Chapter 4 Text Mining
4.1 Recap
In my last lecture I talked about using the rvest package to pull data from the Internet. This is useful because there is lots of information out there on the Internet that you could download and analyze. It can also be a pain to clean data and get it into a format you would like but that’s life and there isn’t a lot you can do about that.
Every 60 seconds on Facebook: 510,000 comments are posted and 293,000 statused are updated
Facebook Photo uploads total 300 million per day
Worldwide, there are over 2.32 billion active Facbook users as of December 31, 2018
Every second, on average, around 6,000 tweets are tweeted on Twitter
1,332,433 Publications in Pubmed for the year 2018
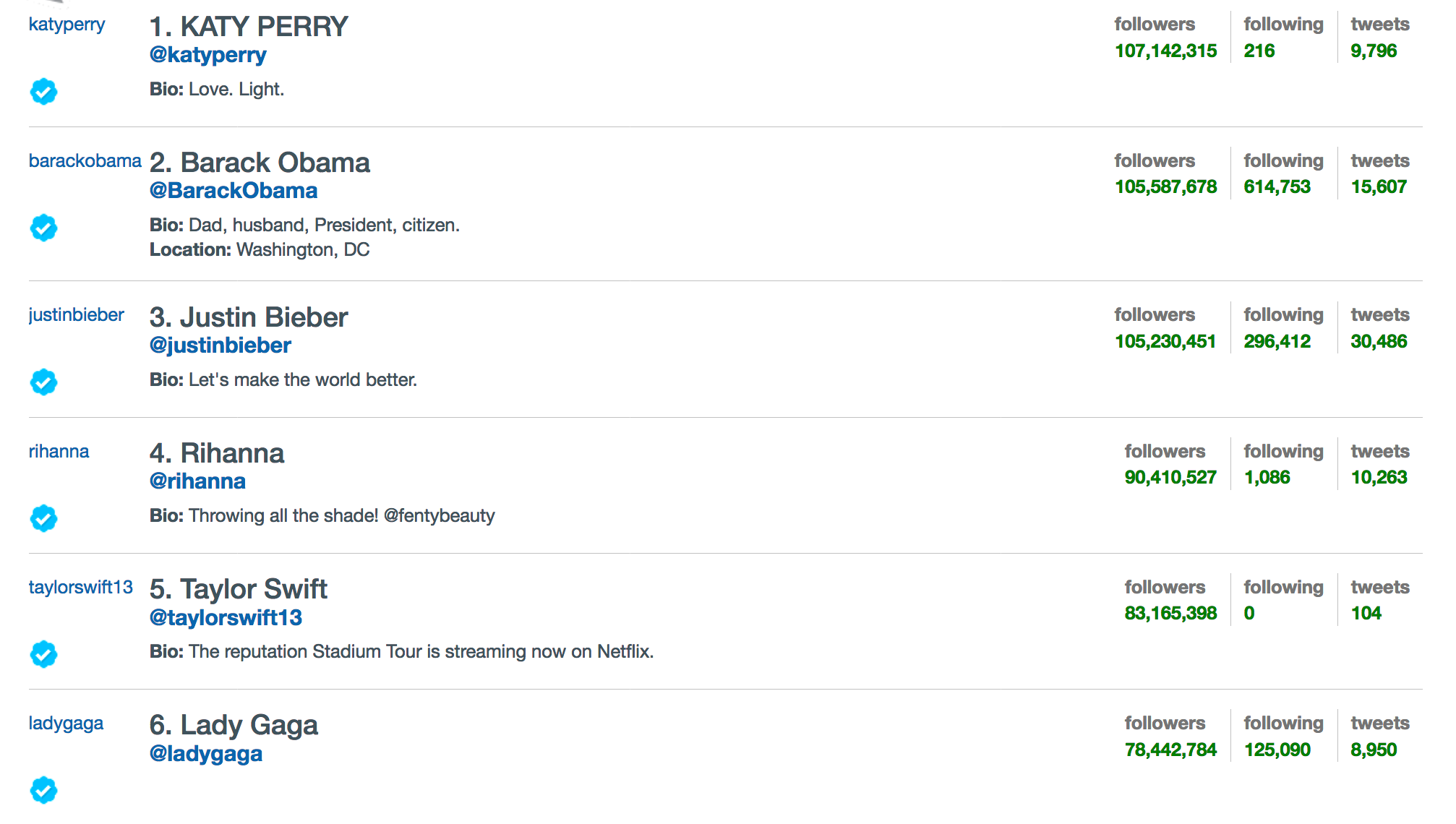
Here are the top Twitter accounts being followed. A tweet from any of these people can represent a lot of money ! There are people who try to figure out just how much.
Sources:
4.2 Unstructured Data
Much of the text information found in these sources is unstructured meaning that the content is a narrative, a collection of phrases, or maybe social media posts that might involve domain specific references or a form of slang. Not surprisingly, it can be hard to get meaningful information from text. Unstructured data is useful in that can capture many contexts or points of views in response to a question or situation. It’s also more “natural” for humans to speak and write in unsrtuctured terms.

http://www.triella.com/unstructured-data/
Some unstructured text does conform to an ontology, vocabulary, or some form of domain approved terminology that can simplify knowledge extraction but there are always ambiguities. For example consider a body (aka “corpus”) of medical information related to Nephrology. The following terms might be used to refer to the same thing:
- Chronic renal impairment
- Chronic kidney disease
- CKD
- Kidney failure
- Chronid renal failure
- CRF
- Chronic renal failure syndrome
- Renal insufficiency
- eGFR 44
Source: http://healtex.org/wp-content/uploads/2016/11/I4H-Healtex-tutorial-part1-optimised.pdf
Unless someone knows that these all map to the same idea then downstream analysis might lead to confusing or diluted results.
4.3 Structured Data
Stuctured data is easier to work with in the sense that it is frequently numeric in nature so it lends itself well to statistical analysis and use in building predictive models. Some structured data is standalone meaning you can download it or obtain it as a .CSV file or from a database (e.g. CDC) and begin to work with the data immediately upon receipt.
However, structured data does NOT have to be numeric. For example, consider demographic information. As long as a patient tracking system conforms to a standard then one’s race (and the label used to describe that) would ususally not change. Lists of personal allegies and medications are ususally structured although they might change over time. Smoking status (“yes” or “no”) is structured. Asking someone to describe their life time struggles with trying to stop smoking would not be structured information.
4.4 Hybrids
Consider a Pubmed publication. There is a lot of textual information that is supplemented by graphs, tables, and (hopefully) link outs to raw data. Of course the tables themselves represent a form of structured data in aggregate form so you maybe you would want to parse tor extraxt them from the text. Also consider that Clinician notes and letters are ususally in narrative form but might well include structured info also.
The take home info here is that there is by far more unstructured data than structured but there is lots of cool stuff to be learned from unstructured information. So don’t let that stop you from trying to apply text mining methods for understanding collections of documents.
4.5 Information Retrieval vs Information Extraction
Searching for data is different from extracting meaning from the results returned from a search. If a search engine is good it will return relevant results in response to our query. A bad search engine will return lots of “false positives”. The idea of relevance can be expressed using a number of mathematically computed ratios such as precision (aka positive predictive value) and recall (aka sensitivity). We’ll dig more into these later.

 https://en.wikipedia.org/wiki/Precision_and_recall
https://en.wikipedia.org/wiki/Precision_and_recall
So for this lecture we’ll assume that we have some meaningful results already and work with the text that we have (or will) obtain from using some web scraping techniques we used in a previous lecture.
4.6 Web Scraping Revisited
So I just said that we would be focusing on how to compute on the data instead of how to retrieve it but it’s important to review some basic techniques to refresh your memory and up your R game a little bit. Let’s get some speeches given by former President Obama. This is easy to do.
Look at this URL http://www.obamaspeeches.com/
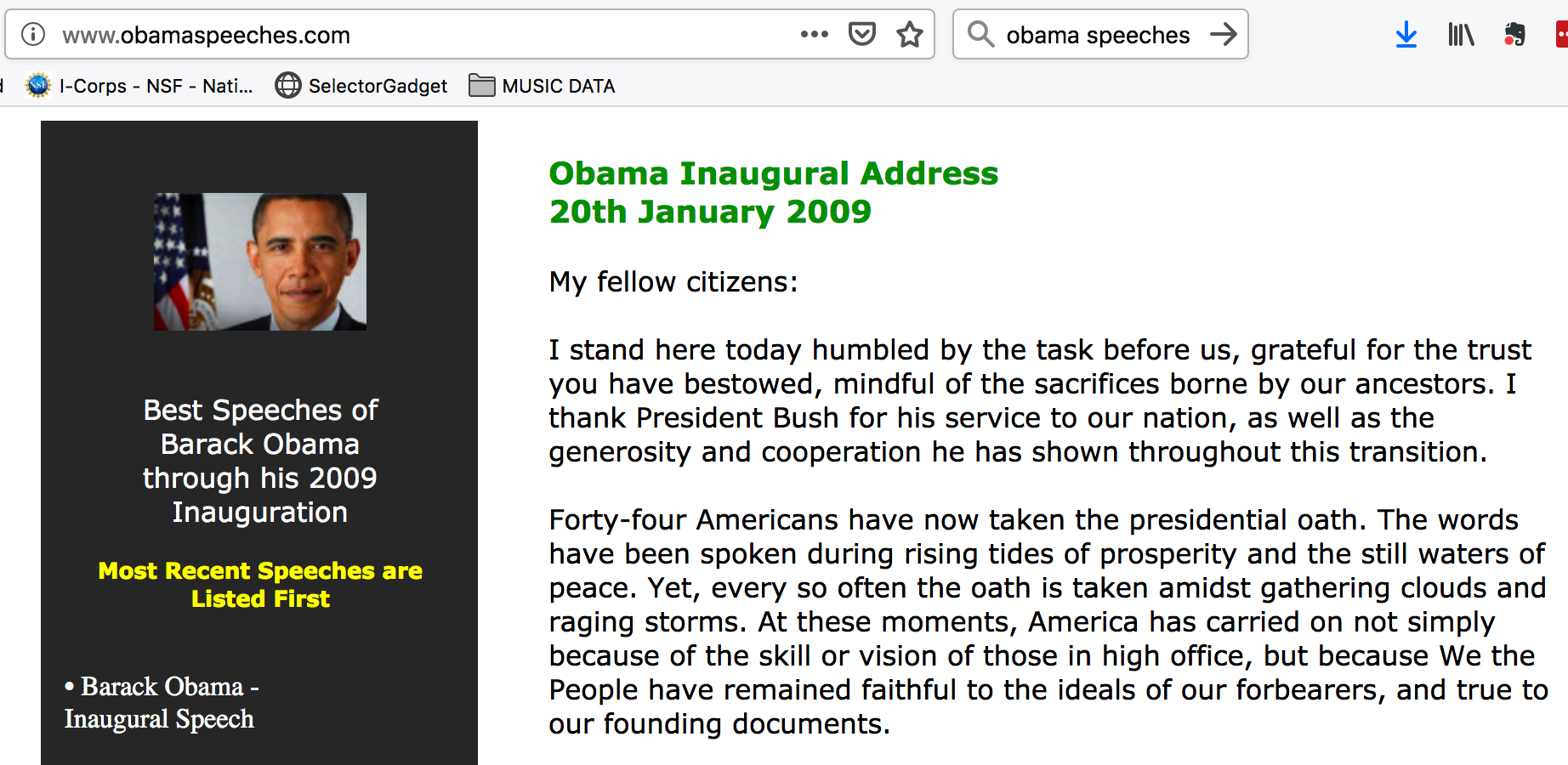
We can get all the speeches from this page if we want to using the rvest package. It’s tedious and takes some time to get things to work correctly but it’s not intellectually challenging. Data scraping and cleaning are two of the more common tasks when working with unstructured text. There is no way around it really. Most projects start out with lots of enthusiam until the data starts rolling in and everyone realizes that there are problems with formatting, etc. Anyway, we’ll get a list of all the links from the page itself. Well all the links that refer to a speech.
library(rvest)
url <- "http://www.obamaspeeches.com/"
links <- read_html(url) %>% html_nodes("a") %>% html_attr("href")
links[c(1:2,110:114)]## [1] "/P-Obama-Inaugural-Speech-Inauguration.htm"
## [2] "/E11-Barack-Obama-Election-Night-Victory-Speech-Grant-Park-Illinois-November-4-2008.htm"
## [3] "003-John-Lewis-65th-Birthday-Gala-Obama-Speech.htm"
## [4] "002-Keynote-Address-at-the-2004-Democratic-National-Convention-Obama-Speech.htm"
## [5] "001-2002-Speech-Against-the-Iraq-War-Obama-Speech.htm"
## [6] "http://www.cafepress.com/obamaquotes"
## [7] "http://www.amazon.com/INSPIRE-NATION-Electrifying-Speeches-Inauguration/dp/0982100531/?tag=obama-speeches-com-20"So there are about 114 speeches but the last couple of elements don’t appear to relate to the speeches so we’ll pull them from the list:
links[c(length(links)-3):length(links)]## [1] "002-Keynote-Address-at-the-2004-Democratic-National-Convention-Obama-Speech.htm"
## [2] "001-2002-Speech-Against-the-Iraq-War-Obama-Speech.htm"
## [3] "http://www.cafepress.com/obamaquotes"
## [4] "http://www.amazon.com/INSPIRE-NATION-Electrifying-Speeches-Inauguration/dp/0982100531/?tag=obama-speeches-com-20"I’m going to formalize this a bit more and make it better because it turns out that some of the speech links on that page are duplicated. Besides, I also want to get back the full link so I can access it and download the text.
linkScraper <- function(baseurl="http://obamaspeeches.com") {
#
# Function to grab links from the Obama Speech site
# http://obamaspeeches.com/
#
suppressMessages(library(rvest))
url <- "http://obamaspeeches.com/"
links <- read_html(url) %>% html_nodes("a") %>% html_attr("href")
links <- gsub("/","",links)
cleaned_links <- links[-grep("http",links)]
cleaned_links <- cleaned_links[!duplicated(cleaned_links)]
retlinks <- paste("http://obamaspeeches.com",cleaned_links,sep="/")
return(retlinks)
}obamalinks <- linkScraper()
obamalinks[3:10]## [1] "http://obamaspeeches.com/E-Barack-Obama-Speech-Manassas-Virgina-Last-Rally-2008-Election.htm"
## [2] "http://obamaspeeches.com/E10-Barack-Obama-The-American-Promise-Acceptance-Speech-at-the-Democratic-Convention-Mile-High-Stadium--Denver-Colorado-August-28-2008.htm"
## [3] "http://obamaspeeches.com/E09-Barack-Obama-Final-Primary-Night-Presumptive-Democratic-Nominee-Speech-St-Paul-Minnesota-June-3-2008.htm"
## [4] "http://obamaspeeches.com/E08-Barack-Obama-North-Carolina-Primary-Night-Raleigh-NC-May-6-2008.htm"
## [5] "http://obamaspeeches.com/E07-Barack-Obama-Pennsylvania-Primary-Night-Evansville-Indiana-April-22-2008.htm"
## [6] "http://obamaspeeches.com/E06-Barack-Obama-AP-Annual-Luncheon-Washington-DC-April-14-2008-religion-guns-pennsylvania.htm"
## [7] "http://obamaspeeches.com/E05-Barack-Obama-A-More-Perfect-Union-the-Race-Speech-Philadelphia-PA-March-18-2008.htm"
## [8] "http://obamaspeeches.com/E04-Barack-Obama-March-4-Primary-Night-Texas-and-Ohio-San-Antonio-TX-March-4-2008.htm"Now let’s get the actual speech content. Not only will we get the speech content but we will keep track of the specific speech number from whence the text came. So we will create a factor that let’s us identify each speech by a number. We don’t have to do this if we want to consider all the speeches text as one big “blob”.
obamaParse <- function(url,write=FALSE) {
library(rvest)
retlist <- list()
df <- data.frame()
for (ii in 1:length(url)) {
page <- read_html(url[ii]) %>% html_nodes("p") %>% html_text()
# The following gets rid of some links that don't work. See, this is
# the crap you have to deal with when working with real data
val <- grep("Against the Iraq",page)
page <- page[-1:-val]
# Now we also want to get rid of numbers since they generally
# don't mean very much in text analysis.
page_nonum <- as.vector(lapply(page,function(x) gsub("[0-9]+","",x)))
# We populate each list element with a one line data frame which
# contains the text of one speech and its associated "book" number
# e.g. 1,2,3... for the length of the url argument
retlist[[ii]] <- data.frame(text=page,book=as.character(ii),
stringsAsFactors = FALSE)
# Return the page
}
df <- do.call(rbind,retlist)
return(df)
}Let’s get just 9 speeches to make things manageable.
out <- obamaParse(obamalinks[2:12])speeches <- out %>% group_by(book) %>%
mutate(linenumber = row_number()) %>% ungroup()
speeches## # A tibble: 472 x 3
## text book linenumber
## <chr> <chr> <int>
## 1 "Election Night Victory Speech \n Grant P… 1 1
## 2 "" 1 2
## 3 "If \n there is anyone out there who stil… 1 3
## 4 "It’s \n the answer told by lines that st… 1 4
## 5 "It’s \n the answer spoken by young and o… 1 5
## 6 "It’s \n the answer that led those who ha… 1 6
## 7 "It’s \n been a long time coming, but ton… 1 7
## 8 "I just \n received a very gracious call … 1 8
## 9 "I want \n to thank my partner in this jo… 1 9
## 10 "I would \n not be standing here tonight … 1 10
## # … with 462 more rows4.7 Exploring The Text
So there are some general activities common to text explorations. Let’s summarize:
- Collections of text (one or more documents) can be called a corpus
- We tend to break up documents into words and treat them as a bag of words
- Getting the text into a tidy format is importnat. The tidytext package helps.
- Basically we get each word of a phrase or document onto its own line a data frame
- We then remove stop words which are filler words that don’t mean much
- We might also get rid of numbers
- Next, we stem the words (e.g. america and americas are really the same word)
The tidytext package is what we will use here although there a number of R packages that take a more traditional approach to analyzing text such as the tm package. There is also RWeka and the qdap packages that help work with text data.
You might also encounter references to things like Term Document Matrices or Document Term Matrices which are sparse matrix structures that help count the number of times a word occurs in a given set of documents. The transpose of a Document Term Matrix can be thought of as a Document Term Matrix.

Here is a very brief walkthrough on how you could do some text explorations using the tm package:
# https://stackoverflow.com/questions/24703920/r-tm-package-vcorpus-error-in-converting-corpus-to-data-frame#24704075
suppressMessages(library(tm))
library("wordcloud")
library("RColorBrewer")
# Create a vector with text
x <- c("Hello. Sir!","Tacos? On Tuesday?!?", "Hello")
# We create a Corpus
mycorpus <- Corpus(VectorSource(x))
# Get rid of the punctuation
mycorpus <- tm_map(mycorpus, removePunctuation)## Warning in tm_map.SimpleCorpus(mycorpus, removePunctuation): transformation
## drops documents# Create a Term Document Matrix
dtm <- TermDocumentMatrix(mycorpus)
# We can turn it onto a matrix to be read by humans
m <- as.matrix(dtm)
v <- sort(rowSums(m),decreasing=TRUE)
d <- data.frame(word = names(v),freq=v)
head(d, 10)## word freq
## hello hello 2
## sir sir 1
## tacos tacos 1
## tuesday tuesday 1set.seed(1234)
wordcloud(words = d$word, freq = d$freq, min.freq = 1,
max.words=200, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"))
https://gerardnico.com/natural_language/term_document
The strengths of tm are that it more closely aligns with the traditional text mining terminology and approaches. There are also a number of tools and packages that work well with tm that do not work well directly with the tidytext approach. But there are now approaches and functions in tidytext that address this concern which can take, for example, a Term Document Matrixx and turn it into a tidy data frame.
4.7.1 Tidy Format
In this class you have encountered previous references the tidyverse and tools such as those found in dplyr. It shouldn’t be surprising then that the tidytext package has text analysis tools that fit in nicely with the tidyverse.
4.7.2 Tidy Up the text
Let’s look at the speeches data frame
speeches## # A tibble: 472 x 3
## text book linenumber
## <chr> <chr> <int>
## 1 "Election Night Victory Speech \n Grant P… 1 1
## 2 "" 1 2
## 3 "If \n there is anyone out there who stil… 1 3
## 4 "It’s \n the answer told by lines that st… 1 4
## 5 "It’s \n the answer spoken by young and o… 1 5
## 6 "It’s \n the answer that led those who ha… 1 6
## 7 "It’s \n been a long time coming, but ton… 1 7
## 8 "I just \n received a very gracious call … 1 8
## 9 "I want \n to thank my partner in this jo… 1 9
## 10 "I would \n not be standing here tonight … 1 10
## # … with 462 more rowsThis looks bad because the text still has junk characters in it. Each row also has a long stringy line of text (in the text column) that is not only hard to read but if we wanted to compute on the text it would be very inconvenient. It might better to first break up the long obnoxious looking line into individual words.
library(tidytext)
tidy_speeches <- speeches %>%
unnest_tokens(word, text)
tidy_speeches## # A tibble: 27,849 x 3
## book linenumber word
## <chr> <int> <chr>
## 1 1 1 election
## 2 1 1 night
## 3 1 1 victory
## 4 1 1 speech
## 5 1 1 grant
## 6 1 1 park
## 7 1 1 illinois
## 8 1 1 november
## 9 1 1 4
## 10 1 1 2008
## # … with 27,839 more rows4.7.3 Dump The “Stop Words”
So we have some more work to do. Let’s get rid of common words that don’t substantially add ot the comprehensibility of the information. There is a built in data frame called stop_words that we can use to filter out such useless words (well for purposes of information retrrieval anyway).
data(stop_words)
tidy_speeches_nostop <- tidy_speeches %>%
anti_join(stop_words)## Joining, by = "word"4.7.4 Eliminate Numbers
Let’s also remove numbers from the words.
# remove numbers
nums <- tidy_speeches_nostop %>%
filter(str_detect(word, "^[0-9]")) %>%
select(word) %>% unique()
tidy_speeches_nostop_nonums <- tidy_speeches_nostop %>%
anti_join(nums, by = "word")tidy_speeches_nostop_nonums %>%
count(word, sort = TRUE) ## # A tibble: 2,736 x 2
## word n
## <chr> <int>
## 1 change 106
## 2 time 105
## 3 people 99
## 4 america 98
## 5 american 94
## 6 country 90
## 7 americans 55
## 8 care 54
## 9 washington 54
## 10 campaign 52
## # … with 2,726 more rows4.7.5 Stemming
Some of these words need to be “stemmed” - such as “american” and “americans”. There is a function in the snowballC package that will allow us to do this. Here is an example.
some_words <- c("america","americas","american","cat","cats","catastrophe")
wordStem(some_words)## [1] "america" "america" "american" "cat" "cat"
## [6] "catastroph"tidy_speeches_nostop_nonums_stem <- tidy_speeches_nostop_nonums %>%
mutate(word_stem = wordStem(word))
tidy_speeches_nostop_nonums_stem## # A tibble: 9,412 x 4
## book linenumber word word_stem
## <chr> <int> <chr> <chr>
## 1 1 1 election elect
## 2 1 1 night night
## 3 1 1 victory victori
## 4 1 1 speech speech
## 5 1 1 grant grant
## 6 1 1 park park
## 7 1 1 illinois illinoi
## 8 1 1 november novemb
## 9 1 3 doubts doubt
## 10 1 3 america america
## # … with 9,402 more rows4.7.6 Bar Plots
library(ggplot2)
tidy_speeches_nostop_nonums_stem %>%
count(word_stem, sort = TRUE) %>% filter(n > 40) %>%
mutate(word_stem = reorder(word_stem, n)) %>%
ggplot(aes(word_stem, n)) +
geom_col() +
xlab(NULL) +
coord_flip()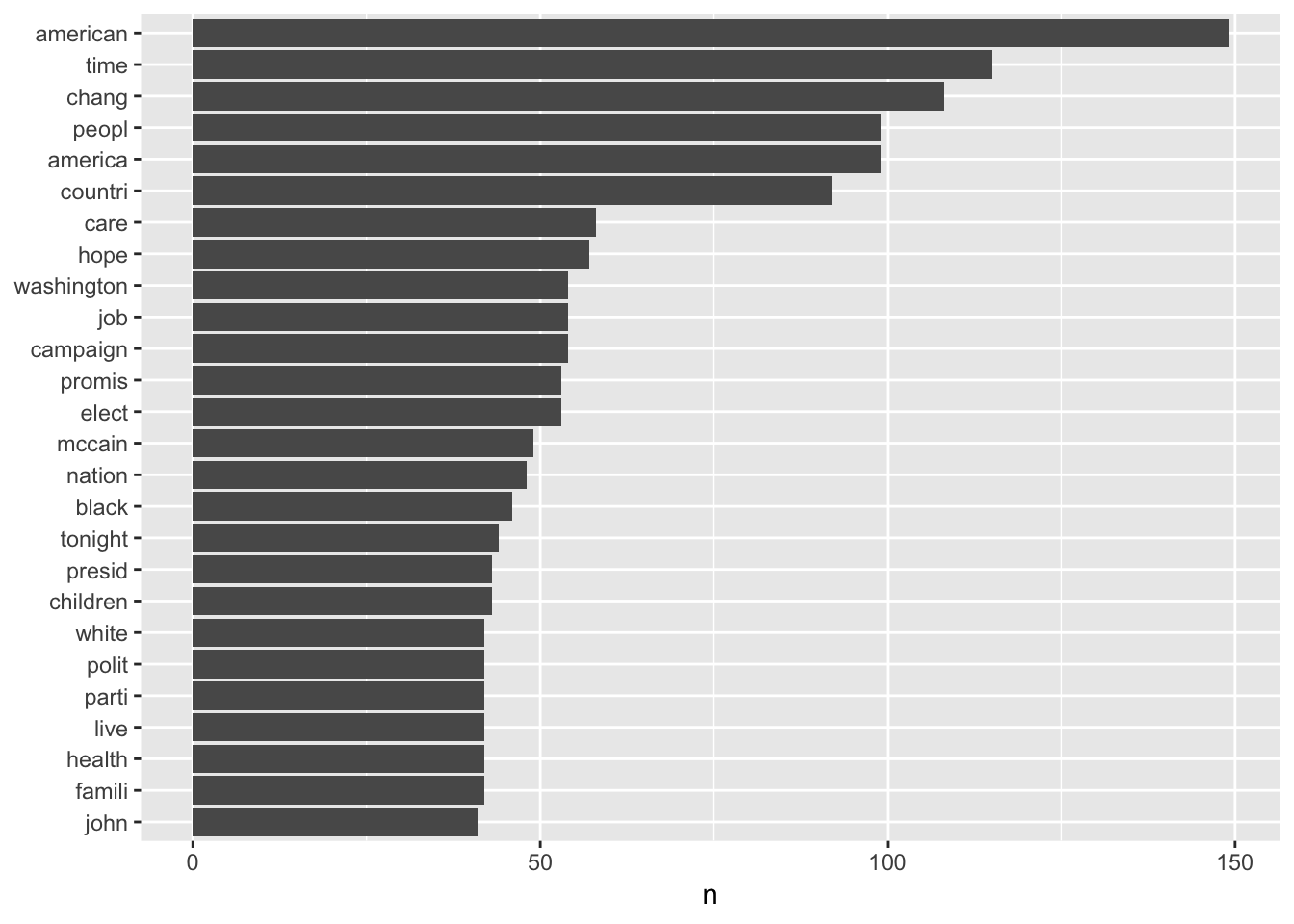
http://jacobsimmering.com/2016/11/15/tidytext/
library(tidyr)
frequency <- tidy_speeches_nostop_nonums_stem %>%
count(book,word_stem) %>%
group_by(book) %>%
mutate(proportion = n / sum(n)) %>%
select(-n) %>%
spread(book, proportion) %>%
gather(book, proportion, `1`:`9`)tidy_speeches_nostop_nonums_stem %>% count(book,word_stem,sort=TRUE) %>%
filter(n > 14) %>%
ggplot(aes(word_stem, n)) +
geom_col() +
xlab(NULL) +
coord_flip() + facet_grid(book ~ .)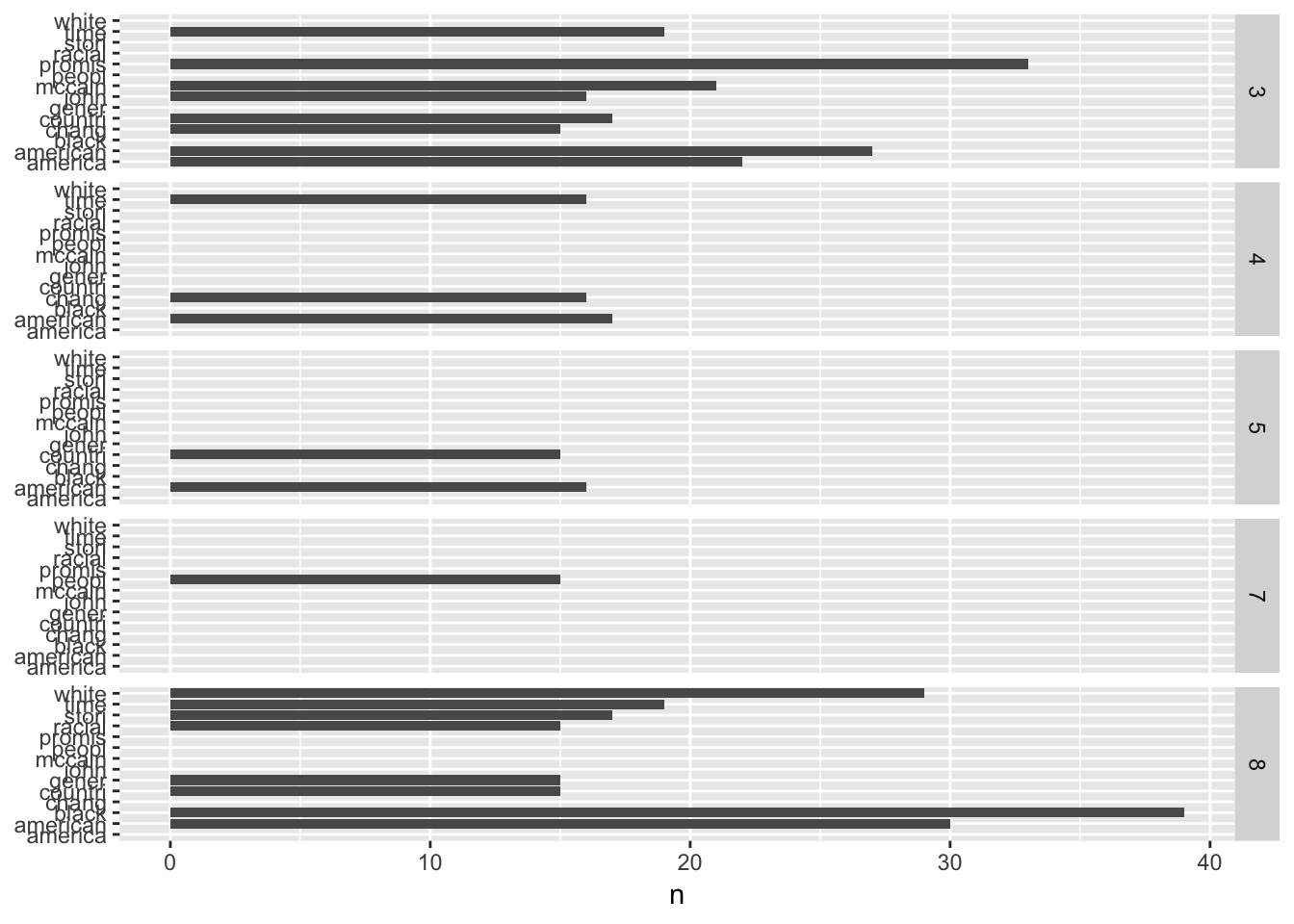
tidy_speeches_nostop_nonums_stem %>% count(book, word_stem, sort = TRUE) %>%
group_by(book) %>%
top_n(5) %>%
ungroup() %>%
ggplot(aes(reorder_within(word_stem, n, book), n,fill = book)) +
geom_col(alpha = 0.8, show.legend = FALSE) +
scale_x_reordered() +
coord_flip() +
facet_wrap(~book, scales = "free") +
scale_y_continuous(expand = c(0, 0)) +
labs(
x = NULL, y = "Word count",
title = "Most frequent words after removing stop words"
)## Selecting by n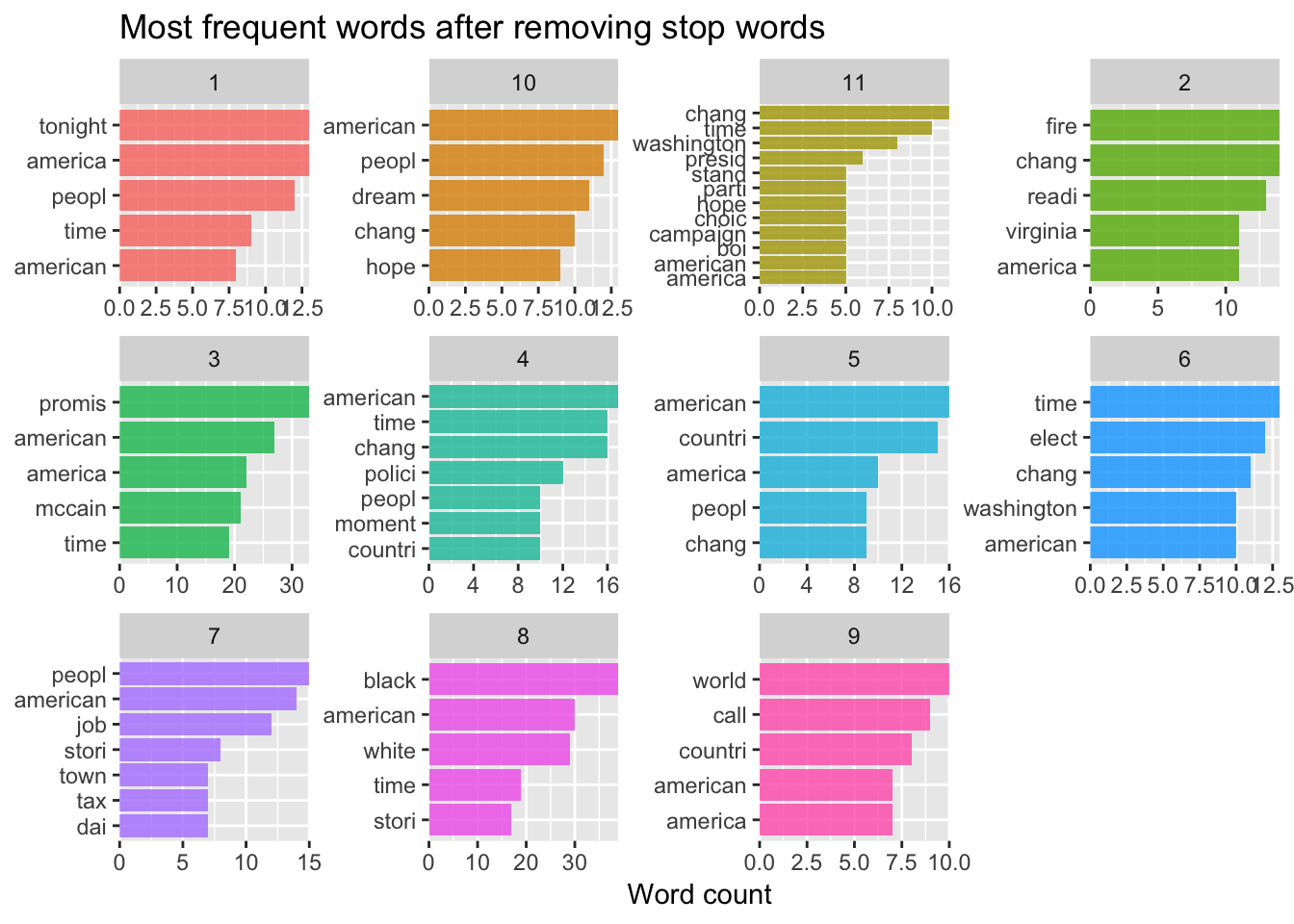
https://richpauloo.github.io/2017-12-29-Using-tidytext-to-make-word-clouds/
4.7.7 Wordclouds
One of the premier visualizations for text documents is the word cloud. You see this a lot in newsletters and on flyers since word clouds show you frequently occurring topics in a way that makes it obvious what the most mentioned words are.
pal <- brewer.pal(8,"Dark2")
# plot the 50 most common words
tidy_speeches_nostop_nonums_stem %>%
count(word_stem, sort = TRUE) %>%
with(wordcloud(word_stem, n, random.order = FALSE, max.words = 50, colors=pal))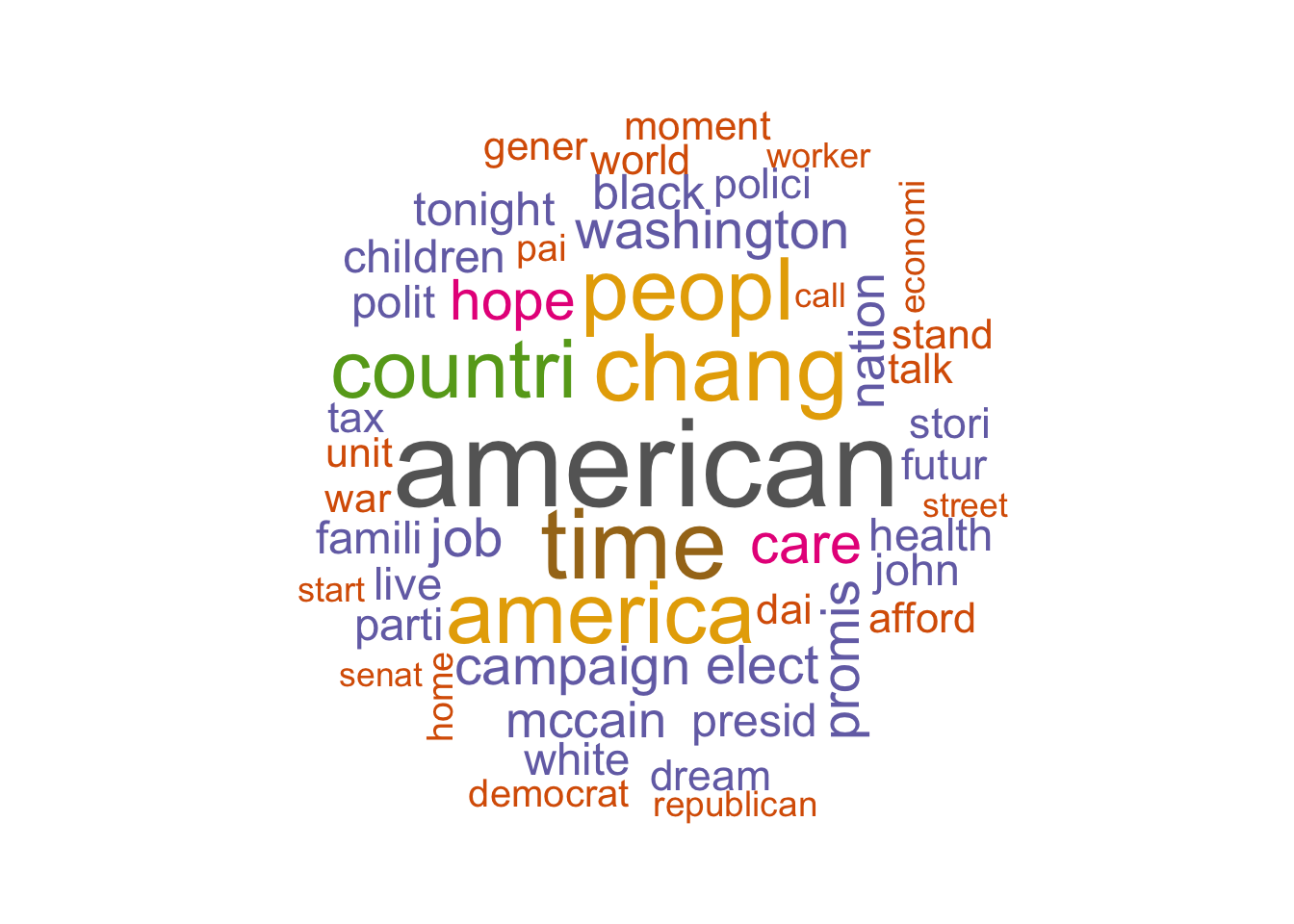
See https://shiring.github.io/text_analysis/2017/06/28/twitter_post
4.8 Term Frequency
As mentioned in the previous section, much of the content of a collectio of text contains lots of “filler” words such as “the”,“a”,“an”,“as”,“is”,“at”,“which”. Identifying these words is important in text mining and in search engine technology since you generally want to avoid them as they can interfere with a getting a good result. Stop words are also language dependent.
Moreover, a given domain also has stop words. For example, when considering documents or tweets that mention kidney disease you might want to filter out specific references to “kidney disease” since you already know that you are considering kidney disease. So you might want to remove those obvious references and drill down into other words and phrases that might be important.

https://dev.mysql.com/doc/refman/5.5/en/fulltext-stopwords.html
4.8.1 Back To The Speeches
Let’s look at some examples of term frequency using collections of speeches from Obama and Romney when they were both candidates. I have two folders with 50 speeches each.
library(readtext) # Makes it easy to read in raw text files
# We have a folder with about 50 Obama Speeches
setwd("~/Downloads/Candidates/OBAMA")
filenames <- list.files( pattern="*", full.names=TRUE)
suppressWarnings(obama <- lapply(filenames, readtext))
collected_obama <- sapply(obama,function(x) x$text)
length(collected_obama)## [1] 48# Now Let's get this into tidy text. We will also put a column
# that marks the text with its respective source ("Obama","Romney")
obama_df <- tibble(line=1:length(collected_obama),
text=collected_obama,
book="obama")
# Let's tidy this up in accordance with tidy principles
tidy_obama_df <- obama_df %>%
unnest_tokens(word, text)
tidy_obama_df## # A tibble: 188,999 x 3
## line book word
## <int> <chr> <chr>
## 1 1 obama a
## 2 1 obama couple
## 3 1 obama of
## 4 1 obama people
## 5 1 obama i
## 6 1 obama just
## 7 1 obama want
## 8 1 obama to
## 9 1 obama acknowledge
## 10 1 obama first
## # … with 188,989 more rowsNext we will do the same for the Romney speeches.
# We have about 50 speeches from Romney
setwd("~/Downloads/Candidates/ROMNEY")
filenames <- list.files( pattern="*", full.names=TRUE)
suppressWarnings(romney <- lapply(filenames, readtext))
collected_romney <- sapply(romney,function(x) x$text)
length(collected_romney)## [1] 49# Now Let's get this into tidy text
rom_df <- tibble(line=1:length(collected_romney),
text=collected_romney,
book="romney")
tidy_romney_df <- rom_df %>%
unnest_tokens(word, text)
# Let's combine the two data frames
combined_tidy_speech <- rbind(tidy_obama_df,tidy_romney_df)
# Count the total number of speech words per candidate
combined_tidy_speech %>% group_by(book) %>% summarize(count=n())## # A tibble: 2 x 2
## book count
## <chr> <int>
## 1 obama 188999
## 2 romney 90229Next we’ll count the number of times each word occurs within speeches for each candidate:
# Get number of times a word occurs within a speech
# per candidate
book_words <- combined_tidy_speech %>%
count(book, word, sort=TRUE)
# Get the total number of words in each speech collection
total_words <- book_words %>%
group_by(book) %>%
summarize(total = sum(n))So now we can join these two data frames. What we get for our trouble is way to compute the frequency of a given term within each speech collection for each candidate. This provides information on what terms occur with great frequency and those that do not. We can plot these.
book_words <- left_join(book_words, total_words)## Joining, by = "book"book_words## # A tibble: 11,515 x 4
## book word n total
## <chr> <chr> <int> <int>
## 1 obama the 7306 188999
## 2 obama to 6579 188999
## 3 obama and 6287 188999
## 4 romney the 4364 90229
## 5 obama that 4050 188999
## 6 obama a 3776 188999
## 7 romney and 3420 90229
## 8 obama of 3361 188999
## 9 obama you 3341 188999
## 10 obama in 3115 188999
## # … with 11,505 more rowslibrary(ggplot2)
ggplot(book_words, aes(n/total, fill = book)) +
geom_histogram(show.legend = FALSE) +
xlim(NA, 0.0009) +
facet_wrap(~book, ncol = 2, scales = "free_y")## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 359 rows containing non-finite values (stat_bin).## Warning: Removed 2 rows containing missing values (geom_bar).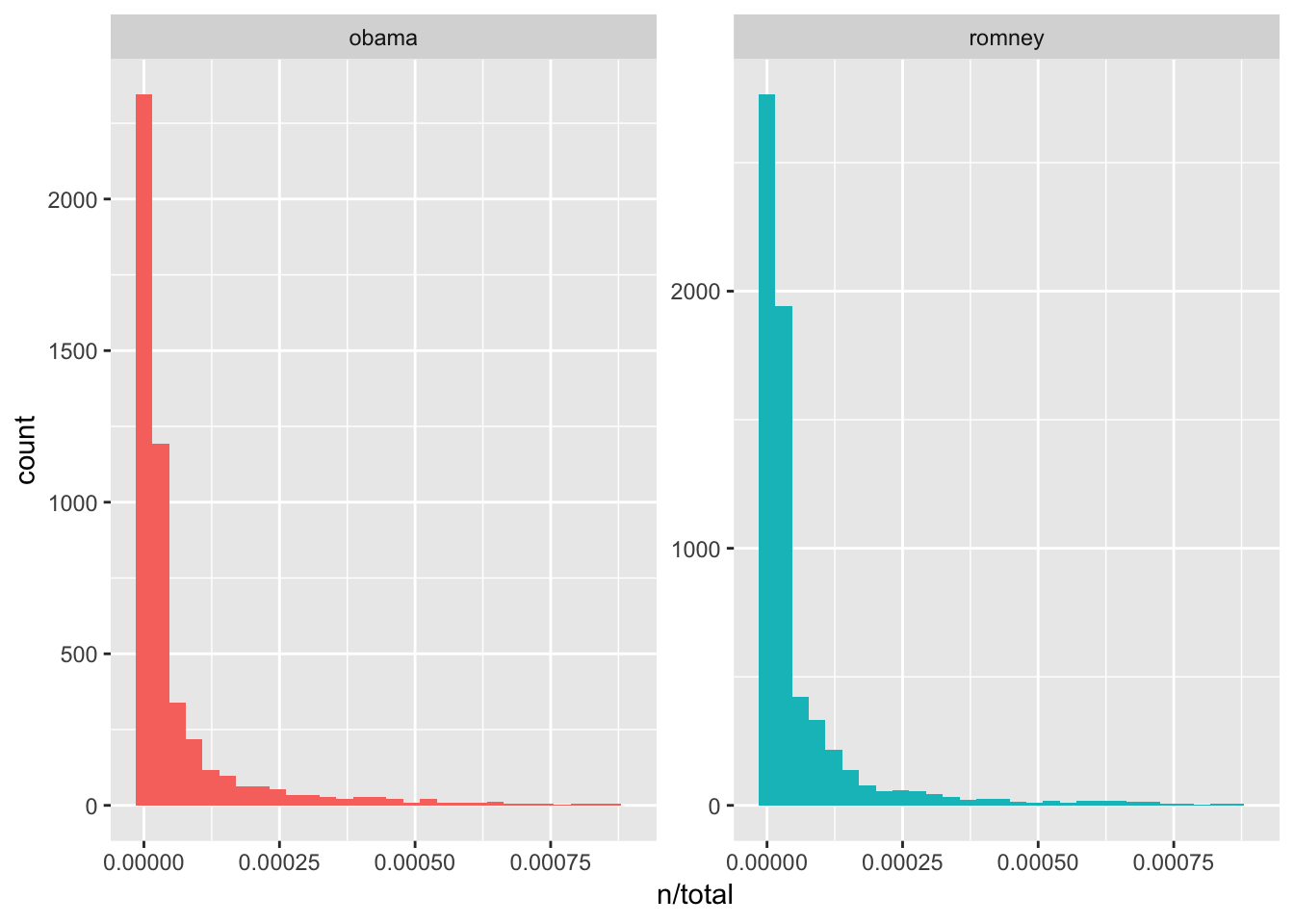
4.9 Tf and Idf
A central question in text mining and natural language processing is how to quantify what a document is about. One measure of how important a word may be is its term frequency (tf), how frequently a word occurs in a document
We could use a list of stop words but it’s not always the most sophisticated approach to adjusting term frequency for commonly used words.
Another approach is to look at a term’s inverse document frequency (idf), which decreases the weight for commonly used words and increases the weight for words that are not used very much in a collection of documents. This can be combined with term frequency to calculate a term’s tf-idf (the two quantities multiplied together), the frequency of a term adjusted for how rarely it is used. t-idf similarity
https://www.tidytextmining.com/tfidf.html
The statistic tf-idf is intended to measure how important a word is to a document in a collection (or corpus) of documents, for example, to one novel in a collection of novels or to one website in a collection of websites.
We can use the bind_tf_idf function to compute tf, and idf for us. Furthermore it will bind this information onto a tidy text data frame.
book_words <- book_words %>%
bind_tf_idf(word, book, n)
book_words## # A tibble: 11,515 x 7
## book word n total tf idf tf_idf
## <chr> <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 obama the 7306 188999 0.0387 0 0
## 2 obama to 6579 188999 0.0348 0 0
## 3 obama and 6287 188999 0.0333 0 0
## 4 romney the 4364 90229 0.0484 0 0
## 5 obama that 4050 188999 0.0214 0 0
## 6 obama a 3776 188999 0.0200 0 0
## 7 romney and 3420 90229 0.0379 0 0
## 8 obama of 3361 188999 0.0178 0 0
## 9 obama you 3341 188999 0.0177 0 0
## 10 obama in 3115 188999 0.0165 0 0
## # … with 11,505 more rowsLet’s look at a sorted list get the high tf_idf words
book_words %>%
select(-total) %>%
arrange(desc(tf_idf))## # A tibble: 11,515 x 6
## book word n tf idf tf_idf
## <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 romney в 106 0.00117 0.693 0.000814
## 2 obama boo 200 0.00106 0.693 0.000733
## 3 romney enterprise 57 0.000632 0.693 0.000438
## 4 romney president's 55 0.000610 0.693 0.000423
## 5 obama 250,000 107 0.000566 0.693 0.000392
## 6 obama bargain 100 0.000529 0.693 0.000367
## 7 obama michelle 98 0.000519 0.693 0.000359
## 8 romney nations 44 0.000488 0.693 0.000338
## 9 obama outstanding 82 0.000434 0.693 0.000301
## 10 romney iran 38 0.000421 0.693 0.000292
## # … with 11,505 more rowsWe can plot this information
book_words %>%
arrange(desc(tf_idf)) %>%
mutate(word = factor(word, levels = rev(unique(word)))) %>%
group_by(book) %>%
top_n(15) %>%
ungroup() %>%
ggplot(aes(word, tf_idf, fill = book)) +
geom_col(show.legend = FALSE) +
labs(x = NULL, y = "tf-idf") +
facet_wrap(~book, ncol = 2, scales = "free") +
coord_flip()## Selecting by tf_idf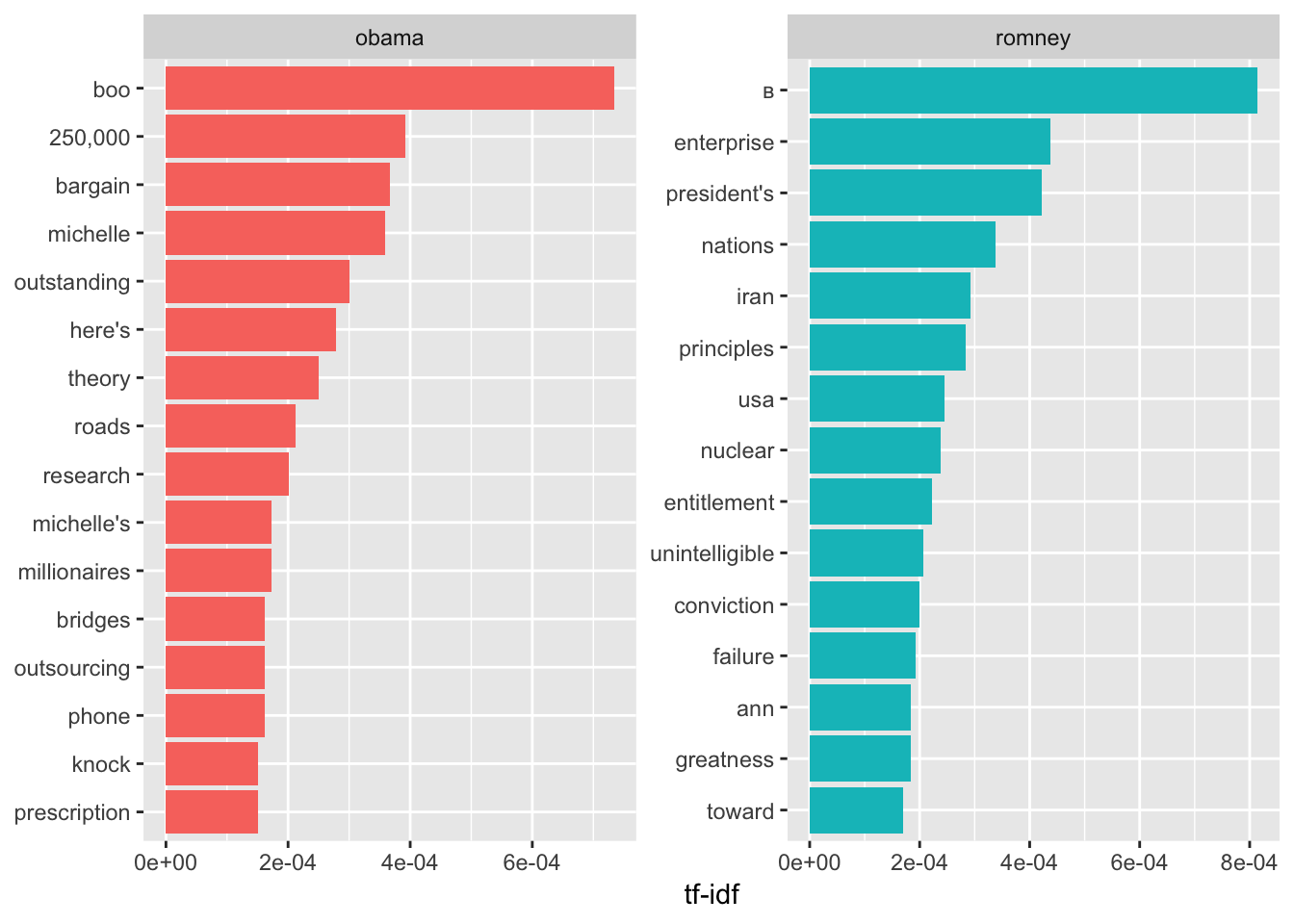
data(stop_words)
book_words %>%
arrange(desc(tf_idf)) %>%
mutate(word = factor(word, levels = rev(unique(word)))) %>%
group_by(book) %>%
top_n(15) %>%
ungroup() %>%
ggplot(aes(word, tf_idf, fill = book)) +
geom_col(show.legend = FALSE) +
labs(x = NULL, y = "tf-idf") +
facet_wrap(~book, ncol = 2, scales = "free") +
coord_flip()## Selecting by tf_idf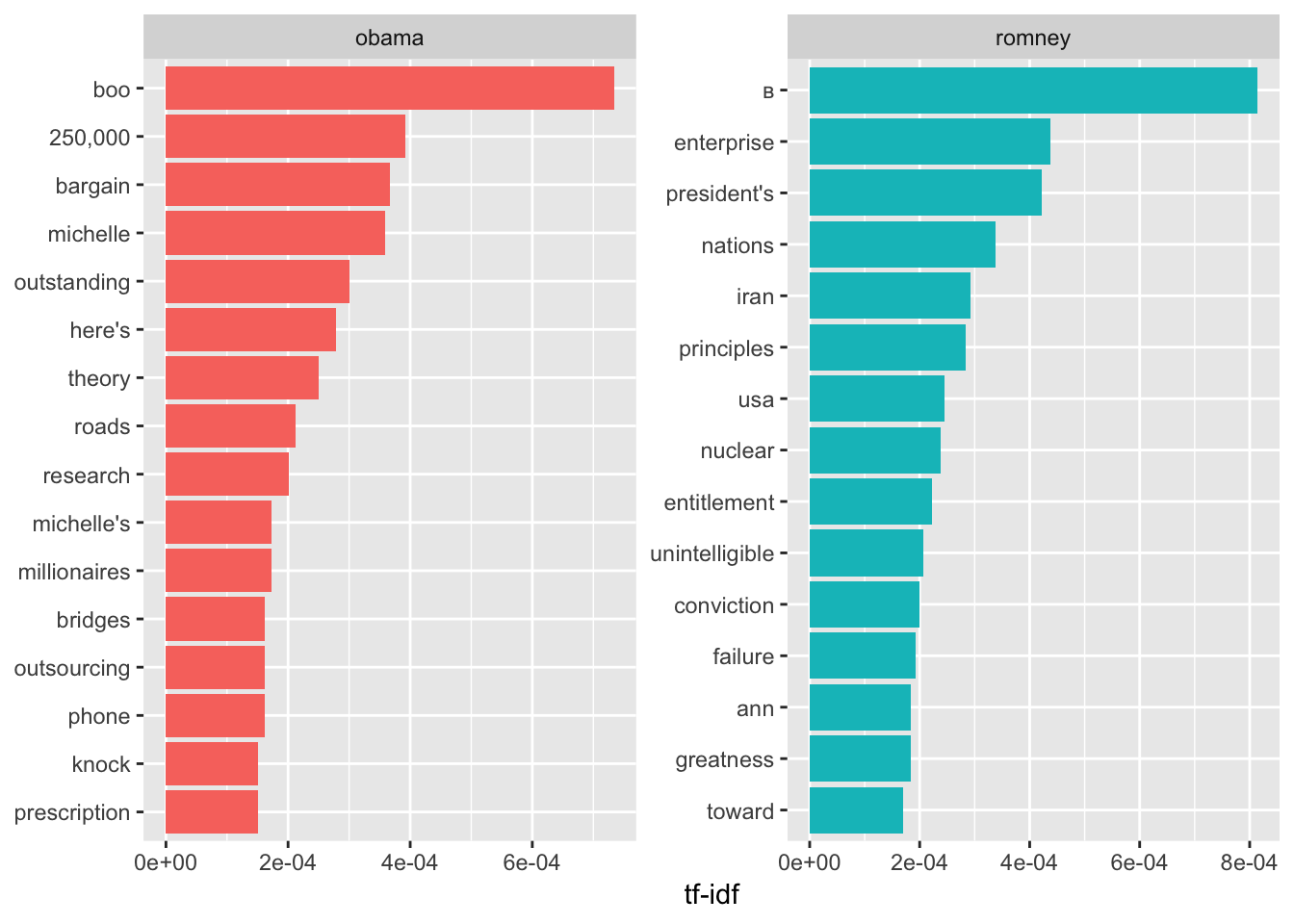
4.10 Sentiment
Attempting to understand the feeling associated with words is a complicated business especially given that context can drastically change the meaning of words and phrases. Consider the following statements. To a human the sentiment is obvious. The third statement reflects sarcasm which is notoriously difficult for an algorithm to pick up.
I had a good flight experience on Delta airlines.
I had a bad flight experience on Delta airlines.
Gee thanks Delta for losing my luggage.4.10.1 Sentiment Dictionaries and Lexicons
The tidytext package has a data frame called sentiments which has three lexicons that will help us figure out the emotional value of words. Each dictionary handles sentiment assessment differently.
The nrc dictionary applies a single word emotional description to a text word Of course a word in a piece of text can be associated with different emotions. The possible sentiments are:
unique(get_sentiments("nrc")$sentiment)## [1] "trust" "fear" "negative" "sadness"
## [5] "anger" "surprise" "positive" "disgust"
## [9] "joy" "anticipation"Next there is the the afinn dictionary which presents a range of scores from -5 to 5 which coincides with a range of negative to positive emotion - although the rating is “stepped” (i.e. integers).
get_sentiments("afinn") %>% head(.)## # A tibble: 6 x 2
## word score
## <chr> <int>
## 1 abandon -2
## 2 abandoned -2
## 3 abandons -2
## 4 abducted -2
## 5 abduction -2
## 6 abductions -2get_sentiments("afinn") %>% select('score') %>% range(.)## [1] -5 5The bing lexicon offers a binary assessment of emotion. It’s either “negative” or “positive” so there is no continuum of emotion.
unique(get_sentiments("bing")$sentiment)## [1] "negative" "positive"#
get_sentiments("bing") %>% head()## # A tibble: 6 x 2
## word sentiment
## <chr> <chr>
## 1 2-faced negative
## 2 2-faces negative
## 3 a+ positive
## 4 abnormal negative
## 5 abolish negative
## 6 abominable negativeSo next up there is the loughran lecxicon which is appropriate for financial and business contexts:
unique(get_sentiments("loughran")$sentiment)## [1] "negative" "positive" "uncertainty" "litigious"
## [5] "constraining" "superfluous"4.10.2 An Example
head(sentiments)## # A tibble: 6 x 4
## word sentiment lexicon score
## <chr> <chr> <chr> <int>
## 1 abacus trust nrc NA
## 2 abandon fear nrc NA
## 3 abandon negative nrc NA
## 4 abandon sadness nrc NA
## 5 abandoned anger nrc NA
## 6 abandoned fear nrc NAtxt <- c("I had a good flight experience on Delta airlines",
"I had a bad flight experience on Delta airlines",
"Gee thanks Delta for losing my luggage")
df <- tibble(1:length(txt),text=txt)
df <- df %>% unnest_tokens(word,text)
# We get rid of the stop words and then see what the nrc sentiment
# dictionary tells us about our data
df %>% anti_join(stop_words) %>% left_join(get_sentiments("nrc"))## Joining, by = "word"
## Joining, by = "word"## # A tibble: 19 x 3
## `1:length(txt)` word sentiment
## <int> <chr> <chr>
## 1 1 flight <NA>
## 2 1 experience <NA>
## 3 1 delta <NA>
## 4 1 airlines <NA>
## 5 2 bad anger
## 6 2 bad disgust
## 7 2 bad fear
## 8 2 bad negative
## 9 2 bad sadness
## 10 2 flight <NA>
## 11 2 experience <NA>
## 12 2 delta <NA>
## 13 2 airlines <NA>
## 14 3 gee <NA>
## 15 3 delta <NA>
## 16 3 losing anger
## 17 3 losing negative
## 18 3 losing sadness
## 19 3 luggage <NA>df %>% anti_join(stop_words) %>% left_join(get_sentiments("bing"))## Joining, by = "word"
## Joining, by = "word"## # A tibble: 13 x 3
## `1:length(txt)` word sentiment
## <int> <chr> <chr>
## 1 1 flight <NA>
## 2 1 experience <NA>
## 3 1 delta <NA>
## 4 1 airlines <NA>
## 5 2 bad negative
## 6 2 flight <NA>
## 7 2 experience <NA>
## 8 2 delta <NA>
## 9 2 airlines <NA>
## 10 3 gee <NA>
## 11 3 delta <NA>
## 12 3 losing negative
## 13 3 luggage <NA>df %>% anti_join(stop_words) %>% left_join(get_sentiments("afinn"))## Joining, by = "word"
## Joining, by = "word"## # A tibble: 13 x 3
## `1:length(txt)` word score
## <int> <chr> <int>
## 1 1 flight NA
## 2 1 experience NA
## 3 1 delta NA
## 4 1 airlines NA
## 5 2 bad -3
## 6 2 flight NA
## 7 2 experience NA
## 8 2 delta NA
## 9 2 airlines NA
## 10 3 gee NA
## 11 3 delta NA
## 12 3 losing -3
## 13 3 luggage NA4.10.3 Speech Sentiment
Let’s apply our new found knowledge of sentiment tools to the combined speeches of Romney and Obama. We might want to get some sense of how emotive their respective sets of speeches are. We might also want to look at the emotive range for all speches combined independently of the candidate. Of course, these are political speeches so you know up front that there will be a bias towards positive language. So here we will join the words from all speeches to the bing sentiment lexicon to rate the emotional content of the words comprising the speech. Note that many words in the speeches will not have an emotional equivalent because they don’t exist in the lexicon. This is why you should use a stop word approach or consider using a Term Frequency - Inverse frequency approach to first eliminate filler words.
bing_word_counts <- combined_tidy_speech %>%
inner_join(get_sentiments("bing")) %>%
count(book, word, sentiment, sort = TRUE) %>%
ungroup()## Joining, by = "word"So let’s look at some of the emotional content of the speeches independently of candidate (i.e. all speeches combined).
bing_word_counts %>%
group_by(sentiment) %>%
top_n(15) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment, scales = "free_y") +
labs(y = "Contribution to sentiment",
x = NULL) +
coord_flip()## Selecting by n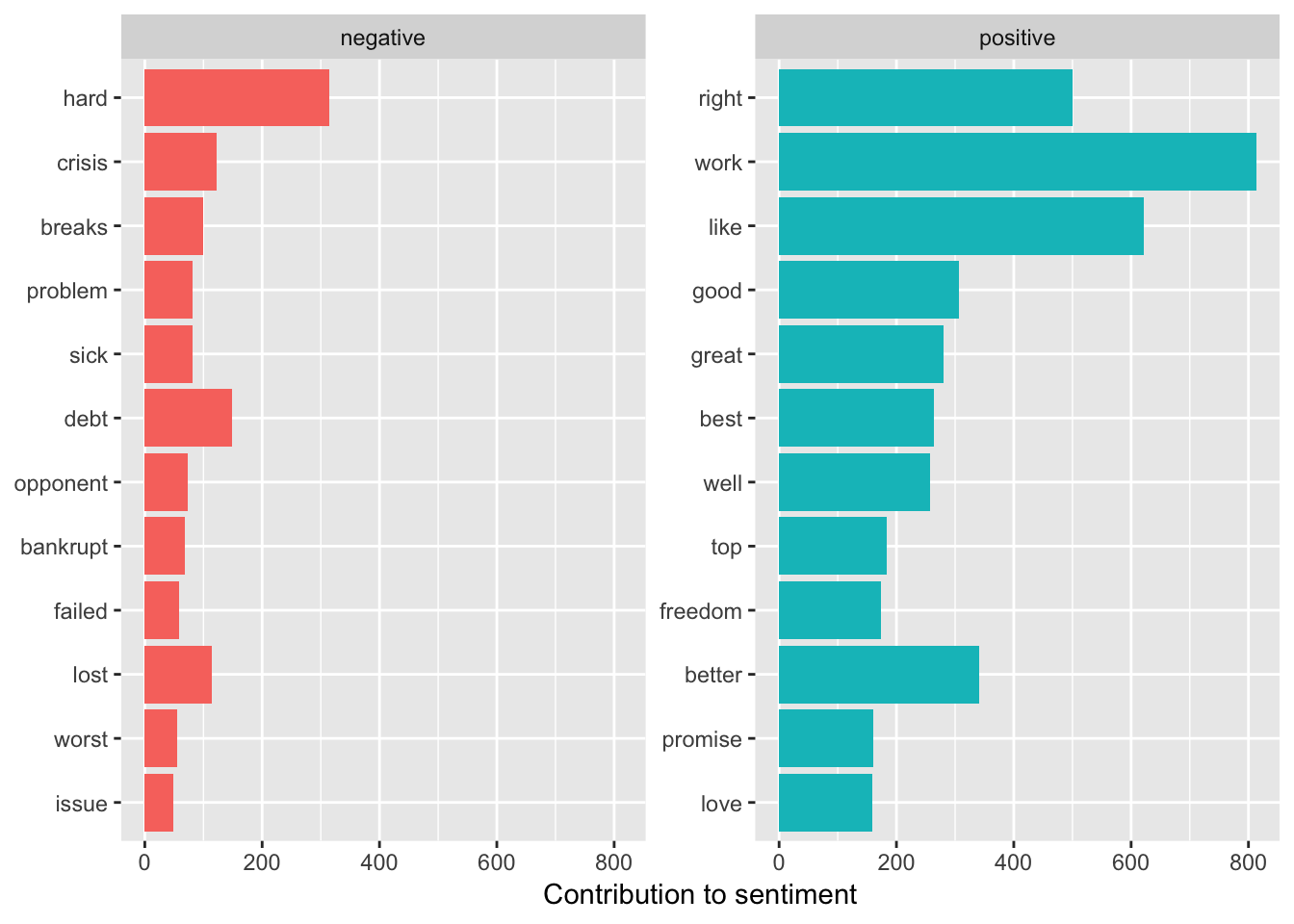
It’s also really easy to look at the emotions for each candidate just by using the book variable from the bing_word_counts data frame.
bing_word_counts %>%
group_by(sentiment) %>%
top_n(15) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment+book, scales = "free_y") +
labs(y = "Contribution to sentiment",
x = NULL) +
coord_flip()## Selecting by n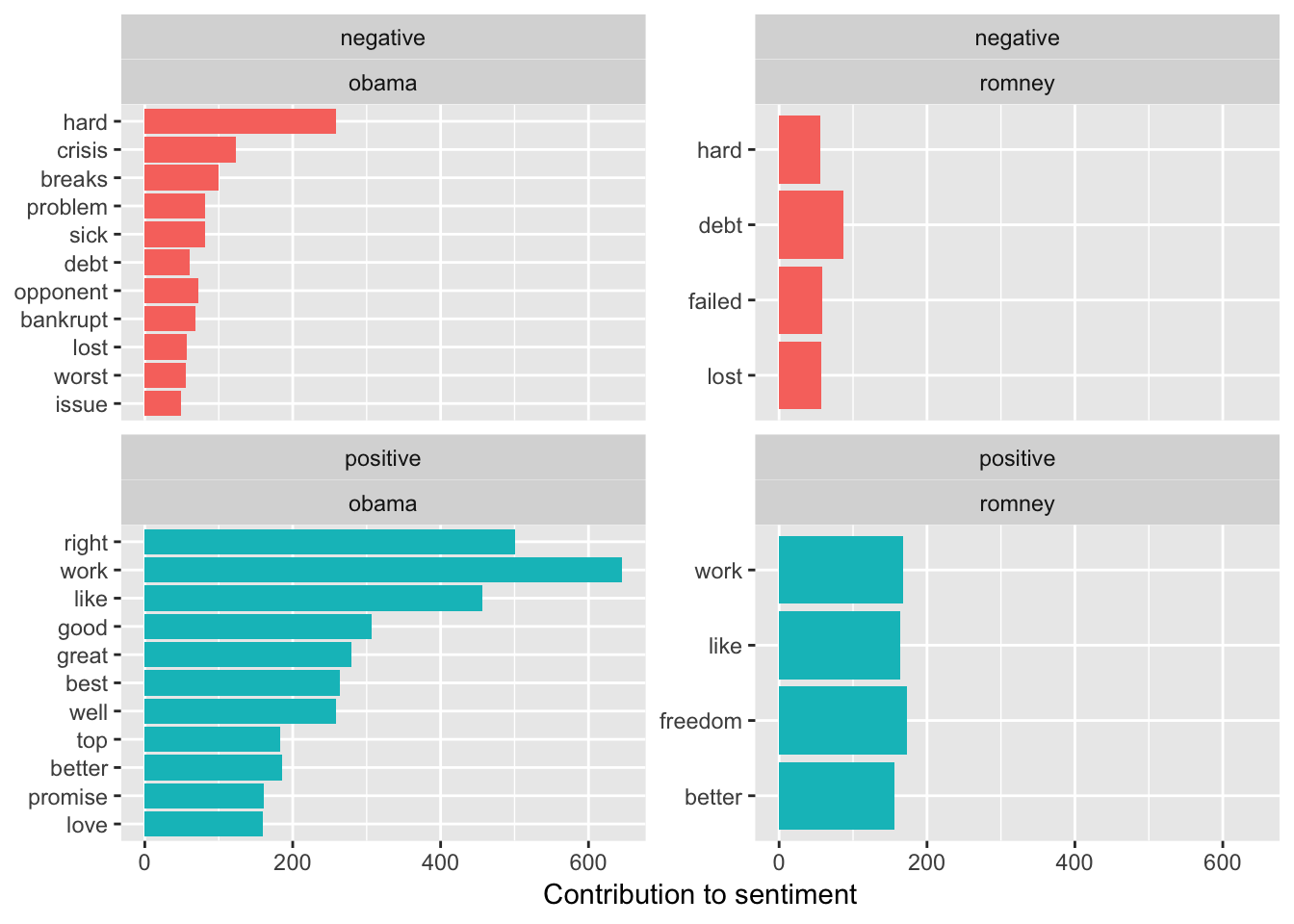
So if we look at a word cloud of combined sentiment across all speeches independently of candidate we see the following:
pal <- brewer.pal(8,"Dark2")
# plot the 50 most common words
bing_word_counts %>%
with(wordcloud(word, n, random.order = FALSE, max.words = 50, colors=pal))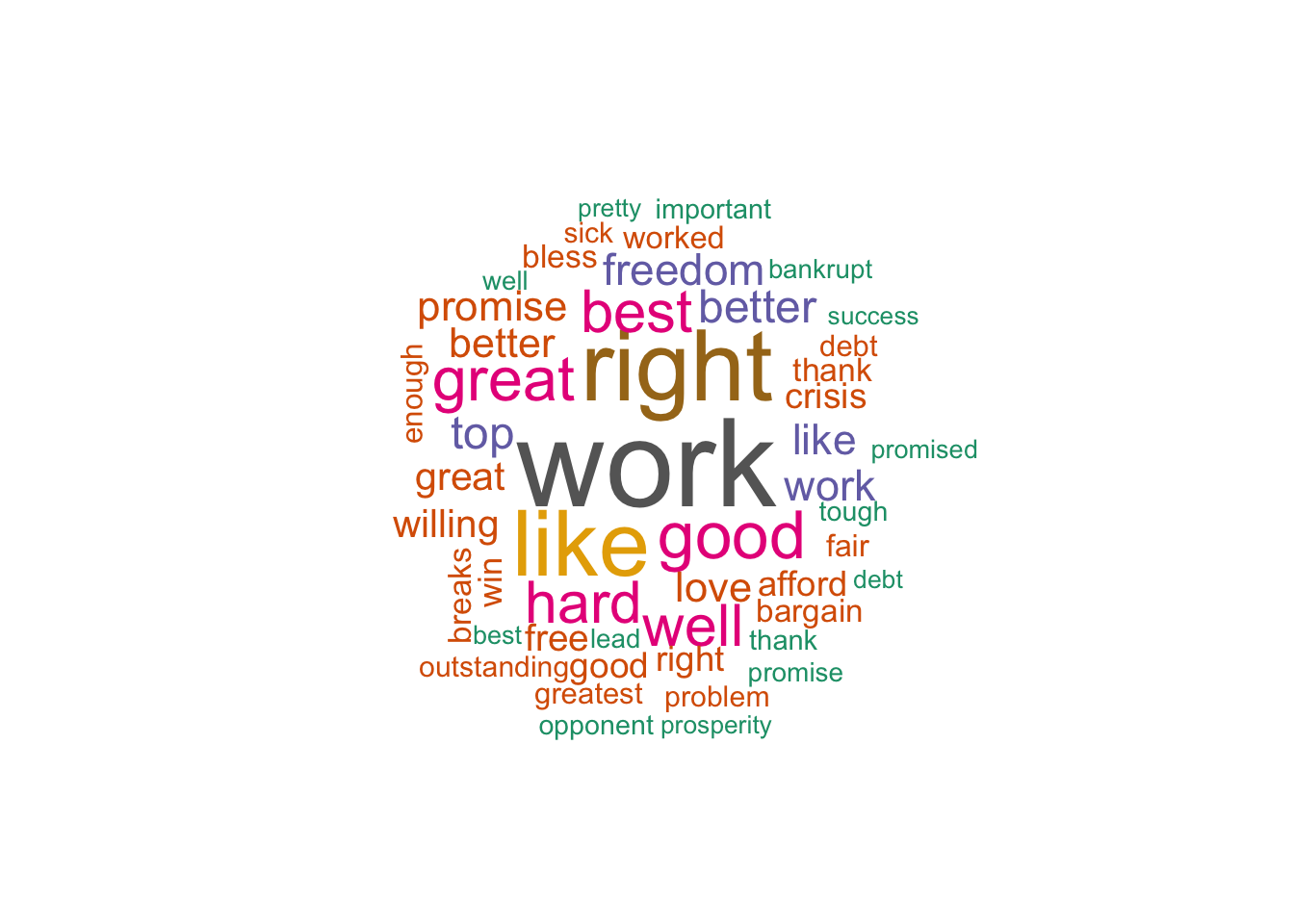
4.10.4 Comparison Cloud
So another thing we can do is to look at a comparison cloud that would give us a word cloud that presents a visualization of the most common postive and negative words. There is a function called comparison.cloud() that will accomplish this but it also requires us to do some conversion on our data frame.
library(reshape2)
combined_tidy_speech %>%
inner_join(get_sentiments("bing")) %>%
count(word, sentiment, sort = TRUE) %>%
acast(word ~ sentiment, value.var = "n", fill = 0) %>%
comparison.cloud(colors = c("gray20", "gray80"),
max.words = 100)## Joining, by = "word"
We could also look at this on a per candidate basis:
library(reshape2)
combined_tidy_speech %>%
inner_join(get_sentiments("bing")) %>%
filter(book=="romney") %>%
count(word, sentiment, sort = TRUE) %>%
acast(word ~ sentiment, value.var = "n", fill = 0) %>%
comparison.cloud(colors = c("gray20", "gray80"),
max.words = 100)## Joining, by = "word"## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): liberty could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): benefits could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): promises could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): recovery could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): innovation could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): greatness could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): powerful could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): destiny could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): proud could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): honor could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): commitment could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): confidence could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): courage could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): easy could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): protect could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): tough could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): extraordinary could not be fit on page. It will not be plotted.## Warning in comparison.cloud(., colors = c("gray20", "gray80"), max.words =
## 100): wonder could not be fit on page. It will not be plotted.