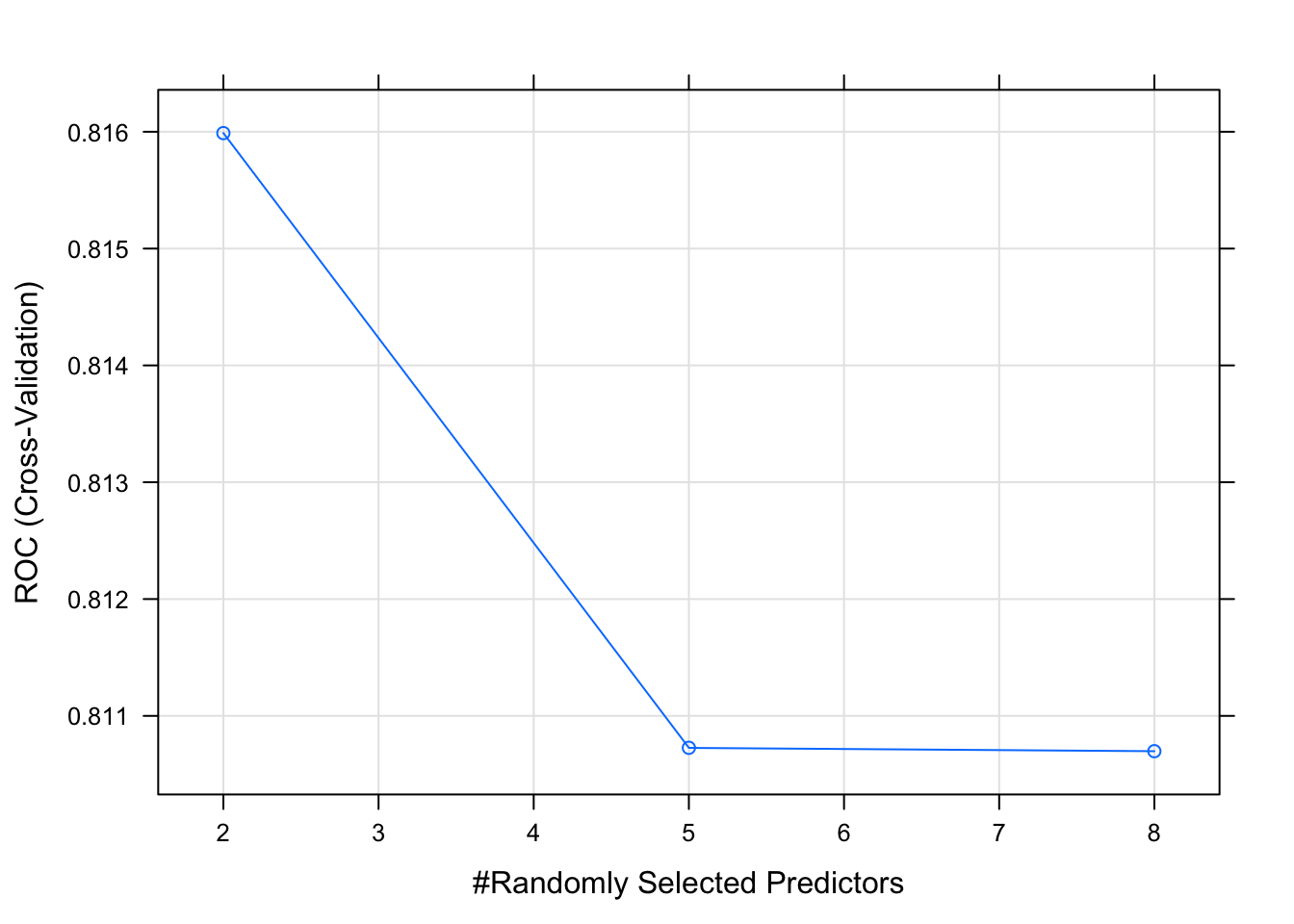
## [1] 0.8128779This model has better sensitivity and specificity than the previous one.
## Confusion Matrix and Statistics
##
## Reference
## Prediction neg pos
## neg 83 20
## pos 17 33
##
## Accuracy : 0.7582
## 95% CI : (0.6824, 0.8237)
## No Information Rate : 0.6536
## P-Value [Acc > NIR] : 0.003479
##
## Kappa : 0.4587
##
## Mcnemar's Test P-Value : 0.742308
##
## Sensitivity : 0.6226
## Specificity : 0.8300
## Pos Pred Value : 0.6600
## Neg Pred Value : 0.8058
## Prevalence : 0.3464
## Detection Rate : 0.2157
## Detection Prevalence : 0.3268
## Balanced Accuracy : 0.7263
##
## 'Positive' Class : pos
## 7.4 Feature Importance
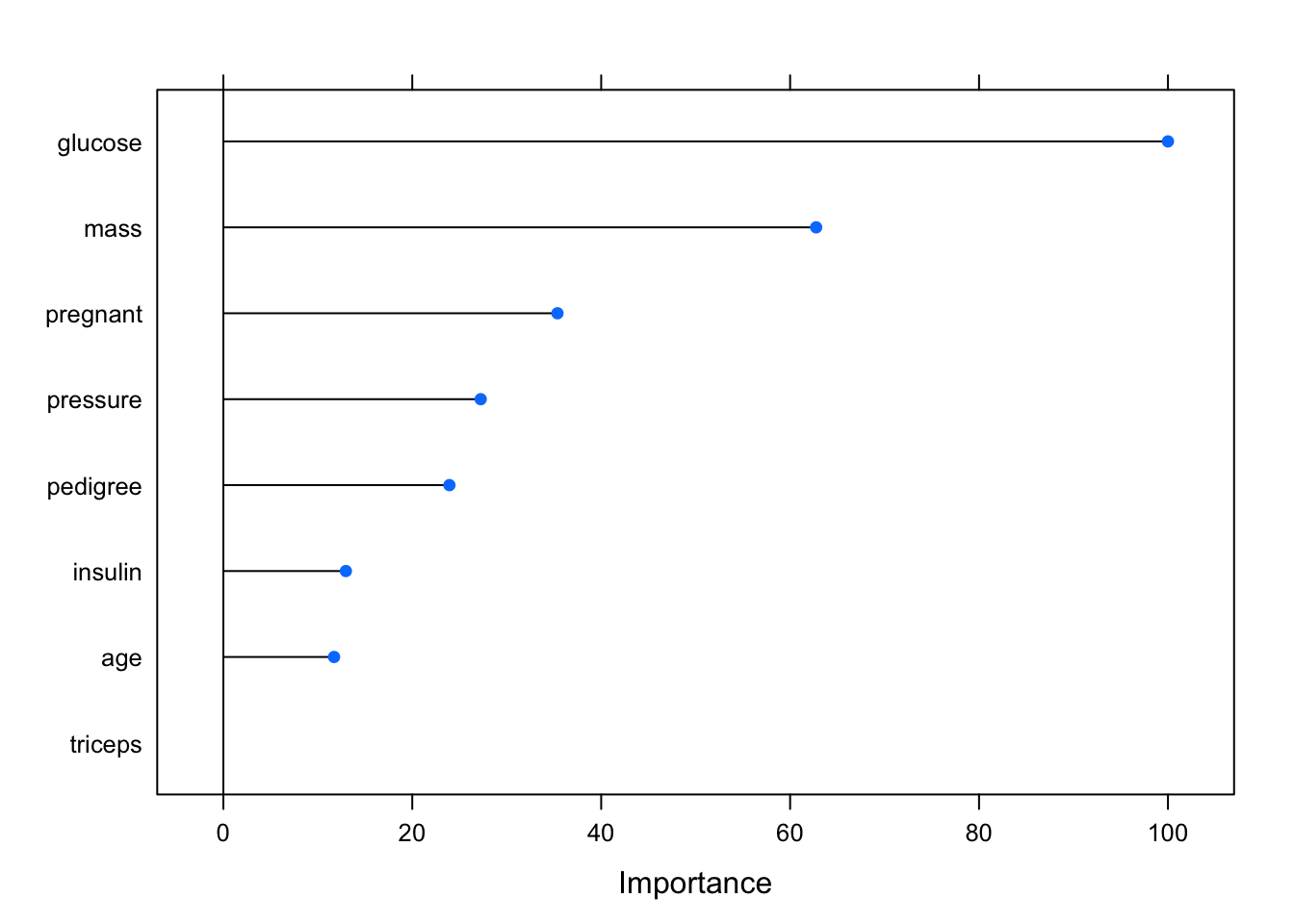
To inroduce the idea of feature importance, there is a function called varImp that looks at a caret model and uses statisics specific to the method under consideration to get an idea as to if and to what extent a feature is relevant to the model. This is important in that it can help you figure out what variables / features to include or exclude when building a formular.
## glm variable importance
##
## Overall
## glucose 100.00
## mass 62.76
## pregnant 35.37
## pressure 27.24
## pedigree 23.93
## insulin 12.97
## age 11.72
## triceps 0.00## rf variable importance
##
## Overall
## glucose 100.000
## mass 54.737
## age 34.227
## pedigree 29.880
## pressure 13.939
## pregnant 3.842
## triceps 3.612
## insulin 0.000These can even be plotted:
library(gridExtra)
plot1 <- plot(varImp(pm_glm_mod),main="GLM")
plot2 <- plot(varImp(pm_rf_mod),main="rf")
grid.arrange(plot1,plot2, ncol=2)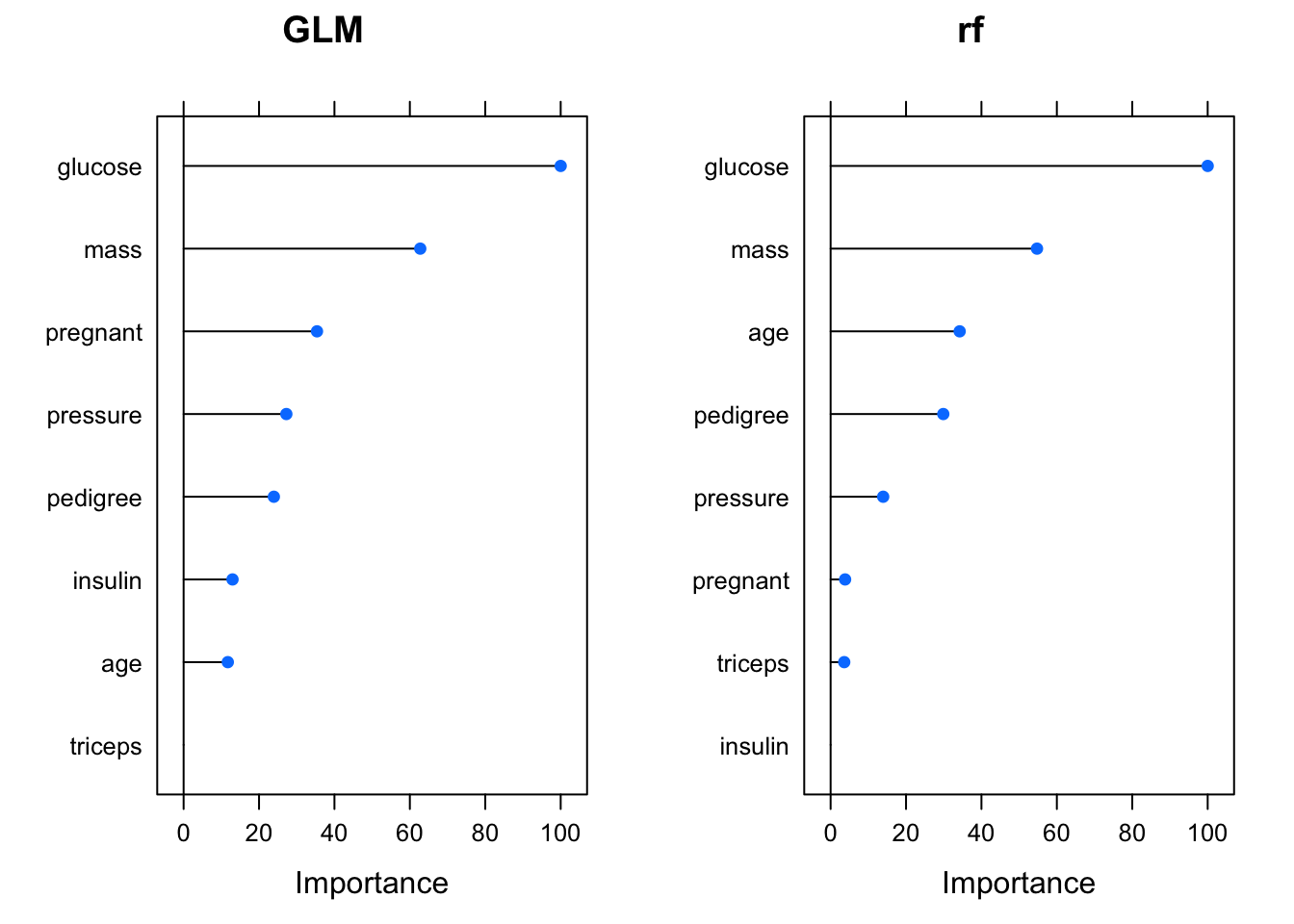
This then makes one wonder as to if the rf model could be improved by ommitting some variables. Let’s try this:
ctrl <- trainControl(method = "cv",
number = 5,
classProbs = T,
summaryFunction = twoClassSummary)
pm_rf_mod_imp <- train(diabetes ~ glucose + mass + age + pedigree + pressure,
data = train,
trControl = ctrl,
metric = "ROC",
method = "rf")now, the question is how did this improve (or not) when compared to the unimproved rf model which used all the features from the data set ?
## Random Forest
##
## 615 samples
## 8 predictor
## 2 classes: 'neg', 'pos'
##
## No pre-processing
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 492, 492, 492, 492, 492
## Resampling results across tuning parameters:
##
## mtry ROC Sens Spec
## 2 0.8159884 0.8575 0.5813953
## 5 0.8107267 0.8525 0.5906977
## 8 0.8106977 0.8450 0.6000000
##
## ROC was used to select the optimal model using the largest value.
## The final value used for the model was mtry = 2.## Random Forest
##
## 615 samples
## 5 predictor
## 2 classes: 'neg', 'pos'
##
## No pre-processing
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 492, 492, 492, 492, 492
## Resampling results across tuning parameters:
##
## mtry ROC Sens Spec
## 2 0.8192733 0.8500 0.6186047
## 3 0.8168605 0.8525 0.6046512
## 5 0.8070930 0.8425 0.5720930
##
## ROC was used to select the optimal model using the largest value.
## The final value used for the model was mtry = 2.7.5 Target Variable Format
If you notice, the format of the Pima data frame has indicated that the diabetes variable is a factor which is a special format in R to indicate categories. This is useful since the various R functions will generally know how to work with these variables without being told what to do.
## Factor w/ 2 levels "neg","pos": 2 1 2 1 2 1 2 1 2 2 ...Sometimes you will read in data where the values are a 0 or a 1 although in that case you would still need to inform R that this variable is a factor else there would be a problem. Consider the following which reads in a slightly different version of the Pima data set where the diabetes variable has values of 0 and 1 to indicate “negative” or “positive”, respectively.
aurl <- "https://raw.githubusercontent.com/steviep42/bios534_spring_2020/master/data/pima_10.csv"
pm_10 <- read.csv(aurl)
str(pm_10)## 'data.frame': 768 obs. of 9 variables:
## $ pregnant: int 6 1 8 1 0 5 3 10 2 8 ...
## $ glucose : int 148 85 183 89 137 116 78 115 197 125 ...
## $ pressure: int 72 66 64 66 40 74 50 0 70 96 ...
## $ triceps : int 35 29 0 23 35 0 32 0 45 0 ...
## $ insulin : int 0 0 0 94 168 0 88 0 543 0 ...
## $ mass : num 33.6 26.6 23.3 28.1 43.1 25.6 31 35.3 30.5 0 ...
## $ pedigree: num 0.627 0.351 0.672 0.167 2.288 ...
## $ age : int 50 31 32 21 33 30 26 29 53 54 ...
## $ diabetes: int 1 0 1 0 1 0 1 0 1 1 ...Okay, so as far as R is concerned, the diabetes variable is an integer. We could try to use this in a call to the train function and it will fail. This is just like what happened when we were attempting to use regression.
train(diabetes ~ .,
data = pm_10,
method = "glm")
You are trying to do regression and your outcome only has two possible values Are you trying to do classification? If so, use a 2 level factor as your outcome column.Generalized Linear Model So just as we did with the mtcars data frame, we’ll need to turn this into a factor:
pm_10 <- pm_10 %>% mutate(diabetes=factor(diabetes))
train(diabetes ~ .,
data = pm_10,
method = "glm")## Generalized Linear Model
##
## 768 samples
## 8 predictor
## 2 classes: '0', '1'
##
## No pre-processing
## Resampling: Bootstrapped (25 reps)
## Summary of sample sizes: 768, 768, 768, 768, 768, 768, ...
## Resampling results:
##
## Accuracy Kappa
## 0.7721211 0.4683175Now, what would have happened had we been stuck with the version of the data frame that has “pos” and “neg” ? We still have the pm data frame.
## 'data.frame': 768 obs. of 9 variables:
## $ pregnant: int 6 1 8 1 0 5 3 10 2 8 ...
## $ glucose : int 148 85 183 89 137 116 78 115 197 125 ...
## $ pressure: int 72 66 64 66 40 74 50 0 70 96 ...
## $ triceps : int 35 29 0 23 35 0 32 0 45 0 ...
## $ insulin : int 0 0 0 94 168 0 88 0 543 0 ...
## $ mass : num 33.6 26.6 23.3 28.1 43.1 25.6 31 35.3 30.5 0 ...
## $ pedigree: num 0.627 0.351 0.672 0.167 2.288 ...
## $ age : int 50 31 32 21 33 30 26 29 53 54 ...
## $ diabetes: Factor w/ 2 levels "neg","pos": 2 1 2 1 2 1 2 1 2 2 ...While this is good to go, we could have processed it as follows which is something that you might have to do in other languages. This is a form of one hot encoding although the values in this case occupy one column since that is the column to be predicted.
pm_alt <- pm %>%
mutate(diabetes=ifelse(diabetes=="pos",1,0)) %>%
mutate(diabetes = factor(diabetes))
str(pm_alt)## 'data.frame': 768 obs. of 9 variables:
## $ pregnant: int 6 1 8 1 0 5 3 10 2 8 ...
## $ glucose : int 148 85 183 89 137 116 78 115 197 125 ...
## $ pressure: int 72 66 64 66 40 74 50 0 70 96 ...
## $ triceps : int 35 29 0 23 35 0 32 0 45 0 ...
## $ insulin : int 0 0 0 94 168 0 88 0 543 0 ...
## $ mass : num 33.6 26.6 23.3 28.1 43.1 25.6 31 35.3 30.5 0 ...
## $ pedigree: num 0.627 0.351 0.672 0.167 2.288 ...
## $ age : int 50 31 32 21 33 30 26 29 53 54 ...
## $ diabetes: Factor w/ 2 levels "0","1": 2 1 2 1 2 1 2 1 2 2 ...7.6 Addressing Class Imbalance
We have something of a problem in the Pima data. If we look at the number of positive cases vs the negative cases there is an imbalance which might be impacting the construction of our model. We have almost twice as many negative cases as we do positive. It’s not clear that this is a problem and if this proportion accurately reflects the prevalence diabetes in a larger population then perhaps we should accept this. However, we might not know the true prevalence either in the Pima population or a more general one.
## # A tibble: 2 x 2
## diabetes n
## <fct> <int>
## 1 neg 500
## 2 pos 268What techniques exist to deal with this ? There is the concept of “Sub Sampling” which uses sampling (e.g. bootstrap) to produce a training set that balances out the distribution of cases. This includes down sampling, up sampling, and hybrid sampling. Of course there are packages that do this although the caret package itself has some functions to help. We’ll present a down sampling example.
Down sampling “randomly subset all the classes in the training set so that their class frequencies match the least prevalent class”. In this case we’ll use sampling to create a new training set where the two classes counts are equal. Whether this is advisable is another question altogether but let’s see the impact it has on the predictive model.
down_train <- downSample(x = train[, -ncol(train)],
y = train$diabetes, yname="diabetes")
table(down_train$diabetes) ##
## neg pos
## 215 215Next we’ll build our model as before except now we’ll use the down sampled training data. This provides better performance in the ROC and Specificity measures but we experience a reduction in Sensitivity.
ctrl <- trainControl(method = "cv",
number = 5,
classProbs = TRUE,
summaryFunction = twoClassSummary)
pm_glm_down <- train(form = diabetes ~ .,
data = down_train,
trControl = ctrl,
metric = "ROC",
method = "glm",
preProc = c("center", "scale"))
pm_glm_down## Generalized Linear Model
##
## 430 samples
## 8 predictor
## 2 classes: 'neg', 'pos'
##
## Pre-processing: centered (8), scaled (8)
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 344, 344, 344, 344, 344
## Resampling results:
##
## ROC Sens Spec
## 0.807139 0.7348837 0.7116279Check the predictions:
down_preds <- predict(pm_glm_down,test,type="prob")
colAUC(down_preds[,2],test$diabetes,plotROC = TRUE)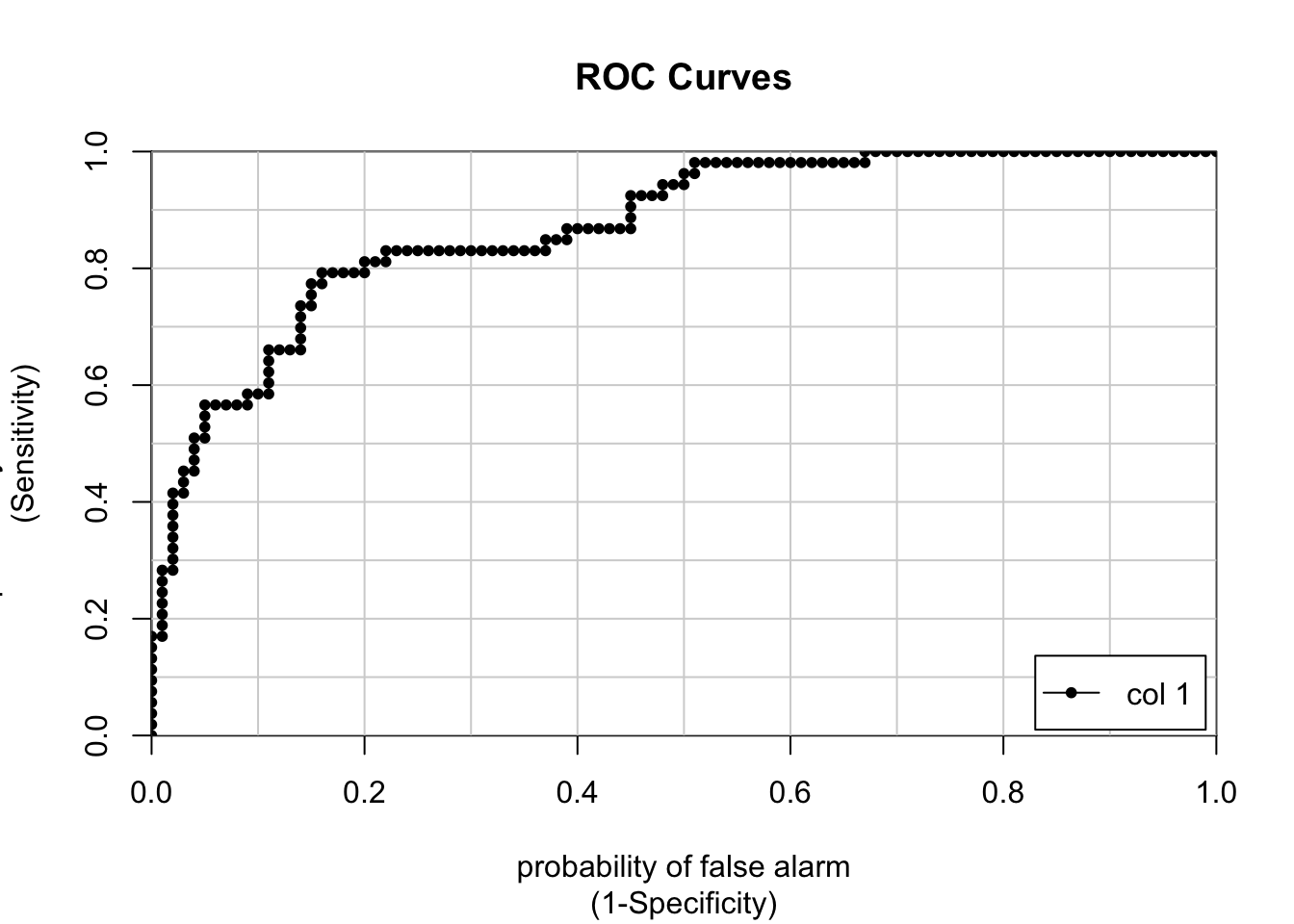
## [,1]
## neg vs. pos 0.8722642So how does this compare to the pm_glm_model we created earlier using the training set that reflected the less balanced data ?
## Generalized Linear Model
##
## 615 samples
## 8 predictor
## 2 classes: 'neg', 'pos'
##
## No pre-processing
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 492, 492, 492, 492, 492
## Resampling results:
##
## ROC Sens Spec
## 0.8248256 0.8725 0.5581395unbalanced_preds <- predict(pm_glm_mod,test,type="prob")
colAUC(unbalanced_preds[,2],test$diabetes,plotROC = TRUE)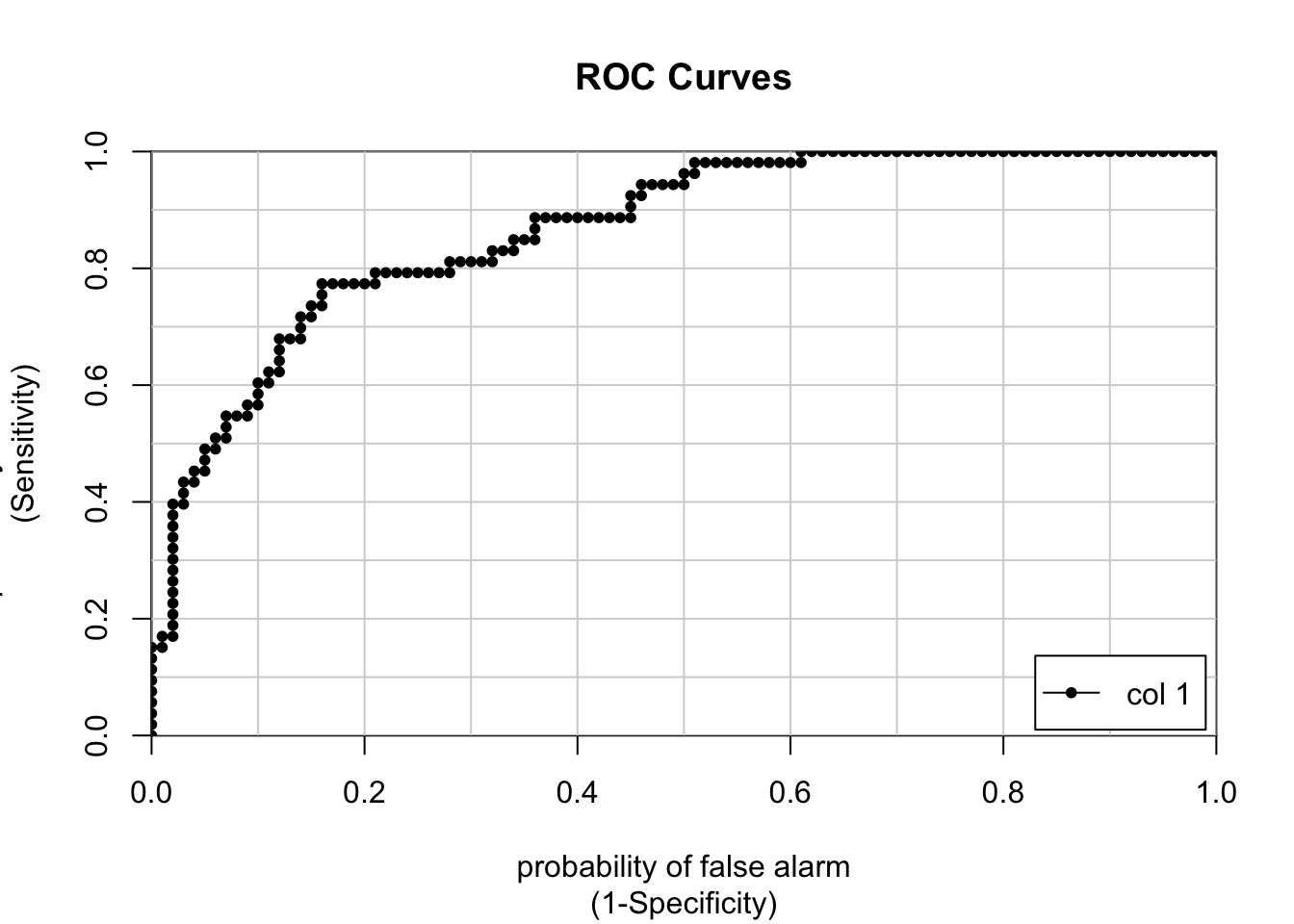
## [,1]
## neg vs. pos 0.8677358